テキストデータの特徴量化について
仕事ではテキストデータを多用するので、機械学習などで扱うためにテキストデータを特徴量にするためのアプローチを色々と整理してソースコードを残しておきたいと思います。今回はあくまでも私の知っているものだけなので、網羅性はないかもしれませんが悪しからず。
(2019/08/18 追記)Stackingをカジュアルに行えるvecstackというモジュールを用いた予測も試してみました。下の方の追記をご覧ください。
アプローチ
テキストデータを特徴量にする際のアプローチとしては、以下の3つが良く使っているものとなります。
・単語ベース
・クラスタ、トピック、分散表現ベース
・文書間の類似度ベース
今回扱うデータ
ひょんなことから、昨年10月くらいに取りためたマンションの施設情報のテキストです。

緑色が印象的な某不動産紹介サイトをクローリングしました。全部で1864件ほどの文書数となります。
加えて、デザイナーズマンションかどうかのフラグを作成しました(17%くらいがデザイナーズマンションの割合)。これでもって、マンションの施設情報からデザイナーズマンションかどうかを分類できるかチャレンジしたいと思います。
ここにデータを置いていますので、興味のある方はご利用ください。
今回扱うモデル
ランダムフォレストです。10foldsクロスバリデーションによるAUCの結果を各手法のスコアとして扱います。
こちらは、任意の手法に関して10foldsクロスバリデーションで実行し、AUCのグラフを生成してくれるソースコードです。主にscikit-learnのサイトに載っているものです。引数のclassifierをsklearnの任意のモデルのインスタンスで渡せば動きます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
def classification_and_roc_analysis(k, classifier, X, y): import numpy as np from scipy import interp import matplotlib.pyplot as plt from pylab import rcParams rcParams['figure.figsize'] = 8,8 from sklearn.model_selection import StratifiedKFold from sklearn.metrics import roc_curve, auc from sklearn.ensemble import RandomForestClassifier # Classification and ROC analysis # Run classifier with cross-validation and plot ROC curves cv = StratifiedKFold(n_splits=k, random_state = 123) classifier = classifier tprs = [] aucs = [] mean_fpr = np.linspace(0, 1, 100) i = 0 for train, test in cv.split(X, y): probas_ = classifier.fit(X[train], y[train]).predict_proba(X[test]) # Compute ROC curve and area the curve fpr, tpr, thresholds = roc_curve(y[test], probas_[:, 1]) tprs.append(interp(mean_fpr, fpr, tpr)) tprs[-1][0] = 0.0 roc_auc = auc(fpr, tpr) aucs.append(roc_auc) plt.plot(fpr, tpr, lw=1, alpha=0.3, label='ROC fold %d (AUC = %0.2f)' % (i, roc_auc)) i += 1 plt.plot([0, 1], [0, 1], linestyle='--', lw=2, color='r', label='Chance', alpha=.8) mean_tpr = np.mean(tprs, axis=0) mean_tpr[-1] = 1.0 mean_auc = auc(mean_fpr, mean_tpr) std_auc = np.std(aucs) plt.plot(mean_fpr, mean_tpr, color='b', label=r'Mean ROC (AUC = %0.2f $\pm$ %0.2f)' % (mean_auc, std_auc), lw=2, alpha=.8) std_tpr = np.std(tprs, axis=0) tprs_upper = np.minimum(mean_tpr + std_tpr, 1) tprs_lower = np.maximum(mean_tpr - std_tpr, 0) plt.fill_between(mean_fpr, tprs_lower, tprs_upper, color='grey', alpha=.2, label=r'$\pm$ 1 std. dev.') plt.xlim([-0.05, 1.05]) plt.ylim([-0.05, 1.05]) plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.title('Receiver operating characteristic example') plt.legend(loc="lower right") plt.show() |
