R Advent Calendar 2017の11日目を担当するMr_Sakaueです。
今回はrvestパッケージを用いて、友人がハマっているポケモンの情報を集めてみようと思います。
もっとも、業務でWebスクレイピングする際はPythonでBeautifulSoupやSeleniumを使うことがほとんどなのですが、たまにはRでやってみようと思います。
目次
・やりたいこと
・rvestについて
・データの取得と集計と可視化と分析
・まとめ
・参考情報
やりたいこと
今回はポケモンたちのデータを集めた上で、以下の内容を行いたいと思います。
- ポケモンのサイトから種族値を取得
- ポケモンの種族値を標準化して再度ランキング
- ポケモンのレア度や経験値に関する情報を取得
- レア度や経験値と相関しそうな種族値を探る
今回扱った全てのコードはこちらに載せております。
https://github.com/KamonohashiPerry/r_advent_calendar_2017/tree/master
※種族値はゲームにおける隠しパラメータとして設定されている、ポケモンの能力値とされている。
rvestについて
rvestはRでWebスクレイピングを簡単に行えるパッケージです。ここでの説明は不要に思われますが、今回はread_html()、html_nodes()、html_text()、html_attr()の4つ関数を用いました。
基本的に以下の3ステップでWebの情報を取得することができます。
- STEP1
read_html()でHTMLからソースコードを取得する。(Pythonでいう、requestとBeautifulSoup) - STEP2
html_nodes()でソースコードから指定した要素を抽出する。(PythonでいうところのfindAll) - STEP3
html_text()やhtml_attr()で抽出した要素からテキストやリンクを抽出する。(Pythonでいうところのget(‘href’)など)
データの取得と集計と可視化
検索エンジンで検索してだいたい1位のサイトがあったので、そちらのWebサイトに載っているポケモンの種族値の一覧をスクレイピング対象とさせていただきます。
- ポケモンのサイトから種族値を取得
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
library(rvest) library(tidyverse) library(magrittr) library(reshape2) # htmlソースコードを読み込む pokemon_ranking <- read_html("https://yakkun.com/sm/status_list.htm") # class属性がtdタグのノードを抽出 node_extracted <- html_nodes(pokemon_ranking, "td") # ノードからテキストを抽出して行列にして、名前以外を数値に型変換して、変数名を変更する。 pokemon_data <- data.frame(matrix(html_text(node_extracted), ncol = 9,byrow = TRUE),stringsAsFactors = FALSE) %>% set_colnames(c('id', 'name', 'Hit_Points', 'Attack', 'Defense', 'Special_Attack', 'Special_Defense', 'Speed', 'Total')) %>% mutate_at(vars(-name), as.numeric) # ポケモン別のページを取得するためのURLの取得 pokemon_link <- pokemon_ranking %>% html_nodes("td") %>% html_nodes('a') %>% html_attr('href') pokemon_link <- gsub(x = pokemon_link, pattern = './zukan', replacement = "https://yakkun.com/sm/zukan") # ポケモン別のURLを先ほどのデータに加える pokemon_data <- pokemon_data %>% mutate(url = pokemon_link) |
