最近、『Transformerによる自然言語処理』という書籍を買って、これまであまり追いかけていなかったTransformerについて仕事でカジュアルに使えるレベルまで色々と準備してみようと思い、その過程で見つけた色々な情報をまとめてみました。
以前、『BERTによる自然言語処理入門: Transformersを使った実践プログラミング』も買って、写経しながら試していたのですが、仕事であまり使う機会がなかったのであまり身につかなかったです。その反省も込めて、仕事でそのまま使えそうなレベルで備忘録としたいです。
Transformerについて
BERTについて
BERTを使うための色々
終わりに
参考情報
Transformerについて
ここでは仕組みと該当するコードについて見てみようと思います。TransformerはTransformer Encoderと呼ばれるニューラルネットワークのことをさします。Transformer Encoderはどのようなニューラルネットワークなのかと言うと、
- 入力(エンコーダスタック)
- Multi-Head Attention
- 正則化
- フィードフォワード
- 正則化
- 以上をN回繰り返す
- 出力へ渡す
- 出力(デコーダスタック)
- Masked Multi-Head Attention
- 正則化
- 入力からもらう
- Multi-Head Attention
- 正則化
- 正則化
- 以上をN回繰り返す
- 線形変換
- ソフトマックスで確率出力
という構造のネットワークで、Attentionという機構が特徴となっています。
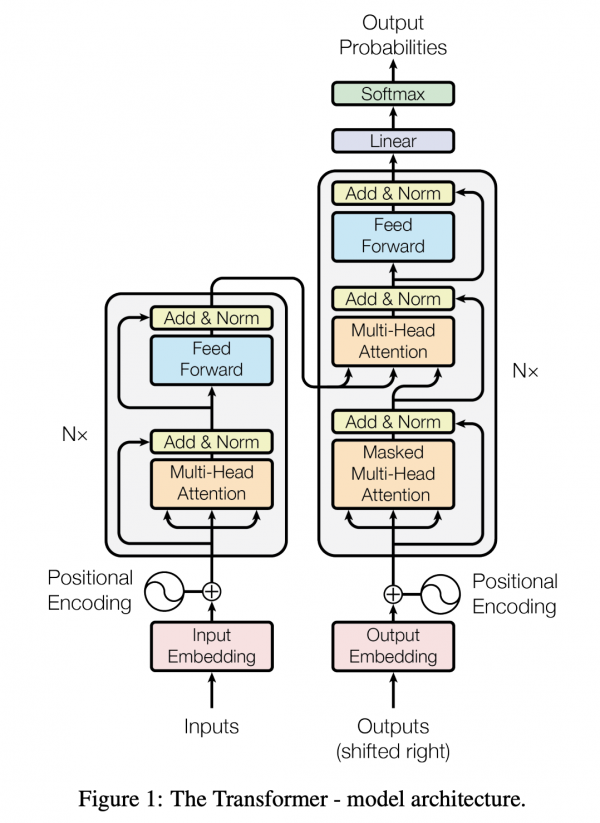
詳しい説明は、『Transformerによる自然言語処理』の第1章に記されています。加えて、元となっている“Attention Is All You Need”を読むと良いと思います。
Attentionが何なのかを理解する前に、RNNやLSTMやCNNのネットワークにはあるが、今回のTransformerのネットワークにはないものが何か考えてみると、再帰的な処理がないことがわかります。
もともとRNNなどは、ネットワークの隠れ層において再帰的な構造を持つことで前の状態を再び使いながら計算して学習していました。上の図を見れば、ぐるぐるとしていないことがわかると思います。
RNNなどはぐるぐると再起的に学習をして、単語ごとの関係性を学習していきますが、2つの単語の距離が離れるほどに計算時間がかかってしまうなどの問題がありました。Attentionは単語と全ての単語の間の関係をベクトルの内積で計算し、それを考慮することでこれまで以上に深く文脈を考慮した学習ができるようにしたものです。それに加えて、ベクトルを計算すればいいだけなので、並列処理もしやすく、計算速度の改善も利点としてあげられます。
Attentionの数式は以下の通りです。
Qはクエリベクトルで、元の入力データ(単語ベクトル)に重み行列\(W^Q\)を掛けて手に入れることができます。意味合いとしては検索をしたいもの。
Kはキーベクトルで、元の入力データ(単語ベクトル)に重み行列\(W^K\)を掛けて手に入れることができます。意味合いとしては、検索をするクエリと入力データの近さを示すもの。
Vは値ベクトルで、元の入力データ(単語ベクトル)に重み行列\(W^V\)を掛けて手に入れることができます。意味合いとしては、検索するクエリと入力データに応じた値。
\(d_k\)は次元数で、ベクトルの次元数が増えても重みが0になりにくいように、学習が進むようにするために割るために使われています。
