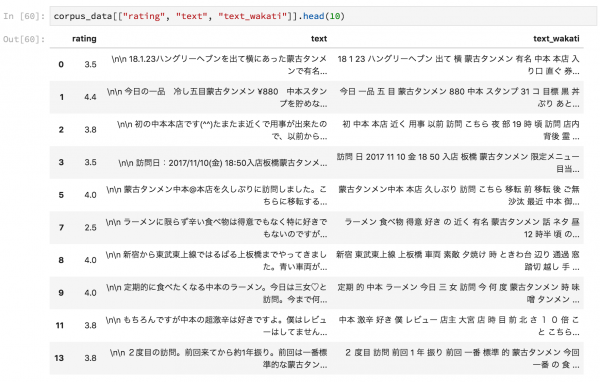
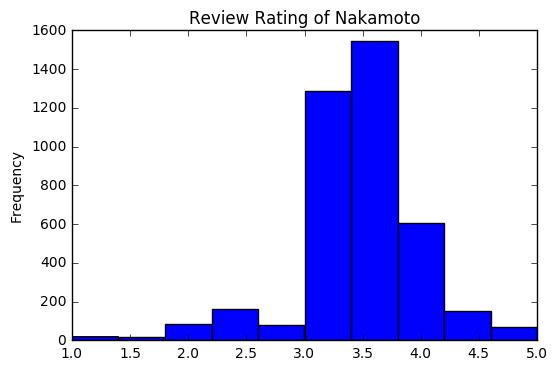
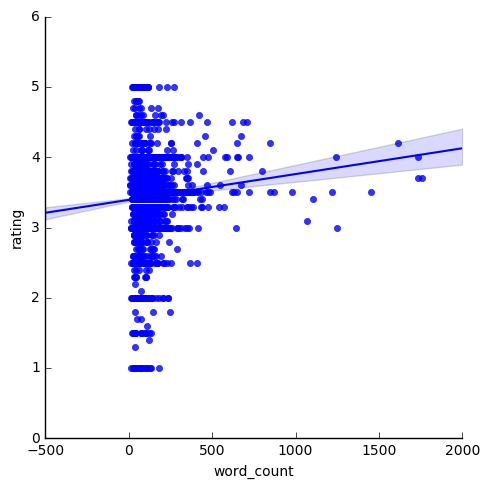
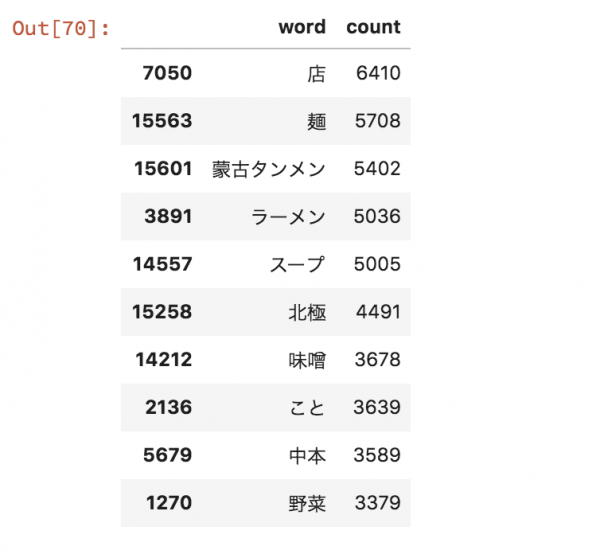
はじめに
2018年9月のテキストアナリティクスシンポジウムに行った際に、学習済みの分散表現で事前学習したモデルを使って分類してうまくいく事例が紹介されていました。
全てのタスクにおいてうまくいくとは思えませんが、試すコストはあまりかからないので試してみます。
2017年のテキストアナリティクスシンポジウムにおいても、メルカリやGunosyでは分散表現を用いた手法が一番精度が高いと言われていましたし、今年の会ではNLP系の学会でも分散表現はデファクトスタンダードになっているという話も伺いました。
2013~14年はLDAを使った研究が多かった気がしますが、徐々にシフトしていっているんですね。
これまで(Word2Vecを用いて蒙古タンメン中本の口コミ評価を予測してみる)は4000件程度の蒙古タンメン中本の口コミの情報を元に分散表現を手に入れていましたが、学習済みの分散表現を用いたアプローチも有効かもしれないと思い、試してみようと思います。
分類タスク
某グルメ口コミサイトの蒙古タンメン中本の口コミのテキストから、3.5点以上の評価かどうかを予測するタスクを扱います。
本当は、ポケモン図鑑の説明文から水やら炎やらのタイプを予測するとかをしたいのですが、あいにく手元にデータがないので、以前集めた蒙古タンメン中本の口コミを使います。(実は後日、ポケモン図鑑のデータを集めたのですが、平仮名にまみれたデータな上に、データ数も800件しかなかったので、どのみち厳しかったです。)
学習済み分散表現
Word2Vecなどで大量の文書をもとに学習させた分散表現のことを指します。
大規模コーパスで分散表現を手に入れる際は、数十GBにも相当するテキストデータを数時間かけて推定するので、学習済みのモデルは非常にありがたいです。(4年前に会社のPCで計算した際は、12時間くらいかかったこともありました。)
無料で提供してくださっている分散表現については、すでにこちらのブログで紹介されています。そこで紹介されているものに少し付け足すと、日本語の分散表現に関しては以下のようなものがあります。
- 白ヤギコーポレーションのモデル:Gensim
- 東北大学 乾・岡崎研究室のモデル:Gensim
- Facebookの学習済みFastTextモデル:Gensim
- NWJC から取得した単語の分散表現データ (nwjc2vec):Gensim
- NNLM embedding trained on Google News:TensorFlow
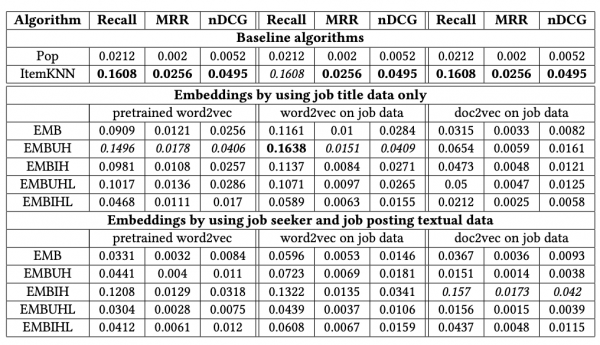
そこで、今回は各種学習済み分散表現と蒙古タンメン中本コーパスで求めた分散表現の文書分類の性能バトルをしてみたいと思います。
ただ、分散表現ではなく、単語の頻度をもとに特徴量を作ったものが一番精度が高いのですが、分散表現同士の比較でもってどの学習済み分散表現が中本の口コミ分類に役に立ちそうなのかを明らかにしようと思います。(本来は分析という観点から即でボツですが、見苦しくも比較していきます。)
前処理
前処理は以下の通りで、テキストデータを分かち書きして、数値や低頻度・高頻度語を除外しています。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 |
import pandas as pd # データの読み込み corpus_data = pd.read_pickle("nakamoto_corpus.pickle").reset_index(drop=True) import collections import MeCab import mojimoji from string import digits remove_digits = str.maketrans('', '', digits) tagger = MeCab.Tagger("-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd/") def nouns_extract(line): keyword=[] node = tagger.parseToNode(line).next while node: if node.feature.split(",")[0] == "名詞": keyword.append(node.surface) node = node.next keyword = str(keyword).replace("', '"," ") keyword = keyword.replace("\'","") keyword = keyword.replace("[","") keyword = keyword.replace("]","") return keyword #欠損データを除外する関数 def FilterNANData(dataset, column_name): result_drop_remove = copy.deepcopy(dataset) result_drop_remove = result_drop_remove[~result_drop_remove[column_name].isnull()].reset_index(drop=True) return result_drop_remove[column_name] #形態素解析して名詞のみを抽出し単語の頻度を集計して降順で返す関数 def NounceSum(wordlist): m = MeCab.Tagger("-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd/") noun_list = [] # 重複を含めた名詞のリスト for i in wordlist: for l in m.parse (i).splitlines(): try: if l != 'EOS' and l.split('\t')[1].split(',')[0] == '名詞': # EOSを除き名詞のみ抽出 noun_list.append(l.split('\t')[0]) # 見出し追加 except: pass noun_cnt = collections.Counter(noun_list) # 各名詞の数え上げ nouns_data = pd.DataFrame.from_dict(noun_cnt, orient='index').reset_index() nouns_data.columns = ['nouns', 'count'] nouns_data = nouns_data.sort_values(by=["count"], ascending=None) return nouns_data #ストップワードを取り除く def stop_word(documents): texts = [word for word in documents.lower().split() if word not in stoplist] texts = " ".join(texts) return texts #リストでもらったテキストからストップワードを取り除く def stop_word_tolist(documents): document_total = ' '.join(documents.tolist()) texts = [[word for word in document_total.lower().split() if word not in stoplist]] return texts #全角を半角にする corpus_data["text_fixed"] = list(map(lambda text: mojimoji.zen_to_han(text, kana=False) , corpus_data.text)) #数字を除外する corpus_data["text_fixed"] = list(map(lambda text: text.translate(remove_digits) , corpus_data.text_fixed)) #形態素解析する corpus_data["text_wakati"] = list(map(lambda text:nouns_extract(text) , corpus_data.text_fixed)) #単語の頻度の計算 term_freq = pd.DataFrame(NounceSum(FilterNANData(corpus_data, "text_fixed")).reset_index(drop=True)) term_freq["ratio"] = term_freq["count"]/term_freq["count"].sum() #不要語の除去(指定したものや、頻出のもの、頻度の低すぎるものを除外) stoplist = ["ーー", "HP", "http://", "https://"] stoplist2 = term_freq.query(' 10 > count | count > 1000 ').nouns.tolist() stoplist.extend(stoplist2) stoplist = set(stoplist) corpus_data["text_wakati_fixed"] = list(map(lambda text:stop_word(text) , corpus_data.text_wakati)) #3.5点以上であれば1そうでなければ0 corpus_data["label"] = np.where(corpus_data.rating >= 3.5, 1, 0) |