以上のコードを実行すれば、こんな感じでポケモンの種族値一覧を得る事ができます。
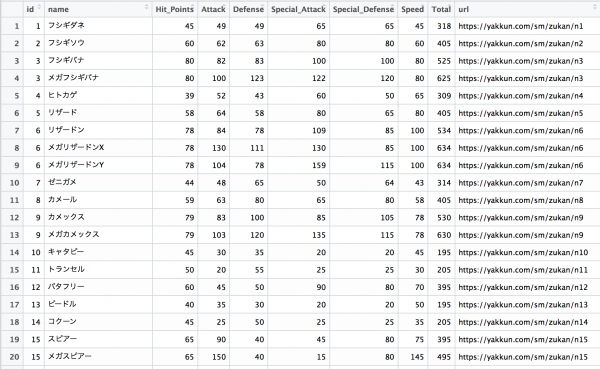
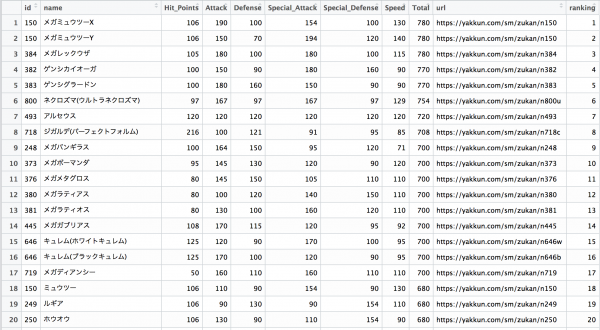
とりあえず、種族値合計(Total Tribal Value 以下、TTV)のランキングの上位を確認してみます。知らないんですが、メガミュウツーとかいうイカつそうなポケモンが上位にいるようです。昭和の世代には縁のなさそうなポケモンばかりですねぇ。
■TTVランキング
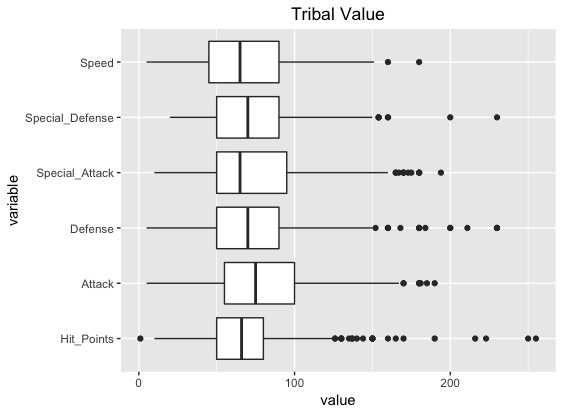
取得した種族値を項目別に集計したり、Boxプロットを描いてみます。どうやら、攻撃の平均が高く、ヒットポイントや素早さの平均は低いようです。
|
1 2 3 4 5 6 7 8 9 10 |
# 集計 pokemon_data_melt <- melt(pokemon_data %>% select(-url), id.vars = 'name') pokemon_data_melt %>% group_by(variable) %>% summarise(mean = mean(value), median = median(value), sd = sd(value), max = max(value), min = min(value), cv = sd/mean) |
■種族値のサマリー

|
1 2 3 4 5 |
# Box-Plotを描く ggplot(data = pokemon_data_melt %>% filter(!(variable %in% c('id','Total'))), aes(x = variable, y = value)) + geom_boxplot() + ggtitle("Tribal Value") + theme(plot.title = element_text(hjust = 0.5)) + coord_flip() |
■種族値のBoxプロット
- ポケモンの種族値を標準化して再度ランキング
さて、攻撃の平均が高かったり、ヒットポイントと素早さの平均が低かったりしたので、各々の項目を標準化した上で、再度ランキングを作ってみたいと思います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
pokemon_data_standardized <- pokemon_data pokemon_data_standardized <- pokemon_data_standardized %>% mutate_at(vars(Hit_Points, Attack, Defense, Special_Attack, Special_Defense, Speed),funs(scale(.) %>% as.vector)) pokemon_data_standardized <- pokemon_data_standardized %>% mutate(Total = rowSums(select(.,c(3:8)))) pokemon_data_standardized_ranking <- pokemon_data_standardized %>% arrange(desc(Total)) pokemon_data_standardized_ranking <- pokemon_data_standardized_ranking %>% mutate(standardized_ranking = 1:n()) pokemon_data_standardized_melt <- melt(pokemon_data_standardized %>% select(-url), id.vars = 'name') pokemon_data_standardized_melt %>% group_by(variable) %>% summarise(mean = mean(value), median = median(value), sd = sd(value), max = max(value), min = min(value), cv = sd/mean) |
■標準化した種族値のサマリー
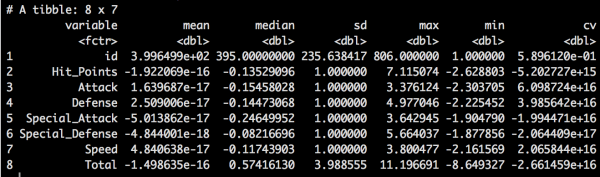
平均0、分散1にできているようです。
|
1 2 3 4 5 |
# Box-Plotを描く ggplot(data = pokemon_data_standardized_melt %>% filter(!(variable %in% c('id','Total','Total_standardized'))), aes(x = variable, y = value)) + geom_boxplot() + ggtitle("Tribal Value") + theme(plot.title = element_text(hjust = 0.5)) + coord_flip() |
■標準化した種族値のBoxプロット

他よりも低かったヒットポイントと、高かった攻撃がならされていることが確認できます。
■標準化前後でのTTVランキングのギャップが大きかったものをピックアップ
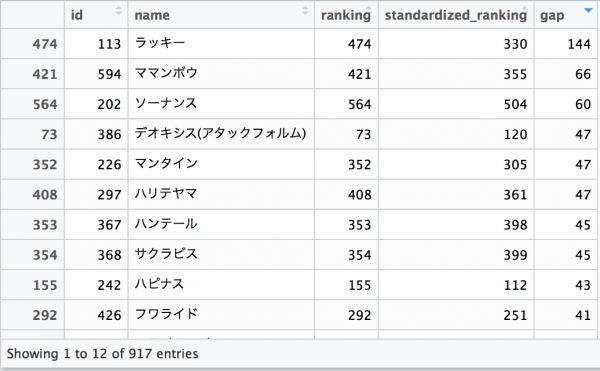
ラッキーが144位ほど出世しています。攻撃が低く、ヒットポイントの高いラッキーが標準化により優遇されるようになったと考える事ができます。ポケモン大会の上位ランカーである後輩社員もラッキーは手強いですと言っていたのでまんざらでもないのでしょう。
- ポケモンのレア度や経験値に関する情報を取得
今回のサイトには、個別にポケモン別のページが用意されており、そちらから、ゲットしやすさや経験値に関する情報を抽出します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
# ポケモンの個別ページの情報を格納するデータフレームの作成 pokemon_detail_database <- data.frame(url = as.character(), name = as.character(), rarity = as.integer(), experience = as.integer()) # ポケモン別のURLからゲットしやすさなどを抽出するための関数 Pokemon_Detail_Get <- function(pokemon_url){ pokemon_detail <- read_html(pokemon_url) # XPathで名前とゲットしやすさと経験値タイプを取得 node_extracted_pokemon_name <- pokemon_detail %>% html_nodes(xpath="//tr[1]") %>% html_text() node_extracted_pokemon_name <- node_extracted_pokemon_name[1] node_extracted_pokemon_get <- pokemon_detail %>% html_nodes(xpath="//tr[24]/td[2]") %>% html_text() node_extracted_pokemon_get <- as.integer(gsub(x = node_extracted_pokemon_get[1], pattern = "\u00A0", replacement = "")) node_extracted_pokemon_exp <- pokemon_detail %>% html_nodes(xpath="//tr[26]/td[2]") %>% html_text() node_extracted_pokemon_exp <- as.integer(gsub(x = node_extracted_pokemon_exp[1], pattern = "万", replacement = "0000")) pokemon_detail_data <- data.frame(url = pokemon_url, name = node_extracted_pokemon_name, rarity = node_extracted_pokemon_get, experience = node_extracted_pokemon_exp) return(pokemon_detail_data) Sys.sleep(30) } # ポケモン別のページをスクレイピングする pokemon_detail_database <- map_dfr(pokemon_link , ~Pokemon_Detail_Get(.)) # 重複したURLを削除する pokemon_detail_database <- pokemon_detail_database %>% distinct(url, .keep_all = TRUE) # 種族値のデータとゲットしやすさなどのデータを繋ぎこむ pokemon_data_standardized <- pokemon_data_standardized %>% left_join(pokemon_detail_database %>% select(-name), by ="url") |
以上のコードを実行すれば、やや時間がかかりますが、全ポケモンのゲットしやすさや経験値のデータを抽出する事ができます。それらの情報がゲットできたら、まずは可視化します。
|
1 2 3 4 5 |
# ゲットしやすさのヒストグラム ggplot(data = pokemon_data_standardized, aes(x = rarity)) + geom_histogram() # 経験値のヒストグラム ggplot(data = pokemon_data_standardized, aes(x = experience)) + geom_histogram() |
■ゲットしやすさのヒストグラム
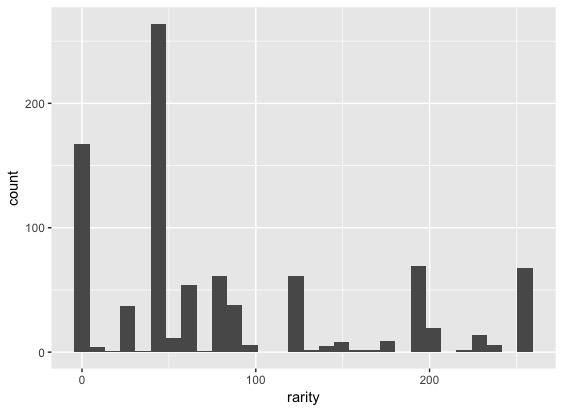
ゲットのしやすさは、小さいほど捕まえる難易度が高くなっています。難易度の高いポケモンである0が多過ぎるので、このデータは欠損値が0になっているのではないかと疑われます。
■経験値のヒストグラム
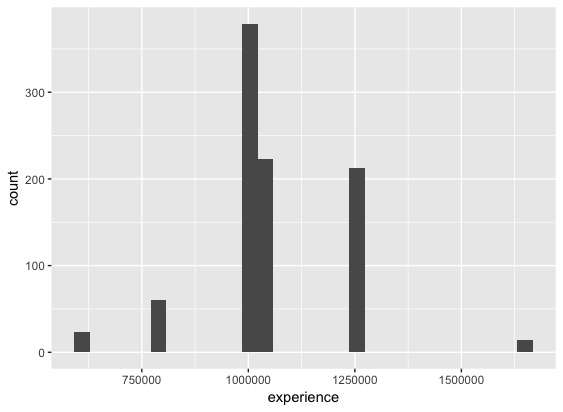
経験値は、レベル100になるまでに要する経験値をさしています。ほとんどが100万程度となっているようです。
■ゲットしやすさと標準化TTVの散布図
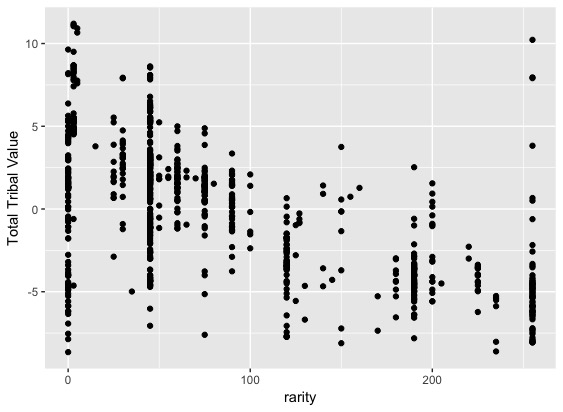
やはり、ゲットしやすさに関してはデータに不備があるようで、コラッタ(アローラの姿)のような雑魚ポケのゲットのしやすさが0だったり、伝説のポケモンであるネクロズマが255だったりします。ただ、上限と下限のデータを間引けば右下がりの傾向が見られそうです。
■経験値と標準化TTVの散布図
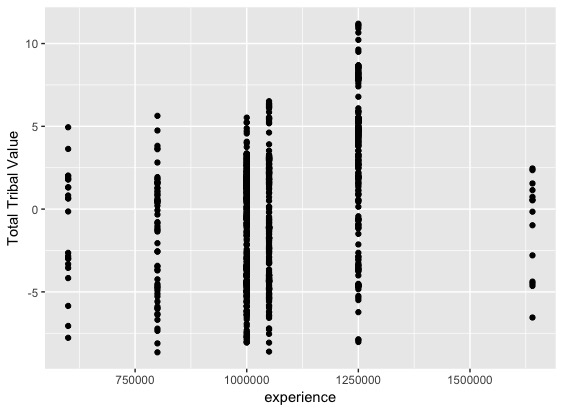
