HDP(Hierarchical Dirichlet Process)いわゆる階層ディリクレ過程を実行できるモデルがPythonのGensimライブラリにあるという情報から、あまり実行例も見当たらないので、チャレンジしてみました。
HDP(Hierarchical Dirichlet Process)
HDP(Hierarchical Dirichlet Process)は文書集合全体のトピック数と文書ごとのトピック数の推定を行うことができる手法で、中華料理店フランチャイズという仕組みを用いています。通常のLDAなどでは、分析者が任意のトピック数を決める必要がありましたが、与えられたデータからその数を推定するため、その必要がないというのがHDPを使うことの利点であると思われます。
実行までの流れ
ざっくりですが、
・コーパスの準備・文書の分かち書き(名詞のみ)
・HDPの実行
という流れです。
ちなみに実行環境は
MacBook Pro
OS X Yosemite 10.10.5
2.6 GHz Intel Core i5
メモリ8GBです。
コーパスの準備
今回は、以前手に入れた某辞典サイトのクラシック音楽情報1800件のテキストデータ(1行に1件分の文字列が入っているデータで16MBくらい)があるので、それをコーパスとして使います。参考情報として挙げているブログの助けを借りて、文書単位でMeCabにより形態素解析で分かち書きした結果から、意味を持ちやすい品詞として、「名詞」に該当するもののみを結果として返す以下のPythonスクリプトを用いました。結果はtmep.txtとして出力されます。もっと良いやり方があると思いますが、目的は達成できると思います。ちなみに、MeCab Neologd(ネオログディー)という、固有名詞などに強いシステム辞書を活用してみたかったので、その利用を前提として書いています。MeCab Neologd(ネオログディー)のインストール関連の情報は参考情報にありますので、チャレンジしてみてください。(OSXかUbuntuの方が進めやすいと思います。)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
#coding:utf-8 import MeCab import sys sys.stdout = open("tmep.txt","w") def extractKeyword(text): u"""textを形態素解析して、名詞のみのリストを返す""" tagger = MeCab.Tagger(' -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd') #デフォルトの辞書を用いる場合は tagger = MeCab.Tagger('') encoded_text = text.encode('utf-8') node = tagger.parseToNode(encoded_text).next keywords = [] while node: if node.feature.split(",")[0] == "名詞": keywords.append(node.surface) node = node.next return keywords def splitDocument(documents): u"""文章集合を受け取り、名詞のみ空白区切りの文章にして返す""" splitted_documents = [] for d in documents: keywords = extractKeyword(d) splitted_documents.append(' '.join(keywords)) return splitted_documents if __name__ == "__main__": document_text = open('music_text.txt') raw_documents = document_text.readlines() # 空白区切りの文字列を入れるリスト splitted_documents = splitDocument(raw_documents) for d in splitted_documents: print d print '' sys.stdout = sys.__stdout__ |
こちらのスクリプトをターミナルで実行します。(解析するディレクトリ下で実施しています。)
|
1 |
python MeCab_Norm_Extract.py music_text.txt > music_text_wakati_norm_neo.txt |
HDPの実行
以下のPythonスクリプトで実行しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# -*- coding: utf-8 -*- from gensim import models,corpora import pandas #ドキュメントからLDAなどの分析用コーパスを作成 corpus = gensim.corpora.TextCorpus('music_text_wakati_norm_neo') #HDPモデルの推定 model = models.hdpmodel.HdpModel( corpus, id2word=corpus.dictionary, alpha=0.1) #各文書のトピックの重みを保存 topics = [model[c] for c in corpus] print(topics[0]) #各トピックごとの単語の抽出(topicsの引数を-1にすることで、ありったけのトピックを結果として返してくれます。) model.print_topics(topics=-1, topn=10) #文書ごとに割り当てられたトピックの確率をCSVで出力 mixture = [dict(model[x]) for x in corpus] pandas.DataFrame(mixture).to_csv("topic_for_corpus.csv") #トピックごとの上位10語をCSVで出力 topicdata =model.print_topics(topics=-1, topn=10) pandas.DataFrame(topicdata).to_csv("topic_detail.csv") |