QとKの内積が単語ごとの関連性をつかさどります。これらの値を代入して、softmax関数で返したものがAttentionとなります。参考文献の例では64次元となっています。内積を使って関連性を表現すると言うところは非常に親近感がわいて理解が捗ります。
しかしながら、なぜQ,K,Vに分ける必要があるのかいまいち腑に落ちません。こちらのブログ(【論文】”Attention is all you need”の解説)によると、モデルの表現力を高めるためとあるようで、KとVの関係について色々な変換を通じて、人間が想像できないレベルの関係性を拾おうとしているようです。
続いて、MultiHead Attentionの数式は以下の通りです。
where \ head_i = Attention(QW_i^Q, KW_i^K, VW_i^V) $$
MultiHead Attentionでは、複数のAttentionが連結されていることがわかります。
64次元のAttentionが8つあるので、MultiHead Attentionは512次元になります。
\(W^O\)は訓練される重み行列となります。
ここで、最終的に何を訓練しているかというと、例えば、英語に対するドイツ語のような、言語のペア、つまり翻訳をするというタスクの訓練をしていることになります。
なお、もととなる研究では言語のペアに関して、Byte-Pair Encoding (BPE)を行った上で学習をしています。
BPEはこちらの記事(Byte-Pair Encoding: Subword-based tokenization algorithm)の説明がわかりやすいです。
以上より、Attentionは翻訳という機械学習を行う過程で、深いネットワークを通じて、ある単語がどの単語に対して着目するべきかの重み付け(\(W^O\)の推定)を行っているとみなすことができます。
さて、出力(デコーダー)のMaskedがなんなのかと言うと、推論する際に、「文字列の位置において未来を見ないように処理をする」という意味で、具体的には隠すという処理です。ある文字列が出てきたところまでしか情報を持ち得ないため、このような処理をしていることになります。
ソースコードに移る前に、一つだけ忘れているところがありました。位置エンコーディング(Positional Encoding:PE)です。単語ベクトルにすることで位置情報を失ってしまっているため、それを補う処理が必要となります。
PEは埋め込みの各次元iごとに、位置情報としてサイン/コサイン関数で定義されます。
$$PE_{position 2i} = \sin \left ( \frac{position}{10000^{\frac{2i}{d_{model}}}} \right ) $$
$$PE_{position 2i+1} = \cos \left ( \frac{position}{10000^{\frac{2i}{d_{model}}}} \right ) $$
positionは単語の位置なので3つ目なら3、10個目なら10を取る値となります。iは位置エンベッディングの次元です。\(d_{model}\)は埋め込みベクトルの次元数で今回だと512となります。偶数はサイン関数、奇数はコサイン関数で表現する流れです。
とは言うものの、腑に落ちないのでもう少し調べてみます。この処理で十分にユニークな位置の情報を表現することができるのでしょうか。
以下の情報などが参考になりました。
What is the positional encoding in the transformer model?