経験値が多く必要にも関わらず、TTVが低い集団があります。どうやらこの集団に属するのは、「キノガッサ」・「マクノシタ」・「イルミーゼ」・「ゴクリン」・「シザリガー」などで、一回しか進化しないポケモンのようです。これらのポケモンは育てにくく、TTVの低い、コスパの悪そうなポケモンと考えることができるのではないでしょうか。(技や特性によってはバリューあるかもしれませんが。)
- レア度や経験値と相関しそうな種族値を探る
先ほどのレア度に関しては、データがおかしそうだったので、レア度0と255に関しては除外してみます。
|
1 2 3 4 5 6 |
# おかしそうなレア度0と255のデータを除外する。 pokemon_data_standardized_filtered <- pokemon_data_standardized %>% filter(rarity > 0, rarity < 255) # ゲットのしやすさと標準化TTV ggplot(data = pokemon_data_standardized_filtered, aes(x = rarity, y = Total)) + geom_point() + ylab('Total Tribal Value') |
■ゲットしやすさと標準化TTVの散布図
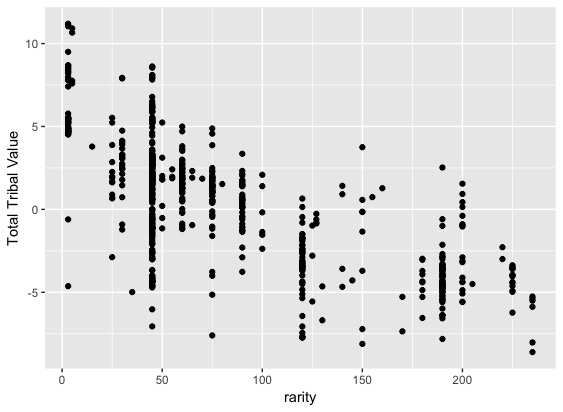
やはり除外する事で、理想的な右下がりの傾向を示す散布図が得られたと思います。
さて、各種族値がレア度にどれだけ相関しているのかを分析したいのですが、その前にレア度を表す二項変数を作成します。
■ゲットしやすさが50以下であれば1、それ以外を0にする変数を作成
|
1 |
pokemon_data_standardized_filtered <- pokemon_data_standardized_filtered %>% mutate(y = ifelse(rarity <= 50, 1, 0)) |
続いて、各種族値を説明変数として、レア度を目的変数としたロジスティック回帰モデルの推定をrstanで実行させます。
■stanコード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
data { int N; real Hit_Points[N]; real Attack[N]; real Defense[N]; real Special_Attack[N]; real Special_Defense[N]; real Speed[N]; int<lower=0, upper=1> Y[N]; } parameters { real b[7]; } model { for (n in 1:N) Y[n] ~ bernoulli_logit(b[1] + b[2]*Hit_Points[n] + b[3]*Attack[n] + b[4]*Defense[n] + b[5]*Special_Attack[n] + b[6]*Special_Defense[n] + b[7]*Speed[n]); } |
■rstanでロジスティック回帰を行い、推定結果を可視化するコード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
