はじめに
word2vecを用いた分類は以前からやってみたいと思っていたのですが、関心を持てるテキストデータがなかったのでなかなか手を出していませんでした。
ある時、ふとしたことから某グルメ系口コミサイトから蒙古タンメン中本の口コミと評価点を抽出して、その評価をword2vecでやってみるのは面白いだろうと思いついたので、さっそくやってみます。
こういう時にはじめて、データ分析だけでなくクローリング屋としても業務をやっていて良かったなと思うところですね。
コードは以前見つけて紹介した「分散表現を特徴量として文書分類するための方法について調べてみた」のものを再利用します。
目次
・目的
・データ収集
・形態素解析
・集計
・分散表現とは
・word2vecについて
・gensimのword2vecの引数
・word2vecによる文書分類の適用
・終わりに
・参考情報
目的
某グルメ系口コミサイトの口コミを収集し、個々人の口コミの内容から個々人の店に対する評価が高いか低いかを予測する。
データ収集
BeautifulSoupで収集しており、各店舗あわせて数千件ほど集めました。(実行コードはこちらでは紹介しません。)
このようなデータが手に入っている前提で以下の分析を進めていきます。

形態素解析
文書を形態素解析して、名詞のみを抽出するためのコードを用意します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import MeCab tagger = MeCab.Tagger("-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd/") def nouns_extract(line): keyword=[] node = tagger.parseToNode(line).next while node: if node.feature.split(",")[0] == "名詞": keyword.append(node.surface) node = node.next keyword = str(keyword).replace("', '"," ") keyword = keyword.replace("\'","") keyword = keyword.replace("[","") keyword = keyword.replace("]","") return keyword |
先ほどのデータフレームに対して以下のように実行すれば、名詞のみの分かち書きを行ったカラムが手に入ります。
|
1 |
corpus_data["text_wakati"] = list(map(lambda text:nouns_extract(text) , corpus_data.text)) |
集計
点数のヒストグラム
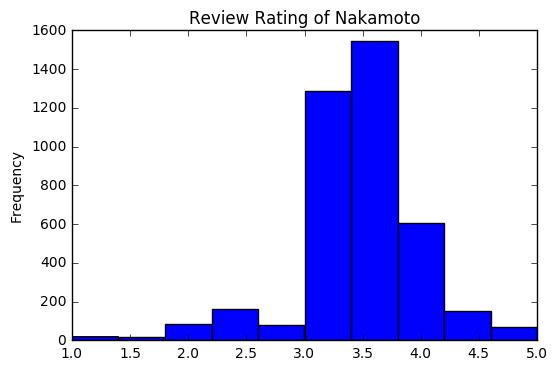
3.5点から4点の間が最も評価が多いようです。1点台をつける人はほとんどいないことがわかります。
単語数のヒストグラム

大体の口コミで100単語未満のようです。
単語数と点数の散布図
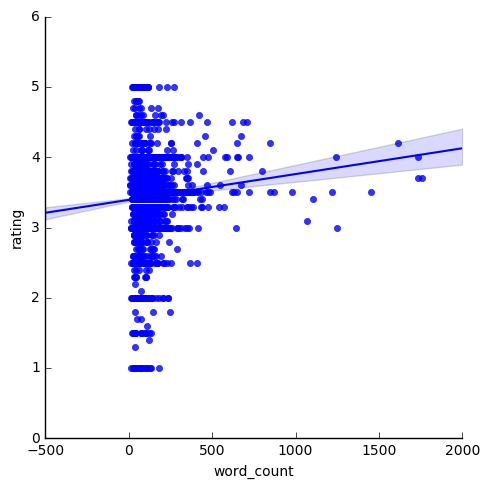
どうやら口コミにおいて500語を超える記述をしている人は評価が3点を下回ることはないようですが、文字数と点数でキレイに傾向が出ているわけではないですね。
形態素解析結果の集計、単語ランキング
名詞の抽出に関して非常に便利なMeCab Neologdを用いています。蒙古タンメンもきちんと捉えることができています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import collections tagger = MeCab.Tagger("-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd/") noun_list = [] # 重複を含めた名詞のリスト for i in corpus_data.text: for l in tagger.parse(i).splitlines(): try: if l != 'EOS' and l.split('\t')[1].split(',')[0] == '名詞': # EOSを除き名詞のみ抽出 noun_list.append(l.split('\t')[0]) # 見出し追加 except: pass noun_cnt = collections.Counter(noun_list) # 各名詞の数え上げ word_count_df = pd.DataFrame.from_dict(noun_cnt, orient='index').reset_index() word_count_df.columns = ["word", "count"] word_count_df = word_count_df[~word_count_df.word.str.contains("^[あ-ん]$")] word_count_df.sort_values("count",ascending=False).head(10) |