単語ベース
シンプルに単語をそのまま特徴量にするというものですが、文書によっては単語数が多すぎて収集がつかないと思います。そこで単語を簡単に選択できるDocumentFeatureSelectionというパッケージを利用します。
|
1 2 3 4 |
# 事前にインストールしておく pip install DocumentFeatureSelection pip install JapaneseTokenizer pip install neologdn |
このパッケージでは
・TF-IDFベースの特徴量選択
・PMI(Pointwise Mutual Information)ベースの特徴量選択
・SOA(Strength of association)ベースの特徴量選択
・BNS(Bi-Normal Separation)ベースの特徴量選択
を行うことができます。
まずは今回のベースラインとして、単語のカウントベースでの特徴量を扱いたいと思います。
その前に、GitHubに上がっているデータに対して以下のように簡単な前処理をしておきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
%matplotlib inline import pandas as pd import numpy as np import seaborn as sns import copy import warnings warnings.filterwarnings('ignore') # Data Import corpus_data = pd.read_csv("designers_apartment.csv") corpus_data = corpus_data[~corpus_data.text.isna()].reset_index(drop=True) # 形態素解析 import collections import MeCab import mojimoji from string import digits remove_digits = str.maketrans('', '', digits) tagger = MeCab.Tagger("-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd/") def nouns_extract(line): keyword=[] node = tagger.parseToNode(line).next while node: if node.feature.split(",")[0] == "名詞": keyword.append(node.surface) node = node.next keyword = str(keyword).replace("', '"," ") keyword = keyword.replace("\'","") keyword = keyword.replace("[","") keyword = keyword.replace("]","") return keyword # 全角を半角にする corpus_data["text_fixed"] = list(map(lambda text: mojimoji.zen_to_han(text, kana=False) , corpus_data.text)) # 数字を除外する corpus_data["text_fixed"] = list(map(lambda text: text.translate(remove_digits) , corpus_data.text_fixed)) # デザイナーズという表現を除外する corpus_data["text_fixed"] = corpus_data.text_fixed.str.replace("デザイナーズ", "") # 形態素解析する corpus_data["text_wakati"] = list(map(lambda text:nouns_extract(text) , list(corpus_data.text_fixed))) |
ようやくベースラインの予測となります。以下のコードを実行すると、ROCが描かれた図がJupyter上で表示されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from sklearn.feature_extraction.text import CountVectorizer # word count feature countvector = CountVectorizer(min_df=0.01, max_df=0.90) matrix = countvector.fit_transform(corpus_data.text_wakati) countvector.get_feature_names()[:10] X = matrix y = corpus_data.designer_flag.values n_samples, n_features = X.shape print(n_features) random_state = np.random.RandomState(0) classifier = RandomForestClassifier(random_state=random_state) # classification and draw roc curve classification_and_roc_analysis(k=10, classifier=classifier, X=X, y=y) |