処理を施すとこのようなデータになります。

特徴量は、scikit-learnのCountVectorizerやTfidfVectorizer、分散表現の合計・平均・TF-IDFを求めたものを用意します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 |
from gensim.models.word2vec import Word2Vec from gensim.models import word2vec import matplotlib.pyplot as plt import seaborn as sns from tabulate import tabulate from collections import Counter, defaultdict from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.ensemble import ExtraTreesClassifier from sklearn.pipeline import Pipeline from sklearn.metrics import accuracy_score from sklearn.cross_validation import cross_val_score #単語の分散表現の合計値を求めるクラスの定義 class SumEmbeddingVectorizer(object): def __init__(self, word2vec): self.word2vec = word2vec self.dim = word2vec.values() self.dim = next(iter(self.dim)) self.dim = self.dim.size def fit(self, X, y): return self def transform(self, X): return np.array([ np.sum([self.word2vec[w] for w in words if w in self.word2vec] or [np.zeros(self.dim)], axis=0) for words in X ]) #単語の分散表現の平均値を求めるクラスの定義 class MeanEmbeddingVectorizer(object): def __init__(self, word2vec): self.word2vec = word2vec self.dim = word2vec.values() self.dim = next(iter(self.dim)) self.dim = self.dim.size def fit(self, X, y): return self def transform(self, X): return np.array([ np.mean([self.word2vec[w] for w in words if w in self.word2vec] or [np.zeros(self.dim)], axis=0) for words in X ]) #TF-IDFで重み付けした分散表現を求めるクラスの定義 class TfidfEmbeddingVectorizer(object): def __init__(self, word2vec): self.word2vec = word2vec self.word2weight = None self.dim = word2vec.values() self.dim = next(iter(self.dim)) self.dim = self.dim.size def fit(self, X, y): tfidf = TfidfVectorizer(analyzer=lambda x: x) tfidf.fit(X) max_idf = max(tfidf.idf_) self.word2weight = defaultdict( lambda: max_idf, [(w, tfidf.idf_[i]) for w, i in tfidf.vocabulary_.items()]) return self def transform(self, X): return np.array([ np.mean([self.word2vec[w] * self.word2weight[w] for w in words if w in self.word2vec] or [np.zeros(self.dim)], axis=0) for words in X ]) #入力変数と出力変数の指定 X, y = np.array(corpus_data.text_wakati_fixed), np.array(corpus_data.label) #gensimで読み込むための形式にする sentences = [token.split(" ") for token in corpus_data.text_wakati] |