Visual Guide to Transformer Neural Networks – (Episode 1) Position Embeddings
そこで紹介された図が以下のものです。
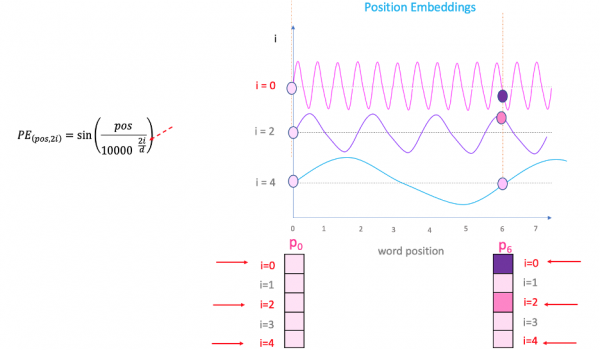
どうやら、サイン・コサイン関数は循環するので何度も同じ値をとることになりますが、エンベッディングの次元ごとに値が変わっていくようになっているので、その心配はいらないようです。
このPEの値を、埋め込みベクトルに足すなどすることで位置情報を失われることなく後に続くネットワークで活用できるようになります。
$$ y_1 = dog \\
pc(dog) = y_1 \times \sqrt d_{model} + PE(3) $$
というイメージです。\(y_1\)にかかっている値は、PEの影響が消えてしまわないようにするテクニックとされています。
なんとなく、全体感がわかったところでソースコードで確かめてみたいと思います。
今回は、attention-is-all-you-need-pytorchというリポジトリを見つけたので、そこを見てみます。以上で紹介した仕組みに関しては、https://github.com/jadore801120/attention-is-all-you-need-pytorch/blob/master/transformer/Models.pyのコードで扱われています。
こちらのコードは、Transformer、Encoder、Decoder、PositionalEncodingという4つのクラスからなります。
PositionalEncodingでは先ほどのサインコサイン関数での処理がそのまま書かれています。
Encoderでは先ほどの図の左のネットワークに関する処理が書かれています。
Decoderでは先ほどの図の右のネットワークに関する処理が書かれています。左のネットワークのアウトプットを途中受け取る処理などが確認できます。
Transformerではエンコーダーとデコーダーを介して線形変換した予測値を返す処理が書かれています。
別途、get_pad_mask関数を用いたパディング処理や、上三角行列に変換することで未来の単語を見えないようにする関数get_subsequent_maskなどもあります。
以上がコードですが、計算コストに関しても論文にあったので記しておこうと思います。論文によると、84万円くらいするGPU(NVIDIA Tesla P100)を8つ使って3.5日くらい回したそうで、推定したパラメータの数は1000万は軽く超えており、最大でも2億個くらいあるようです。
とてもではないですが、個人や月並みの企業では学習に関しては取り組み難いものであるのは間違いありません。民間企業のデータサイエンティストとしては、学習済みのモデルを使って、既存のNLPタスクなどをどう解決するかを頑張る道が賢明のようです。
BERTについて
BERTは登場して久しいですが、先ほど紹介したTransformerをもとに、双方向MultiHead Attention副層が追加され、デコーダーの部分(先ほどの図の右側のネットワーク)がなくされたものがBERTとなります。双方向の字面どおり、Bidirectional Encoder Representations from Transformersで頭文字をとってBERTと呼びます。
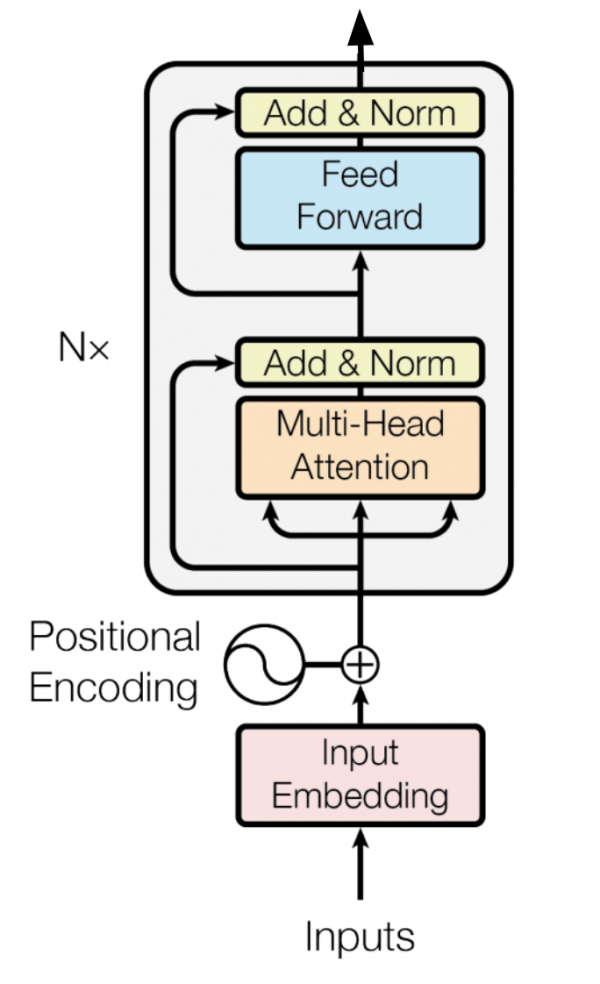
ネットワーク層としては先ほどのTransformerの左側(エンコーダー)だけの形となります。