HDPの結果について
topic_detail.csvの結果を見たところ、トピックの数が150個もあって、「本当にトピックの数を自動で決めれているのかなぁ」と不安に思ったのですが、実際に各文書に割り当てられているトピックの数は、先ほど出力したtopic_for_corpus.csvで見ると60個でした。そのため、今回、HDPに従って決まったトピック数は60ということになります。さらに不安に思ったので、Stack Over Flowで調べていたんですが、トピックは150個出るけど確率が割り振られていないはずと回答されていました。( Hierarchical Dirichlet Process Gensim topic number independent of corpus size )
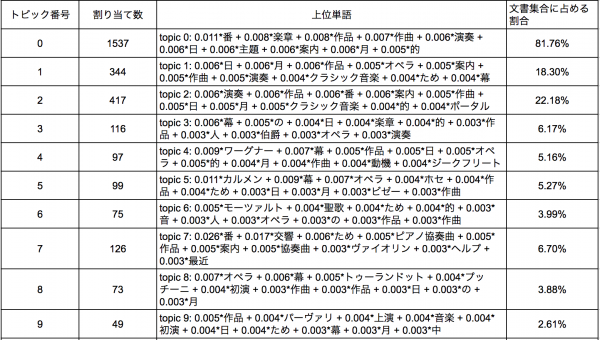
出現頻度の高い上位10のトピックは以下の通りです。
|
1 2 3 4 5 6 7 8 9 10 11 |
['topic 0: 0.011*番 + 0.008*楽章 + 0.008*作品 + 0.007*作曲 + 0.006*演奏 + 0.006*日 + 0.006*主題 + 0.006*案内 + 0.006*月 + 0.005*的', 'topic 1: 0.006*日 + 0.006*月 + 0.006*作品 + 0.005*オペラ + 0.005*案内 + 0.005*作曲 + 0.005*演奏 + 0.004*クラシック音楽 + 0.004*ため + 0.004*幕', 'topic 2: 0.006*演奏 + 0.006*作品 + 0.006*番 + 0.006*案内 + 0.005*作曲 + 0.005*日 + 0.005*月 + 0.005*クラシック音楽 + 0.004*的 + 0.004*ポータル', 'topic 3: 0.006*幕 + 0.005*の + 0.004*日 + 0.004*楽章 + 0.004*的 + 0.003*作品 + 0.003*人 + 0.003*伯爵 + 0.003*オペラ + 0.003*演奏', 'topic 4: 0.009*ワーグナー + 0.007*幕 + 0.005*作品 + 0.005*日 + 0.005*オペラ + 0.005*的 + 0.004*月 + 0.004*作曲 + 0.004*動機 + 0.004*ジークフリート', 'topic 5: 0.011*カルメン + 0.009*幕 + 0.007*オペラ + 0.004*ホセ + 0.004*作品 + 0.004*ため + 0.003*日 + 0.003*月 + 0.003*ビゼー + 0.003*作曲', 'topic 6: 0.005*モーツァルト + 0.004*聖歌 + 0.004*ため + 0.004*的 + 0.003*音 + 0.003*人 + 0.003*オペラ + 0.003*の + 0.003*作品 + 0.003*作曲', 'topic 7: 0.026*番 + 0.017*交響 + 0.006*ため + 0.005*ピアノ協奏曲 + 0.005*作品 + 0.005*案内 + 0.005*協奏曲 + 0.003*ヴァイオリン + 0.003*ヘルプ + 0.003*最近', 'topic 8: 0.007*オペラ + 0.006*幕 + 0.005*トゥーランドット + 0.004*プッチーニ + 0.004*初演 + 0.003*作曲 + 0.003*作品 + 0.003*日 + 0.003*の + 0.003*月', 'topic 9: 0.005*作品 + 0.004*パーヴァリ + 0.004*上演 + 0.004*音楽 + 0.004*初演 + 0.004*日 + 0.004*ため + 0.003*幕 + 0.003*月 + 0.003*中', 'topic 10: 0.007*トスカ + 0.006*幕 + 0.005*オペラ + 0.005*作品 + 0.004*彼 + 0.004*マノン + 0.003*カヴァラドッシ + 0.003*の + 0.003*スカ + 0.003*ルピア'] |
加えて、トピックごとに文書に割り当てられた数を集計してみましたが、topic0が圧倒的に多く、コーパスの特性上、含まれやすい情報がここに集まっているのではないかと思います。幅広いテーマを抽出できるかと期待していたのですが、やたらと個別具体的な「トゥーランドット」や「ワーグナー」や「カルメン」などがトピックの上位単語に上がってきています。実行方法を間違えているかもしれないし、パラメータチューニングなどをもっと頑張れば、幅広いトピックを得ることができるかもしれないので、今後の課題としたいです。
参考情報
・トピックモデルについて
machine_learning_python/topic.md at master · poiuiop/machine_learning_python · GitHub
・HDP関連
models.hdpmodel – Hierarchical Dirichlet Process
Online Variational Inference for the Hierarchical Dirichlet Process
・MeCab関連
mecab-ipadic-NEologd : Neologism dictionary for MeCab
形態素解析器 MeCab の新語・固有表現辞書 mecab-ipadic-NEologd のご紹介
テキストマイニングの前処理。名詞抽出、ストップワード除去、珍しい単語の除去
・Python関連
データ分析をやりたいエンジニアにおすすめ!Pythonの入門スライド13選