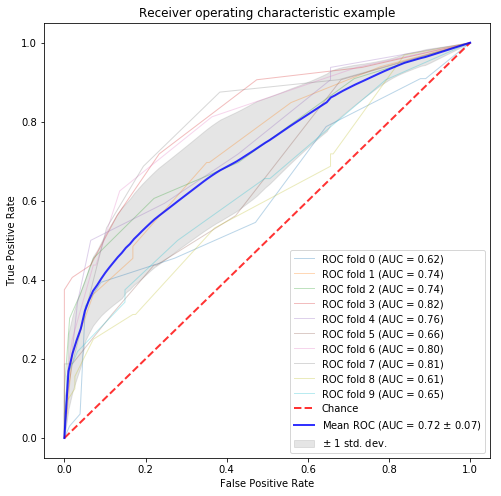
蒙古タンメン中本の口コミ4000件から作成した分散表現:Gensim
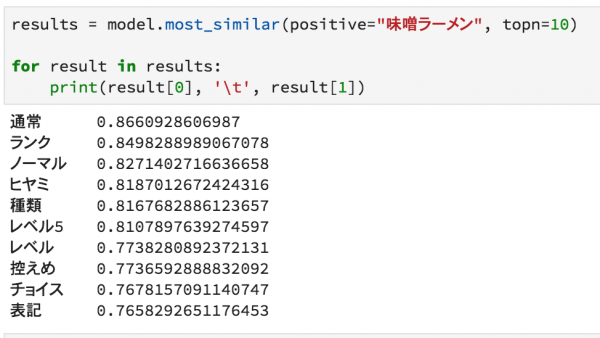
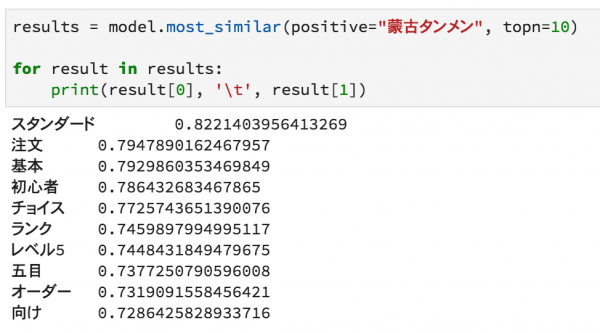
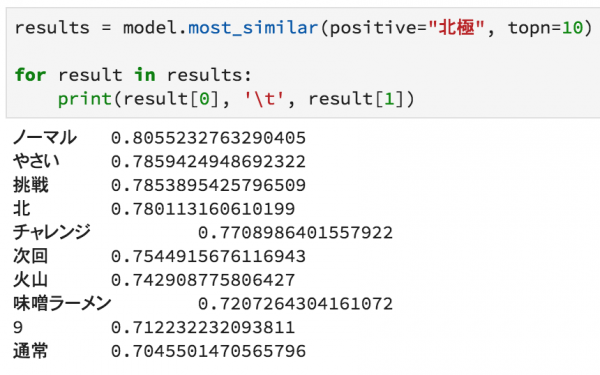
まず、以前のブログで紹介した蒙古タンメン中本の分散表現ですが、以下のように推定しています。
|
|
#Word2Vecを実行する。 model = Word2Vec(sentences, sg=1, size=50, window=5, min_count=5, workers=2, seed=123) #単語ごとの分散表現を手に入れる。 w2v = {w: vec for w, vec in zip(model.wv.index2word, model.wv.syn0)} |
Pipelineを用いてExtraTreesClassifierによる学習をします。特徴量は先程あげた、テキストベースのCountVectorizerやTfidfVectorizer、分散表現の合計・平均・TF-IDFで、評価指標はAUCのクロスバリデーションスコアとします。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
#ベースラインとなる既存手法のモデルの準備 #etree etree = Pipeline([("count_vectorizer",CountVectorizer(analyzer=lambda x: x)), ("extra trees", ExtraTreesClassifier(n_estimators=200))]) #etreeのTF-IDF版 etree_tfidf = Pipeline([("tfidf_vectorizer", TfidfVectorizer(analyzer=lambda x: x)), ("extra trees", ExtraTreesClassifier(n_estimators=200))]) #Word2Vecを特徴量としてExtraTreesによる分類器を準備する。 etree_w2v_sum = Pipeline([("word2vec vectorizer", SumEmbeddingVectorizer(w2v)), ("extra trees", ExtraTreesClassifier(n_estimators=200))]) etree_w2v = Pipeline([("word2vec vectorizer", MeanEmbeddingVectorizer(w2v)), ("extra trees", ExtraTreesClassifier(n_estimators=200))]) etree_w2v_tfidf = Pipeline([("word2vec vectorizer", TfidfEmbeddingVectorizer(w2v)), ("extra trees", ExtraTreesClassifier(n_estimators=200))]) #各モデルを実行し、クロスバリデーションスコアを計算し、出力させる。 all_models = [ ("etree",etree), ("etree_tfidf",etree_tfidf), ("w2v_sum", etree_w2v_sum), ("w2v", etree_w2v), ("w2v_tfidf", etree_w2v_tfidf) ] scores = sorted([(name, cross_val_score(model, X, y, cv=5, scoring = "roc_auc").mean()) for name, model in all_models], key = lambda x:x[0]) print(tabulate(scores, floatfmt=".4f", headers=("model", 'score'))) |
汗に関してコンテキストの似ている単語を抽出しています。