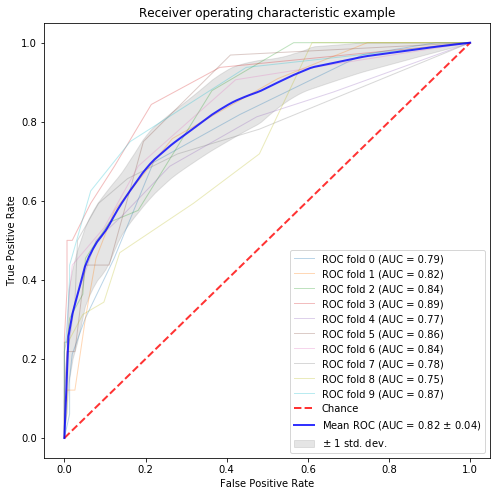
AUC82%というのはベースラインとしてはなかなか強敵なのではないでしょうか。
さて、本題の特徴量選択パッケージの適用をするためのソースコードを以下に記します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 |
from scipy.sparse import csr_matrix import JapaneseTokenizer from DocumentFeatureSelection import interface # `mecab-config` コマンドが通っているパスを書きます。場所がわからない時は`which mecab-config`で探してみてください。 path_mecab_config='/usr/local/bin' # 辞書タイプを選びます。"neologd", "all", "ipaddic", "user", ""が選べます。 dictType = "neologd" pos_condition = [('名詞',)] mecab_wrapper = JapaneseTokenizer.MecabWrapper( dictType=dictType, path_mecab_config=path_mecab_config ) def tokenize_and_filtering(docs): assert isinstance(docs, list) tokenized_docs = [ mecab_wrapper.tokenize( sentence=doc.strip('\n'), return_list=False ) for doc in docs ] filtered_tokens = [ mecab_wrapper.filter( parsed_sentence=tokenized_obj, pos_condition=pos_condition ).convert_list_object() for tokenized_obj in tokenized_docs ] return filtered_tokens # デザイナーズマンションとそうでないマンションでテキストを分ける processed_designer = tokenize_and_filtering(corpus_data.query(' designer_flag ==1 ').text_fixed.tolist()) processed_normal = tokenize_and_filtering(corpus_data.query(' designer_flag ==0 ').text_fixed.tolist()) input_labeled_docs_dict = { 'designer': processed_designer, 'normal': processed_normal } # TF-IDF base tf_idf_scored_object = interface.run_feature_selection( input_dict=input_labeled_docs_dict, method='tf_idf', n_jobs=5 ) tf_idf_scored_df = pd.DataFrame(tf_idf_scored_object.ScoreMatrix2ScoreDictionary()) # PMI base pmi_scored_object_cython = interface.run_feature_selection( input_dict=input_labeled_docs_dict, method='pmi', use_cython=True ) pmi_scored_df = pd.DataFrame(pmi_scored_object_cython.ScoreMatrix2ScoreDictionary()) # SOA base soa_scored_object_cython = interface.run_feature_selection( input_dict=input_labeled_docs_dict, method='soa', use_cython=True ) soa_scored_df = pd.DataFrame(soa_scored_object_cython.ScoreMatrix2ScoreDictionary()) # BNS base bns_scored_object = interface.run_feature_selection( input_dict=input_labeled_docs_dict, method='bns', n_jobs=5 ) bns_scored_df = pd.DataFrame(bns_scored_object.ScoreMatrix2ScoreDictionary()) |
以上のソースコードを実行すれば、tf_idf_scored_df、pmi_scored_df、soa_scored_df、bns_scored_dfにスコアを付与された単語のリストが手に入ります。
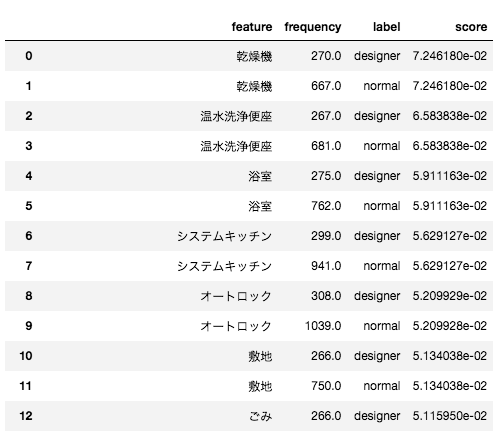
ここでは各スコアに関してアドホックに閾値を設けて、特徴量として利用することにします。
TF-IDFベースの特徴量選択
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