BERTは学習のために二つの手段を取ります。一つ目はマスク付き言語モデルです。双方向という表現は、ネットワーク間でランダムに単語をマスクして、それを予測するために学習し合うというところから来ています。二つ目は次文予測(Next Sentence Prediction)で、ある単語からなる系列の後に次なる系列が続くのかどうかを学習します。
これら二つを組み合わせてNLPタスクを解くために学習をするという流れです。具体的なタスクとしては、文章と文法のペアなどを学習用データとして、文章から文法を当てるというタスクなどです。
BERTのPyTorchでの実装は、こちらのGitHub(BERT-pytorch)にありました。詳細は記さないですが、model/bert.pyのところに、マスク付き言語モデルの部分、次文予測の部分が実装されていることが確認できます。
BERTを使うための色々
仕事で使えそうなものがいいので、学習済みのBERTを使って日本語のNLPタスクを行うためのコードをこしらえてみました。
『BERTによる自然言語処理入門: Transformersを使った実践プログラミング』という書籍の第6章に文書分類(記事のカテゴリ分類)を、日本語の学習済みBERTで実践するコードが記されていますので、困ったらこのコードを見て日々の仕事をすればいいかもしれません。
こちら(BERT_Chapter6.ipynb)は、Google Colabで写経したもので書籍にあるものと同じです。
以下、マルチラベル文章分類の7章の写経Colab(BERT_Chapter7.ipynb)と固有名詞抽出の8章の写経Colab(BERT_Chapter8.ipynb)もあるので、合わせてここぞと言う時に使いたいと思います。
他にも、BERTのハンズオン資料を見つけました。こちらも日本語のNLPタスクを行えるチュートリアルなので、業務で使う際に参考になりそうです。
huggingface transformers を使って日本語 BERT モデルをファインチューニングして感情分析 (with google colab) part01
huggingface transformers を使って日本語 BERT モデルをファインチューニングして感情分析 (with google colab) part02
終わりに
今回は、いまさらながらTransformerとBERTについて情報を色々集めてみました。推論時に十分な速度を出せるのかまだ判断がつくレベルで使っていないので、今後は色々な分析課題に適用して、Word2Vec並みにリーズナブルな分析アプローチとして業務に組み込んでいきたいですね。
Word2Vecを夜な夜な会社のパソコンで学習して2日くらいかけたのは、もう8年も前の話で非常に懐かしいです。Transformer系となると計算資源的に厳しいものがありますが、どうにか学習させてみたいとも思っています。
参考情報
・Attention 機構を用いたDeep Learning モデルによるひび割れ自動検出
・Transformerにおける相対位置エンコーディングを理解する。
・【論文】”Attention is all you need”の解説
・Transformerのデータの流れを追ってみる
・A Gentle Introduction to Positional Encoding In Transformer Models, Part 1
・TORCH.TRIU
・huggingface transformersで使える日本語モデルのまとめ
・huggingface transformers を使って日本語 BERT モデルをファインチューニングして感情分析 (with google colab) part01
・huggingface transformers を使って日本語 BERT モデルをファインチューニングして感情分析 (with google colab) part02