library(rstan) N <- nrow(pokemon_data_standardized_filtered) data <- list(N = N, Hit_Points = pokemon_data_standardized_filtered$Hit_Points, Attack = pokemon_data_standardized_filtered$Attack, Defense = pokemon_data_standardized_filtered$Defense, Special_Attack = pokemon_data_standardized_filtered$Special_Attack, Special_Defense = pokemon_data_standardized_filtered$Special_Defense, Speed = pokemon_data_standardized_filtered$Speed, Y = pokemon_data_standardized_filtered$y) fit <- stan(file = 'logistic_regression.stan', data = data, seed = 1234) summary(fit) traceplot(fit) source('common.R') ms <- rstan::extract(fit) N_mcmc <- length(ms$lp__) param_names <- c('mcmc', paste0('b', 1:7)) d_est <- data.frame(1:N_mcmc, ms$b) colnames(d_est) <- param_names d_qua <- data.frame.quantile.mcmc(x=param_names[-1], y_mcmc=d_est[,-1]) d_melt <- reshape2::melt(d_est, id=c('mcmc'), variable.name='X') d_melt$X <- factor(d_melt$X, levels=rev(levels(d_melt$X))) p <- ggplot() p <- p + theme_bw(base_size=18) p <- p + coord_flip() p <- p + geom_violin(data=d_melt, aes(x=X, y=value), fill='white', color='grey80', size=2, alpha=0.3, scale='width') p <- p + geom_pointrange(data=d_qua, aes(x=X, y=p50, ymin=p2.5, ymax=p97.5), size=1) p <- p + labs(x='parameter', y='value') p <- p + scale_y_continuous(breaks=seq(from=-2, to=6, by=2)) p |
■MCMCのシミュレーション結果のトレースプロット

どうやら収束してそうです。
■ロジスティック回帰の推定結果

見にくいので、推定結果を松浦さんの「StanとRでベイズ統計モデリング」にあるコードを用いて可視化します。
■推定結果の可視化
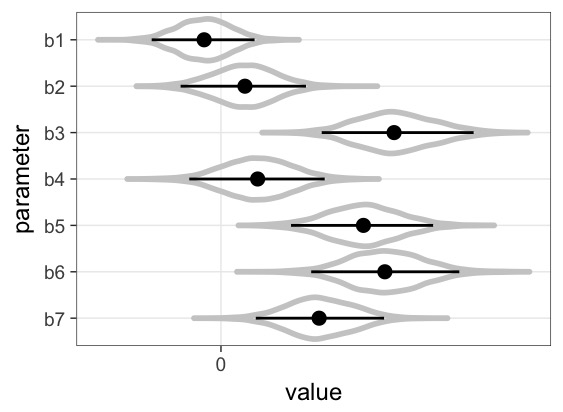
どうやら、0を含まない係数について見てみると、b3(攻撃)、b5(特殊攻撃)、b6(特殊防御)が高いほど、レア度が増す傾向があるようです。珍しいポケモンは攻撃が強いという傾向があると言えるのではないでしょうか。
まとめ
- rvestは簡単にスクレイピングできて便利。
- ポケモンデータは色々整備されてそうで今後も分析したら面白そう。
- 珍しいポケモンは「攻撃」、「特殊攻撃」、「特殊防御」が高い傾向がある。
- 経験値が必要なのにTTVの低い、コスパの悪そうなポケモンたちがいる。
それでは、どうか良い年末をお過ごし下さい!
メリークリスマス!
参考情報
データサイエンティストのための最新知識と実践 Rではじめよう! [モダン]なデータ分析
StanとRでベイズ統計モデリング (Wonderful R)
【R言語】rvestパッケージによるウェブスクレイピング その2
Receiving NAs when scraping links (href) with rvest