tfidf_list = tf_idf_scored_df.query(' score > 0.001 ').feature.unique().tolist() corpus_data["tfidf_base_list"] = list(map(lambda text: " ".join(list(set(text.split(" ") ) & set(tfidf_list))) , corpus_data.text_wakati)) # word count feature countvector = CountVectorizer() matrix = countvector.fit_transform(corpus_data.tfidf_base_list) X = matrix y = corpus_data.designer_flag.values n_samples, n_features = X.shape print(n_features) random_state = np.random.RandomState(0) classifier = RandomForestClassifier(random_state=random_state) # classification and draw roc curve classification_and_roc_analysis(k=10, classifier=classifier, X=X, y=y) |
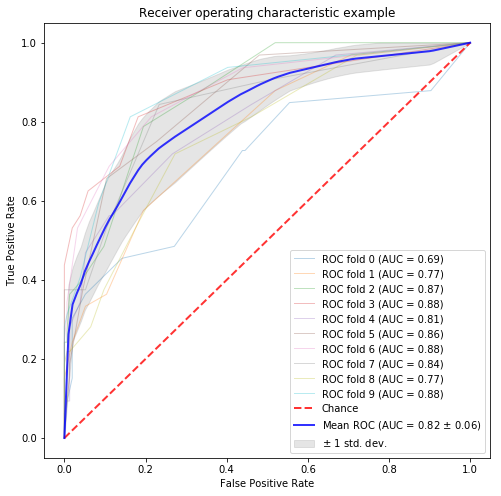
PMIベースの特徴量選択
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
pmi_list = pmi_scored_df.query(' score > 0.001 ').feature.unique().tolist() corpus_data["pmi_base_list"] = list(map(lambda text: " ".join(list(set(text.split(" ") ) & set(pmi_list))) , corpus_data.text_wakati)) # word count feature countvector = CountVectorizer() matrix = countvector.fit_transform(corpus_data.pmi_base_list) X = matrix y = corpus_data.designer_flag.values n_samples, n_features = X.shape print(n_features) random_state = np.random.RandomState(0) classifier = RandomForestClassifier(random_state=random_state) # classification and draw roc curve classification_and_roc_analysis(k=10, classifier=classifier, X=X, y=y) |
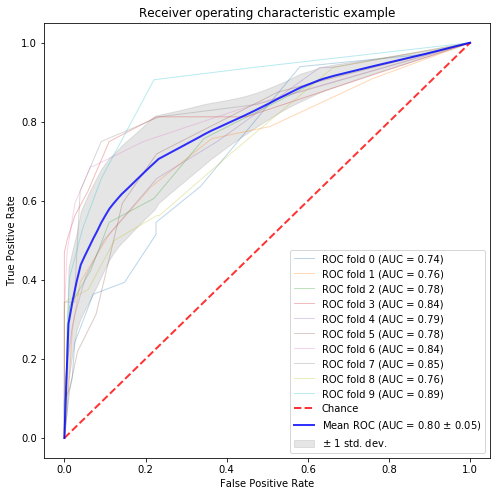
SOAベースの特徴量選択
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
soa_list = soa_scored_df.query(' score > 0.2 ').feature.unique().tolist() corpus_data["soa_base_list"] = list(map(lambda text: " ".join(list(set(text.split(" ") ) & set(soa_list))) , corpus_data.text_wakati)) # word count feature countvector = CountVectorizer() matrix = countvector.fit_transform(corpus_data.soa_base_list) X = matrix y = corpus_data.designer_flag.values n_samples, n_features = X.shape print(n_features) random_state = np.random.RandomState(0) classifier = RandomForestClassifier(random_state=random_state) # classification and draw roc curve classification_and_roc_analysis(k=10, classifier=classifier, X=X, y=y) |
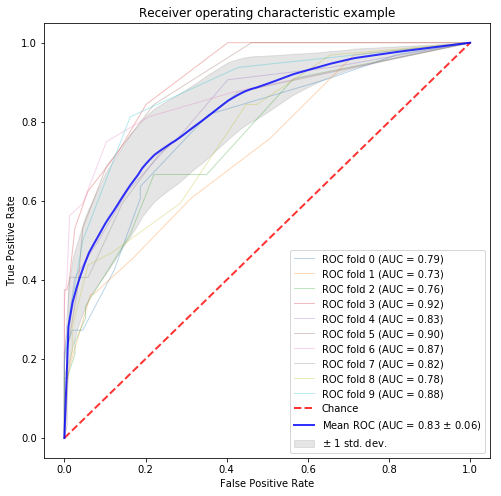
BNSベースの特徴量選択
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