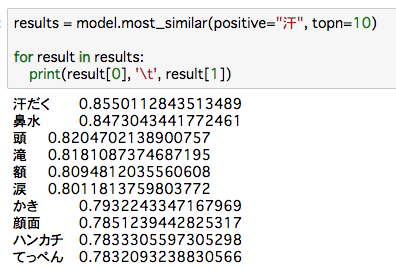
結果は、以下の通りで、分散表現を使わない方がAUCが高いです。ただ、w2v_tfidf(分散表現のTF-IDFを特徴量にしたもの)が分散表現の中でAUCが高いようです。今回はこの60.5%をベースラインに比較していこうと思います。
|
|
#中本の分散表現 model score ----------- ------- etree 0.6340 etree_tfidf 0.6499 w2v 0.5955 w2v_sum 0.5765 w2v_tfidf 0.6051 |
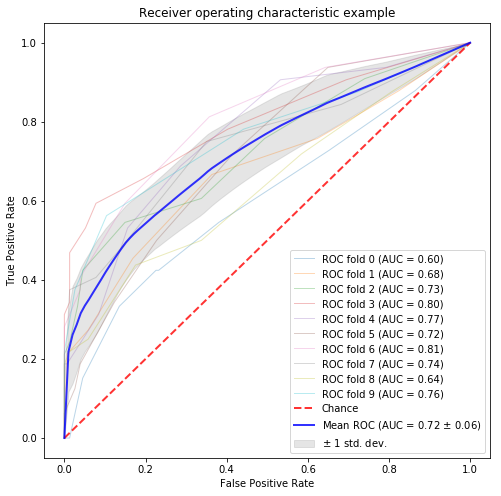
白ヤギコーポレーションのモデル:Gensim
こちらのリンク、「word2vecの学習済み日本語モデルを公開します」から、ダウンロードしてそのまま以下のコードでモデルを扱えます。
|
|
from gensim.models.word2vec import Word2Vec model_path = "latest-ja-word2vec-gensim-model/word2vec.gensim.model" model_shiroyagi = Word2Vec.load(model_path) w2v_shiroyagi = {w: vec for w, vec in zip(model_shiroyagi.wv.index2word, model_shiroyagi.wv.syn0)} |
汗の関連語を抽出していますが、中国の歴史の何かですか?可汗とかいう単語は聞いたことあるかも。
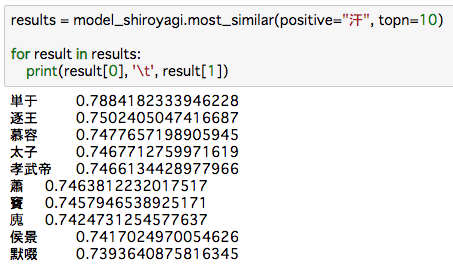
まずは白ヤギさんの分散表現をそのまま使って予測してみます。(コードは先程のものとほぼ重複するので省略しています。)
残念ながら、ベースラインの60.5%には至りませんでした。
|
|
#学習済み分散表現をそのまま用いたもの model score ----------- ------- w2v 0.6007 w2v_sum 0.5648 w2v_tfidf 0.5744 |
hogehoge.modelというフルモデル形式の場合は、再学習が可能です。詳しくはこちら(models.word2vec – Word2vec embeddings model)に書かれています。
|
|
train(sentences=None, corpus_file=None, total_examples=None, total_words=None, epochs=None, start_alpha=None, end_alpha=None, word_count=0, queue_factor=2, report_delay=1.0, compute_loss=False, callbacks=()) |
今回は、白ヤギさんの分散表現に対して、追加で蒙古タンメン中本のテキストを食わせて再学習させます。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
from gensim.models.word2vec import Word2Vec model_path = "latest-ja-word2vec-gensim-model/word2vec.gensim.model" model_shiroyagi = Word2Vec.load(model_path) #リストの重複を除く def remove_duplicates(l): return list(set(l)) #ユニーク単語のリストを作る flat_list = [item for sublist in sentences for item in sublist] model_shiroyagi.train(sentences=sentences, total_examples=len(sentences), total_words=len(remove_duplicates(flat_list)) , word_count= len(model_shiroyagi.wv.index2word), epochs=4) w2v_shiroyagi = {w: vec for w, vec in zip(model_shiroyagi.wv.index2word, model_shiroyagi.wv.syn0)} |
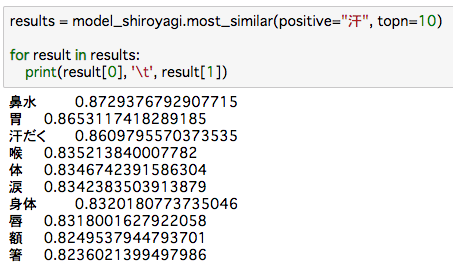
ベースラインの60.5%よりも下回り、さきほどの白ヤギさんのもともとの分散表現よりも下回りました。
|
|
model score ----------- ------- w2v 0.5731 w2v_sum 0.5515 w2v_tfidf 0.5774 |