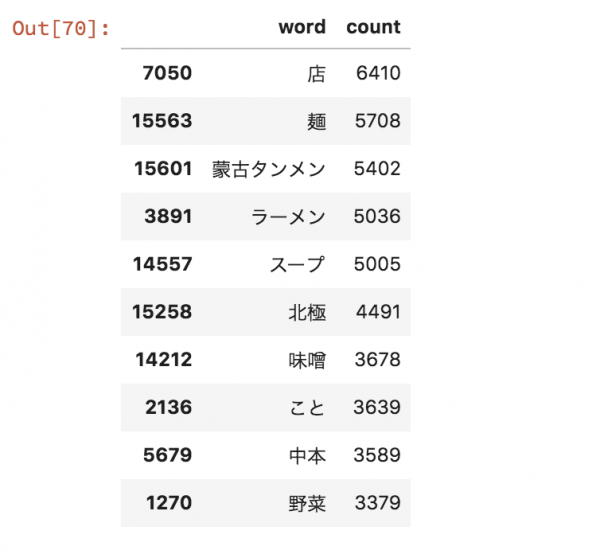
味噌よりも北極の方が出現しているようです。北極は言わずもがな、極端に辛い罰ゲームレベルの一品。味噌タンメンは辛さが抑えめのラーメンで、知人の間では最もおいしいのがこのレベルだという合意があったりしますね。
分散表現とは
- 単語の意味を低次元の密な実数値ベクトルで表現したもの。
- 入力層から中間層への重み自体が各単語の分散表現となっている。
- 2017年9月のテキストアナリティクスシンポジウムにてメルカリとGunosyが特徴量として分散表現を活用しており性能が出ているとの発言があった。
word2vecについて
単語の分散表現を作ることを目的としている。
- CBOW(Continuous Bag-of-Words)
注目している単語の前後N単語を文脈と呼び、その文脈をBag-of-Words表現として入力し、注目している単語を出力するというニューラルネットワークを学習する。入力層から隠れ層への結合は単語の位置を問わず同じとし、隠れ層の活性化関数をただの恒等関数としている。 - Skip-gram
文脈のBOWを突っ込むCBOWとは異なり、入力層に1単語だけを入れる。1単語を入力し、正解データとして他の単語を入れることを繰り返して学習し、ある単語の入力に対して、どの単語の出現確率が高いかどうかを計算する。正解確率が上がるようにニューラルネットワークの重みを調整する。深層学習で使われる自己符号化器と似たような構造とされている。
gensimのword2vecの引数
gensimのword2vecには数多くの引数が存在します。gensimのドキュメントに英語で書かれていますが、せっかくなのでこちらで紹介します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
class gensim.models.word2vec.Word2Vec(sentences=None, size=100, alpha=0.025, window=5, min_count=5, max_vocab_size=None, sample=0.001, seed=1, workers=3, min_alpha=0.0001, sg=0, hs=0, negative=5, cbow_mean=1, hashfxn=<built-in function hash>, iter=5, null_word=0, trim_rule=None, sorted_vocab=1, batch_words=10000, compute_loss=False, callbacks=()) |
- sentences
解析に使う1行1センテンスで書かれた文書。日本語の場合はLineSentenceフォーマットを使えばうまくいった。単語が空白文字で区切られていて、文章は改行で区切られていれば問題ない。 - sg
{1,0}の整数で訓練アルゴリズムを設定できる。 1を選べばskip-gramで、0ならばCBOWを使う。 - size
特徴ベクトルの次元を設定する。 - window
文書内における現在の単語と予測した単語の間の距離の最大値を設定する。言い換えると、文脈の最大単語数を設定する。 - alpha
学習率の初期値を設定する。 - min_alpha
訓練の過程で徐々に落ちていく学習率の最小値を設定する。 - seed
乱数を生成する際のシード番号を設定する。 - min_count
一定の頻度以下の単語を除外する際の値を設定する。 - max_vocab_size
語彙ベクトルを構築している際のメモリ制限を設定する。 - sample
(0, 1e-5)の範囲で、頻度語がランダムに削除される閾値を設定する。高速化と精度向上を狙っており、自然言語処理においても高頻度語はストップワードとして除去するなどの対応が取られている。 - workers
モデルを訓練するために多くのワーカースレッドを利用するかどうか設定する。(並列化関連) - hs
{1,0}の整数で、1であれば階層的ソフトマックスがモデルの訓練で用いられ、0であり引数negativeがnon-zeroであればネガティヴサンプリングが設定できる。全部計算することが大変なので、階層的なグループに分けて各グループごとに学習するというのがモチベーション。 - negative
0よりも大きければネガティブサンプリングが用いられる。5〜20などを選び、どれだけノイズワードが描かれているかを識別する。0であればネガティブサンプリングが適用されない。ネガティブサンプリングは計算高速化を目的に出力層で正解ニューロン以外のニューロンを更新しないように学習する手法。 - cbow_mean
{1,0}の整数で、0であれば単語ベクトルの合計を用い、1であればCBOWが用いられた際の平均が用いられる。 - hashfxn
訓練の再現性のためにランダムに初期値のウエイト付けできる。 - iter
コーパスにおける繰り返し回数(エポック数)を設定できる。 - trim_rule
ある単語を語彙に含めるべきかどうかを識別する、語彙のトリミングルールを設定する。 - sorted_vocab