bns_list = bns_scored_df.query(' score > 0.1 ').feature.unique().tolist() corpus_data["bns_base_list"] = list(map(lambda text: " ".join(list(set(text.split(" ") ) & set(bns_list))) , corpus_data.text_wakati)) # word count feature countvector = CountVectorizer() matrix = countvector.fit_transform(corpus_data.bns_base_list) X = matrix y = corpus_data.designer_flag.values n_samples, n_features = X.shape print(n_features) random_state = np.random.RandomState(0) classifier = RandomForestClassifier(random_state=random_state) # classification and draw roc curve classification_and_roc_analysis(k=10, classifier=classifier, X=X, y=y) |
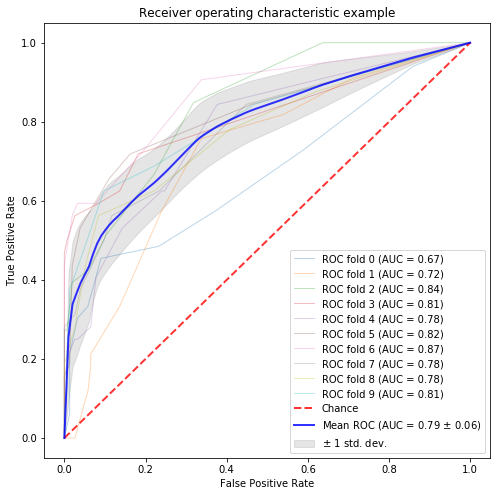
クラスタ、トピック、分散表現ベース
続いて、k-meansやLDAやword2vecを用いて特徴量を作成する方法です。今回はk-means、ミニバッチk-means、LDA、FastTextによる分散表現を扱います。
k-means、ミニバッチk-means
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
from sklearn.feature_extraction.text import CountVectorizer from sklearn import preprocessing from sklearn.cluster import KMeans, MiniBatchKMeans # word count feature countvector = CountVectorizer(min_df=0.01, max_df=0.90) matrix = countvector.fit_transform(corpus_data.text_wakati) # 標準化 my_scalar = preprocessing.StandardScaler() my_scalar.fit(pd.DataFrame(matrix.toarray())) matrix_std = my_scalar.transform(pd.DataFrame(matrix.toarray())) n_clusters = 15 kmeans = KMeans(n_clusters=n_clusters) minibatch = MiniBatchKMeans(n_clusters=n_clusters) kmeans.fit(matrix_std.transpose()) minibatch.fit(matrix_std.transpose()) # k-means X = kmeans.cluster_centers_.transpose() y = corpus_data.designer_flag.values n_samples, n_features = X.shape print(n_features) random_state = np.random.RandomState(0) classifier = RandomForestClassifier(random_state=random_state) # classification and draw roc curve classification_and_roc_analysis(k=10, classifier=classifier, X=X, y=y) # ミニバッチk-means X = minibatch.cluster_centers_.transpose() y = corpus_data.designer_flag.values n_samples, n_features = X.shape print(n_features) random_state = np.random.RandomState(0) classifier = RandomForestClassifier(random_state=random_state) # classification and draw roc curve classification_and_roc_analysis(k=10, classifier=classifier, X=X, y=y) |
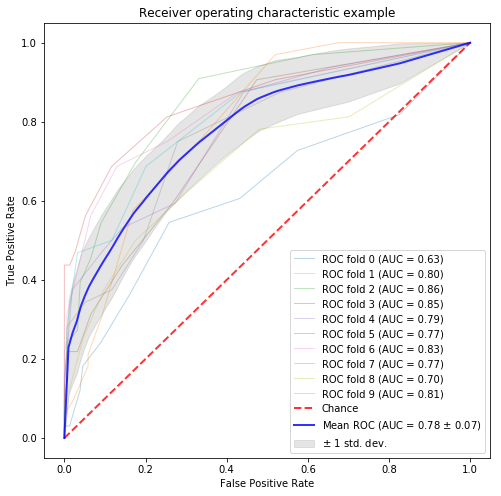
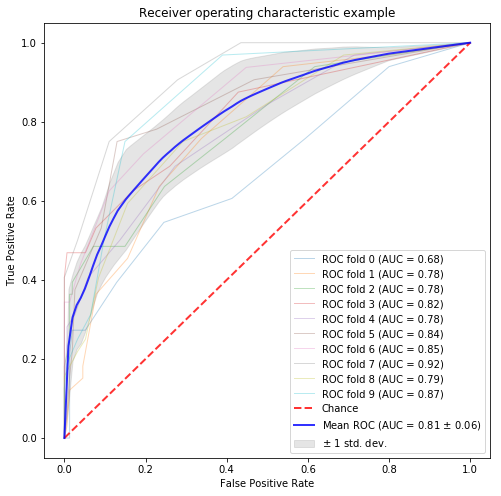
LDA
こちらはgensimでLDAを推定し、推定したトピックの割合をデータフレームで返すコードです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