再学習してもかえって精度が下がったりすることから、簡単に精度が出るわけではなさそうです。まぁ、理想はその適用領域での大量のテキストデータがあることで、Wikipediaを元に作成した分散表現に強く依存しても駄目なのだろうと思われます。
東北大学 乾・岡崎研究室のモデル:Gensim
日本語 Wikipedia エンティティベクトルからダウンロードした学習済み分散表現を用います。ダウンロード後は普通に「gzip -d file.txt.gz」みたいにターミナル上で解凍します。以下のコードを実行すればすぐに使うことができます。
ただし、KeyedVectors形式のものは白ヤギさんのように再学習ができません。(Why use KeyedVectors instead of a full model?)
|
|
import gensim.models.keyedvectors as word2vec_for_txt #学習済み分散表現の読み込み file_name = "jawiki.all_vectors.100d.txt" model_tonpei = word2vec_for_txt.Word2VecKeyedVectors.load_word2vec_format(file_name) #単語の分散表現の取得 w2v_tonpei = {w: vec for w, vec in zip(model_tonpei.wv.index2word, model_tonpei.wv.syn0)} |
汗の類似語に関しては、難しい単語が高めに出ているようです。
|
|
results = model_tonpei.most_similar(positive="汗", topn=10) for result in results: print(result[0], '\t', result[1]) 曷多 0.6981213092803955 拭い 0.6970207691192627 びっしょり 0.6847031116485596 垢 0.6723113059997559 喝 0.6681551933288574 裴羅 0.662636935710907 拭く 0.6584706902503967 洗う 0.6570826768875122 汚 0.6568220257759094 小便 0.6558053493499756 |
残念ながら、ベースラインの60.5%には至りませんでした。
|
|
model score ----------- ------- w2v 0.5901 w2v_sum 0.5478 w2v_tfidf 0.5786 |
Facebookの学習済みFastTextモデル:Gensim
FastTextはGoogleにいたTomas Mikolov氏がFacebookに転職されて作られた分散表現を求めるためのモデルです。Gensimでも呼び出せます。学習済みのものはこちらのGitHub(Pre-trained word vectors)にあるのですが、NEologdで形態素解析したものをベースに学習し公開されている方がいるとのことで、こちら(fastTextの学習済みモデルを公開しました)からダウンロードしたものを使わせていただきました。
|
|
file_name = "model.vec" model_fasttext = word2vec_for_txt.KeyedVectors.load_word2vec_format(file_name, binary=False) w2v_fasttext = {w: vec for w, vec in zip(model_fasttext.wv.index2word, model_fasttext.wv.syn0)} |
何だこれはレベルの結果が返ってきました。中国の歴史上の人物か何かなんでしょうか。
|
|
results = model_fasttext.most_similar(positive="汗", topn=10) for result in results: print(result[0], '\t', result[1]) 処羅可汗 0.6946621537208557 突利 0.6881076097488403 乙息記可汗 0.6672964096069336 都藍可汗 0.6537224650382996 頡利 0.6425886154174805 葉護可汗 0.6401641368865967 忠貞可汗 0.6395537257194519 撅 0.6240820288658142 默啜 0.6238714456558228 テュルギシュ 0.61381596326828 |
若干ですがベースラインの60.5%よりも良い結果が得られましたが、 誤差の範囲な気がします。
|
|