{1,0}の整数で、1であれば頻度の降順で語彙を並べ替える。 - batch_words
ワーカースレッドにわたすバッチの大きさを指定する。(並列化関連) - compute_loss
Trueであれば損失関数の計算と蓄積を行う。 - callbacks
訓練時の特定の段階で実行する際に必要なコールバックのリストを指定できる。
word2vecによる文書分類の適用
口コミの点数が4点以上であれば1、そうでなければ0を取る変数を作成し、それをラベルとして文書分類を行います。
以前、紹介したブログ同様に、scikit-learnのExtraTreesClassifierを用いてCountVectorizerとTfidfVectorizerを特徴量としたものをベースラインとして、同様の手法に対してword2vecで作成した分散表現を特徴量として用いたものとを比較します。評価指標はクロスバリデーションスコア(5-folds)とします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
from gensim.models.word2vec import Word2Vec from gensim.models import word2vec import matplotlib.pyplot as plt import seaborn as sns from tabulate import tabulate from collections import Counter, defaultdict from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.ensemble import ExtraTreesClassifier from sklearn.pipeline import Pipeline from sklearn.metrics import accuracy_score from sklearn.cross_validation import cross_val_score from sklearn.cross_validation import StratifiedShuffleSplit #単語の分散表現の平均値を求めるクラスの定義 class MeanEmbeddingVectorizer(object): def __init__(self, word2vec): self.word2vec = word2vec self.dim = word2vec.values() self.dim = next(iter(self.dim)) self.dim = self.dim.size def fit(self, X, y): return self def transform(self, X): return np.array([ np.mean([self.word2vec[w] for w in words if w in self.word2vec] or [np.zeros(self.dim)], axis=0) for words in X ]) #TF-IDFで重み付けした分散表現を求めるクラスの定義 class TfidfEmbeddingVectorizer(object): def __init__(self, word2vec): self.word2vec = word2vec self.word2weight = None self.dim = word2vec.values() self.dim = next(iter(self.dim)) self.dim = self.dim.size def fit(self, X, y): tfidf = TfidfVectorizer(analyzer=lambda x: x) tfidf.fit(X) max_idf = max(tfidf.idf_) self.word2weight = defaultdict( lambda: max_idf, [(w, tfidf.idf_[i]) for w, i in tfidf.vocabulary_.items()]) return self def transform(self, X): return np.array([ np.mean([self.word2vec[w] * self.word2weight[w] for w in words if w in self.word2vec] or [np.zeros(self.dim)], axis=0) for words in X ]) #ベースラインとなる既存手法のモデルの準備 #etree etree = Pipeline([("count_vectorizer",CountVectorizer(analyzer=lambda x: x)), ("linear svc", SVC(kernel="linear"))]) #etreeのTF-IDF版 etree_tfidf = Pipeline([("tfidf_vectorizer", TfidfVectorizer(analyzer=lambda x: x)), ("extra trees", ExtraTreesClassifier(n_estimators=200))]) #Word2Vecを特徴量としてExtraTreesによる分類器を準備する。 