from gensim import corpora, models import gensim import pickle # データフレームのテキストデータをもとに、gensimで読み込み可能なフォーマットに変換するための関数 def nested_list(strings): words = strings.split(" ") return words # トピック割合を格納するためのデータフレームを作成する関数 def making_topic_detaframe(integer, n): topic_table = pd.DataFrame(index=n.index) for topic_number in range(integer): column_name = "topic" + str(topic_number) topic_table[column_name] = 0 return topic_table # トピック割合を格納する関数 def topic_ratio_extract(corpus, topic_table): n_topic = len(topic_table.columns) i = 0 for bow in corpus: t = lda.get_document_topics(bow) for each_topic in t: for topic_id in range(n_topic): if each_topic[0] == topic_id: topic_table.iloc[i, topic_id] = each_topic[1] i = i + 1 return topic_table corpus_data_filtered = corpus_data.query(' text_wakati !="" ').reset_index(drop=True) corpus_data_filtered["text_wakati_fixed"] = list(map(lambda text:nested_list(text) ,corpus_data_filtered.text_wakati)) dictionary = gensim.corpora.Dictionary(corpus_data_filtered["text_wakati_fixed"]) dictionary.save_as_text('text.dict') corpus = [dictionary.doc2bow(doc) for doc in corpus_data_filtered["text_wakati_fixed"]] gensim.corpora.MmCorpus.serialize('text.mm', corpus) tfidf = gensim.models.TfidfModel(corpus) corpus_tfidf = tfidf[corpus] with open('corpus_tfidf.dump', mode='wb') as f: pickle.dump(corpus_tfidf, f) |
トピック数をとりあえず30個くらいに指定して推定したトピックの割合を特徴量として文書分類を行います。そのため、特徴量の数は30個になります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
the_number_of_topic = 30 lda = gensim.models.ldamodel.LdaModel( corpus=corpus, alpha='asymmetric', eta = 'auto', num_topics=the_number_of_topic, id2word=dictionary, random_state=123 ) # トピックの数に応じたデータフレームを作成 topic_table = making_topic_detaframe(the_number_of_topic, corpus_data_filtered) # 推定したトピックごとの文書ごとの確率を格納 topic_table = topic_ratio_extract(corpus, topic_table) # 元データとトピックテーブルを結合 corpus_data_filtered_with_topic = pd.concat([corpus_data_filtered, topic_table], axis=1) # 実数に変換 corpus_data_filtered_with_topic[list(topic_table.columns)] = corpus_data_filtered_with_topic[list(topic_table.columns)].astype("float") X = corpus_data_filtered_with_topic.filter(regex="topic").values y = corpus_data.designer_flag.values n_samples, n_features = X.shape print(n_features) random_state = np.random.RandomState(0) classifier = RandomForestClassifier(random_state=random_state) # classification and draw roc curve classification_and_roc_analysis(k=10, classifier=classifier, X=X, y=y) |
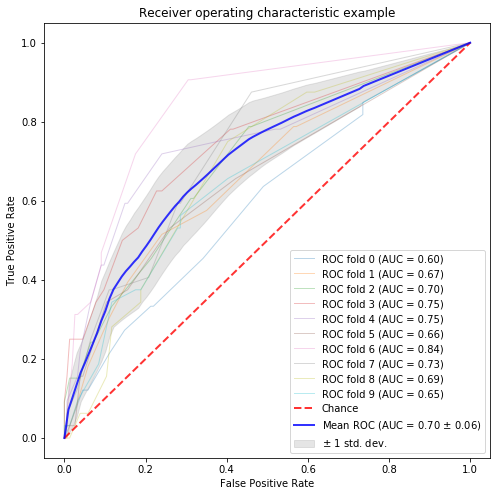
FastTextによる分散表現
今回はデータ数が少ないことから、学習済みの分散表現を用います。日本語のコーパスに対して、FastTextで推定された分散表現となります。学習済み分散表現はこちらから拝借しました。
|
1 2 3 4 5 |
import gensim.models.keyedvectors as word2vec_for_txt # 少し時間がかかる model_fasttext = word2vec_for_txt.KeyedVectors.load_word2vec_format('model.vec', binary=False) w2v_fasttext = {w: vec for w, vec in zip(model_fasttext.wv.index2word, model_fasttext.wv.syn0)} |