model score ----------- ------- w2v 0.6064 w2v_sum 0.5701 w2v_tfidf 0.5977 |
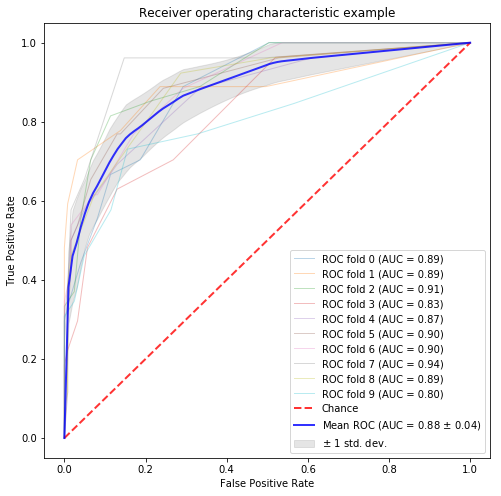
NWJC から取得した単語の分散表現データ (nwjc2vec):Gensim
国立国語研究所の収集されたテキストデータを元に学習した分散表現が提供されています。ただし、利用するためには申請する必要があります。申請が受理されたらこちら(NWJC から取得した単語の分散表現データ (nwjc2vec) を頒布)からダウンロードして使えます。
|
|
file_name = "nwjc_word_skip_300_8_25_0_1e4_6_1_0_15.txt.vec" model_bonten = word2vec_for_txt.KeyedVectors.load_word2vec_format(file_name, binary=False) w2v_bonten = {w: vec for w, vec in zip(model_bonten.wv.index2word, model_bonten.wv.syn0)} |
汗の関連語ですが、うまく関連付けれているように思われます。少なくとも中国史ぽくはありません。しかしながら、顔文字まで学習していたとは。
|
|
results = model_bonten.most_similar(positive="汗", topn=10) for result in results: print(result[0], '\t', result[1]) 大汗 0.8739632368087769 滝汗 0.7782824039459229 冷汗 0.7470424175262451 苦笑 0.7295455932617188  ̄∀ ̄;) 0.6987063884735107 笑 0.6849342584609985 冷や汗 0.6749577522277832 脂汗 0.6701192259788513 泣 0.6603907942771912 ダクダク 0.6596677303314209 |
ベースラインの60.5%よりも1%ポイントほど高い結果となりました。
|
|
model score ----------- ------- w2v 0.6163 w2v_sum 0.5839 w2v_tfidf 0.5916 |
NNLM embedding trained on Google News:TensorFlow
こちら(tensorflow-hubで超簡単にテキスト分類モデルが作成できる)で紹介されているように、GoogleがTensorFlowでGoogleニュースのテキストをもとに学習した分散表現が提供されています。
こちらのGitHub(NNLM embedding trained on Google News)から、Japaneseのnnlm-ja-dim50、nnlm-ja-dim50-with-normalizationなどが使えます。分散表現の説明についてはこちらのドキュメント(Token based text embedding trained on Japanese Google News 6B corpus.)にあります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
import tensorflow_hub as hub import tensorflow as tf from sklearn.utils import shuffle embed = hub.Module("https://tfhub.dev/google/nnlm-ja-dim50/1") df = copy.deepcopy(corpus_data) df['category_id'] = df.label.factorize()[0] df = shuffle(df) train_input_fn = tf.estimator.inputs.pandas_input_fn( df[:3500], df[:3500]["category_id"], num_epochs=None, shuffle=True) predict_test_input_fn = tf.estimator.inputs.pandas_input_fn( df[3500:], df[3500:]["category_id"], shuffle=False) embedded_text_feature_column = hub.text_embedding_column( key="text_wakati", module_spec="https://tfhub.dev/google/nnlm-ja-dim50/1") estimator = tf.estimator.DNNClassifier( hidden_units=[500, 100], feature_columns=[embedded_text_feature_column], n_classes=2, optimizer=tf.train.AdagradOptimizer(learning_rate=0.003)) estimator.train(input_fn=train_input_fn, steps=1000); test_eval_result = estimator.evaluate(input_fn=predict_test_input_fn) print("Test set accuracy: {accuracy}".format(**test_eval_result)) |
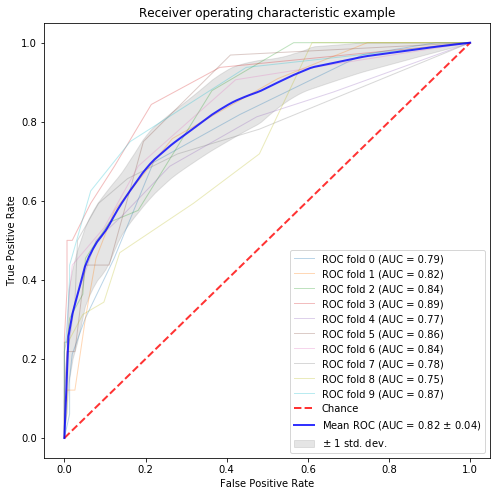
AUCが65%となっているものの、先程のsklearnでのクロスバリデーションのものとの比較ではないので、なんとも言えないですが、Googleニュースのデータだし結構精度が出そうな可能性を感じますね。
今後、TensorFlowでクロスバリデーションによるAUCスコアの出し方を調べてみて、順当に比較できるようにしたいです。(Kerasを使って計算している事例は見つけた。)
|
|
{'accuracy': 0.62835246, 'accuracy_baseline': 0.578544, 'auc': 0.6501204, 'auc_precision_recall': 0.577037, 'average_loss': 0.64989257, 'global_step': 1000, 'label/mean': 0.42145595, 'loss': 67.848785, 'precision': 0.5855263, 'prediction/mean': 0.4055166, 'recall': 0.40454546} |
比較
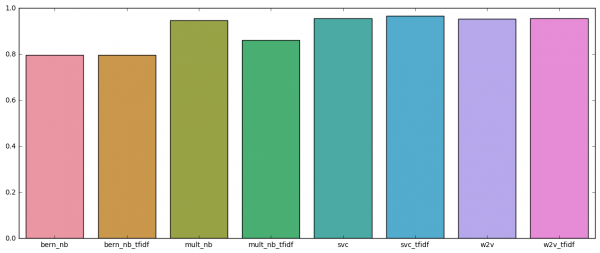
今回の分類タスクはそもそも分散表現では精度が出なかったのですが、学習済み分散表現の中で序列を作るとすると、梵天が一番良く、FastTextが少しだけ良かったです。
TensorFlowをほぼ業務で使わないので、Googleニュースの分散表現を今回の比較対象にできなかったのですが、後日比較できるようにしたいと思います。
あと、今回の口コミの点数を当てるタスクよりも、分散表現にとって相性がいいタスクがあるかもしれないので、今回の結果で諦めることなく色々と試して行きたいです。
おわりに
様々なシンポジウムなどでスタンダードとなってきた分散表現ですが、学習済み分散表現をそのまま使って分類問題で役に立つのかを見てきました。残念ながら、口コミの評価予測タスクにおいては全然効果がなさそうでした。ただ、分散表現の中でもタスクによって相性の良い学習済み分散表現がありそうです。
先程も述べたように、理想は大量のテキストデータで学習した分散表現を求め、それを予測に使うことなので大量のテキストデータを集めて再チャレンジしたいです。どれくらいのテキストデータがあれば十分なのかの規模感もわからないので、実践あるのみなんですかね。
参考情報
Word Embeddingだけで文書分類する
tensorflow-hubで超簡単にテキスト分類モデルが作成できる
Error: ”Word2vec’ object has no attribute index2word
Word2vec Tutorial Online training / Resuming training
Word Embeddingモデル再訪
Googleの事前学習済みモデルを手軽に利用出来るTensorFlow Hub
ゼロから作るDeep Learning ❷ ―自然言語処理編


 (
(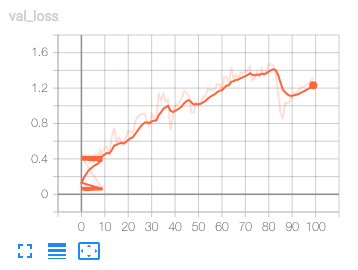 エポックに対してloglossが非常に荒れています。学習曲線としてはセオリー的にアウトなようです。一方で、検証のAUCはエポックに従って高まるようです。
エポックに対してloglossが非常に荒れています。学習曲線としてはセオリー的にアウトなようです。一方で、検証のAUCはエポックに従って高まるようです。
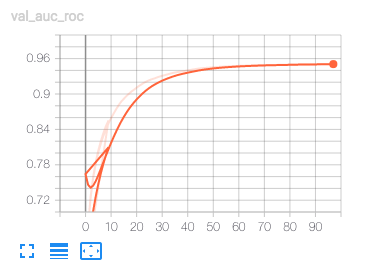 AUCは良くなっているけどloglossが増え続けている。loglossが下がらないと過学習している可能性が高いので、これは過学習しているだけなのだろう。
AUCは良くなっているけどloglossが増え続けている。loglossが下がらないと過学習している可能性が高いので、これは過学習しているだけなのだろう。