etree_w2v = Pipeline([("word2vec vectorizer", MeanEmbeddingVectorizer(w2v)), ("extra trees", ExtraTreesClassifier(n_estimators=200))]) etree_w2v_tfidf = Pipeline([("word2vec vectorizer", TfidfEmbeddingVectorizer(w2v)), ("extra trees", ExtraTreesClassifier(n_estimators=200))]) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#4点以上であれば1そうでなければ0 corpus_data["label"] = np.where(corpus_data.rating >= 4, 1, 0) #scikit-learnで使う入力とラベルの設定 X, y = np.array(corpus_data.text_wakati), np.array(corpus_data.label) sentences2 = [token.split(" ") for token in corpus_data.text_wakati] #Word2Vecを実行する。 model = Word2Vec(sentences2, size=100, window=5, min_count=5, workers=2) w2v = {w: vec for w, vec in zip(model.index2word, model.syn0)} |
分類の前に、せっかくword2vecを使ったので、任意の単語に類似した単語を見てみます。
まずは初心者向けの味噌ラーメン
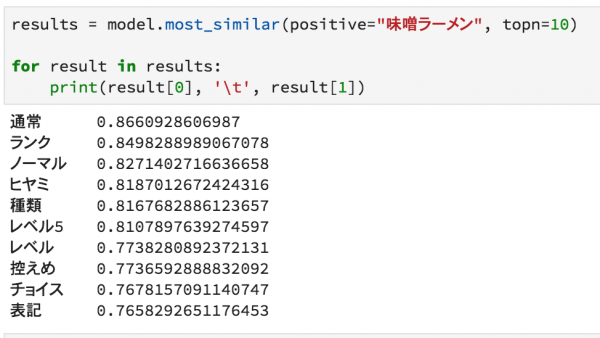
続いて、中級者向けの蒙古タンメン
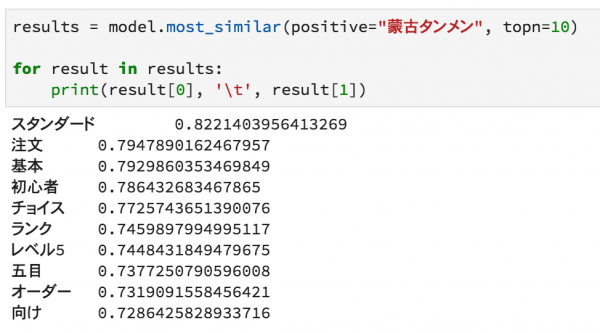
そして、上級者向けの北極ラーメン
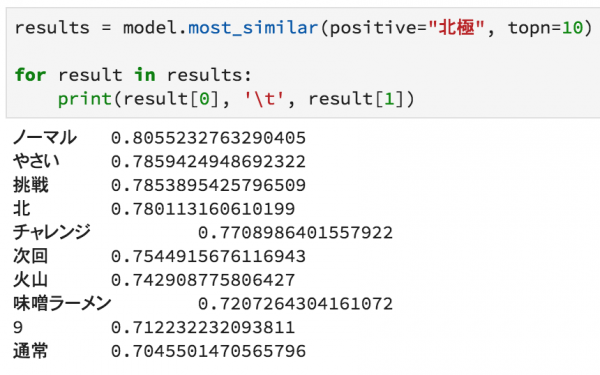
最後に、誰もが経験する翌日という単語。

どれも関連性の高いと思われる単語が抽出できているように思われます。
それでは分類モデルの学習を以下のコードで行います。
scikit-learnを使えば、データさえあれば非常に短いコードで書けてしまいます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#各モデルを実行し、クロスバリデーションスコアを計算し、出力させる。 all_models = [ ("etree",etree), ("etree_tfidf",etree_tfidf), ("w2v", etree_w2v), ("w2v_tfidf", etree_w2v_tfidf) ] scores = sorted([(name, cross_val_score(model, X, y, cv=5).mean()) for name, model in all_models], key = lambda x:x[0]) print(tabulate(scores, floatfmt=".4f", headers=("model", 'score'))) #棒グラフでクロスバリデーションスコアを比較する。 plt.figure(figsize=(15, 6)) sns.barplot(x=[name for name, _ in scores], y=[score for _, score in scores]) |
|
1 2 3 4 5 6 |
model score ----------- ------- etree 0.6959 etree_tfidf 0.8031 w2v 0.8046 w2v_tfidf 0.8038 |

一応、ベースラインよりもword2vecを特徴量としたものの方がスコアが高いのですが、わずかです。TF-IDFベースで特徴量を作成したモデルは十分に性能が出ているようです。
word2vecを用いることによる旨味はそれほどなさそうですが、パラメータを試行錯誤していけばよくなるかもしれません。
終わりに
蒙古タンメン中本のテキストをWebスクレイピングし、その口コミ情報をコーパスとして口コミ評価の二値分類に挑戦しましたが、TF-IDFよりもわずかに優秀な特徴量になりうるという結果になりました。もっと劇的な向上を夢見ていたのですが、パラメータの試行錯誤を今後の宿題としようと思います。
参考情報
Chainer v2による実践深層学習
word2vecによる自然言語処理
models.word2vec – Deep learning with word2vec
Python で「老人と海」を word2vec する
Python3 – MeCabで日本語文字列の名詞出現数の出し方について
Transform a Counter object into a Pandas DataFrame