分散表現は単語に対して計算されるので、単語に対して分散表現を足し合わせたものを特徴量として扱います。ここでは分散表現の合計値、平均値、TF-IDFで重みを付けた平均値の3つのパターンを試します。
合計値ベース
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 合計値ベース X = [token.split(" ") for token in corpus_data.text_wakati] X = np.array([ np.sum([w2v_fasttext[w] for w in words if w in w2v_fasttext] \ or [np.zeros(next(iter(w2v_fasttext.values())).size)], axis=0) for words in X]) y = corpus_data.designer_flag.values n_samples, n_features = X.shape print(n_features) random_state = np.random.RandomState(0) classifier = RandomForestClassifier(random_state=random_state) # classification and draw roc curve classification_and_roc_analysis(k=10, classifier=classifier, X=X, y=y) |
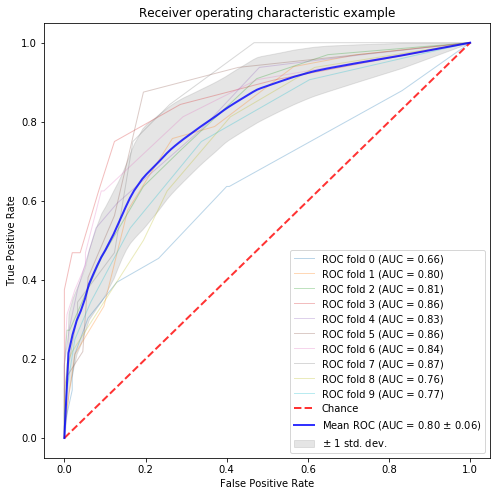
平均値ベース
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 平均値 X = [token.split(" ") for token in corpus_data.text_wakati] X = np.array([ np.mean([w2v_fasttext[w] for w in words if w in w2v_fasttext] \ or [np.zeros(next(iter(w2v_fasttext.values())).size)], axis=0) for words in X]) y = corpus_data.designer_flag.values n_samples, n_features = X.shape print(n_features) random_state = np.random.RandomState(0) classifier = RandomForestClassifier(random_state=random_state) # classification and draw roc curve classification_and_roc_analysis(k=10, classifier=classifier, X=X, y=y) |
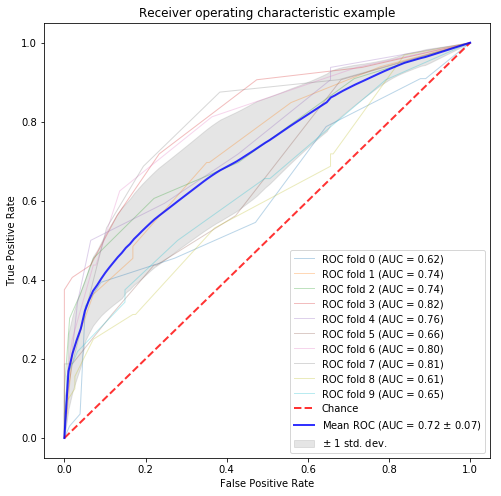
TF-IDFで単語を重みづけた平均値ベース
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# TF-IDFベース from sklearn.feature_extraction.text import TfidfVectorizer from collections import defaultdict # TF-IDF値の計算 tfidf = TfidfVectorizer() tfidf.fit(corpus_data.text_wakati) max_idf = max(tfidf.idf_) # TF-IDFの値を重み付けの係数として格納 word2weight = None word2weight = defaultdict(lambda: max_idf, [(w, tfidf.idf_[i]) for w, i in tfidf.vocabulary_.items()]) # 分散表現の抽出 X = [token.split(" ") for token in corpus_data.text_wakati] X = np.array([np.mean([w2v_fasttext[w] * word2weight[w] for w in words if w in w2v_fasttext] \ or [np.zeros(next(iter(w2v_fasttext.values())).size)], axis=0) for words in X ]) y = corpus_data.designer_flag.values n_samples, n_features = X.shape print(n_features) random_state = np.random.RandomState(0) classifier = RandomForestClassifier(random_state=random_state) # classification and draw roc curve classification_and_roc_analysis(k=10, classifier=classifier, X=X, y=y) |
文書間の類似度ベース
今回は、デザイナーズマンションの定義文に似ているかどうかという観点で類似度ベースの特徴量を作ってみたいと思います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.metrics.pairwise import cosine_similarity designer_definition = "デザイナーズ物件というと、連想されがちなのが「コンクリート打ちっぱなしの外壁」に代表されるスタイリッシュなデザインの建物。\ でも、それだけではありません。全く間仕切りがないワンルーム、螺旋階段が部屋の中にある部屋など、\ 普通の物件では考えられない設備やデザインが魅力です。また、キッチンが部屋の真ん中に配置されていたり、\ バスやトイレがガラス張りであったり、洗濯機や電子レンジを収める収納スペースで生活感を出さない構造であったりすることも。\ インテリアや家具までレイアウトされている部屋が多いのも特徴です。こうした一風変わった造りは、\ デザイナーや建築家のこだわりやコンセプトが反映されています。そのため、デザイナーズ物件は建築家やデザインの\ 「作品」と言うこともできます。そうした作品に住むことは憧れであり、ある種のステイタスと言えるでしょう。" designer_definition_wakati = nouns_extract(designer_definition) text_list = list(set(corpus_data.text_wakati)) text_list.extend(designer_definition_wakati ) # TF-IDFの計算 vectorizer = TfidfVectorizer() vectorizer.fit_transform(text_list) # これで更新 # 類似度の計算 corpus_data["cos_sim"] = list(map(lambda number: cosine_similarity(vectorizer.transform([corpus_data.text_wakati[number]]), vectorizer.transform([designer_definition_wakati]))[0][0] , range(corpus_data.index.size))) bins = [0.00, 0.01, 0.03,0.05, 0.10,1.0] labels=["0~1%", "1~3%", "3~5%", "5~10%", "10%~"] corpus_data["cos_sim_bins"] = pd.cut(corpus_data.cos_sim, bins=bins, labels=labels, include_lowest=True) df = corpus_data.groupby("cos_sim_bins")[["designer_flag"]].mean().reset_index() ax = df.designer_flag.plot(xticks=df.index, rot=90, figsize=(10,5)) ax.set_xticklabels(df.cos_sim_bins); ax.set_ylabel("designer_flag"); ax.set_xlabel("cos_sim_bins"); |
今回は変数が一つだけなので、機械学習はせず、デザイナーズマンション割合との関係を図示するにとどめておきます。横軸がデザイナーズマンションの定義と施設情報の類似度で、縦軸がデザイナーズマンション割合です。
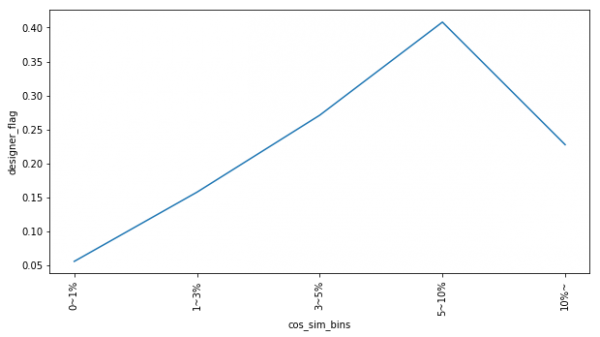
どうやら、途中でデザイナーズマンション割合がピークを迎えるようです。
おわりに
最先端の手法は調べれていないですが、テキストデータを特徴量に落とし込む手段を備忘録として残しておきました。今回あげた中では、SOAベースの特徴量選択のAUCが83%と一番高かったですが、ベースラインが82%と僅差でした。そして、分散表現形のものは80%に届いた程度です。余力があれば新しい特徴量の作り方が分かり次第アップデートしようと思います。
追記
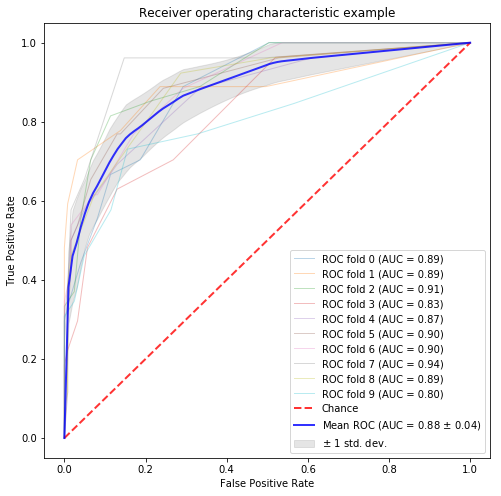
“Automate Stacking In Python How to Boost Your Performance While Saving Time”という記事を見つけたので、紹介されているvecstackモジュールを使って今回のモデルに関して簡単にstackingしてみようと思います。
コードに関しては、こちらのGitHubに上げています。試してみた所、AUCは88%になりました。結構上がりましたね。しかもコードはめちゃ短いので楽です。
参考文献
[1]Julian Avila et al(2019), 『Python機械学習ライブラリ scikit-learn活用レシピ80+』, impress top gear
[2]Receiver Operating Characteristic (ROC) with cross validation
[3]@Kensuke-Mitsuzawa(2016), “テキストデータで特徴量選択をする”, Qiita
[4]JapaneseTokenizer 1.6
[5]DocumentFeatureSelection 1.5
[6]自然言語処理における自己相互情報量 (Pointwise Mutual Information, PMI)
[7]【Techの道も一歩から】第3回「第11回テキストアナリティクス・シンポジウム」
[8]文書分類タスクでよく利用されるfeature selection