モチベーション
前回の記事では、Webスクレイピングにより入手した、蒙古タンメン中本の口コミデータに関して、Word2Vecを適用した特徴量エンジニアリングの事例を紹介しました。
今回はせっかく興味深いデータがあるので、どのようなトピックがあるのかをLDAを適用したいと思います。加えて、これまで記事で扱ってきたLDAの事例では評価指標であるPerplexityやCoherenceを扱ってこなかったことから、トピック数がどれくらいであるべきなのか、考察も含めて行いたいと思います。以前扱った階層ディリクレ過程であれば、トピック数を事前に決める必要が無いのですが、今回は扱わないものとします。
環境
・MacBook Pro
・Python3.5
・R version 3.4.4
Gensimで行うLDA
今回もPythonのGensimライブラリを用いて行います。
- パープレキシティ
- テストデータに対して計算
- 負の対数尤度で、低いほどよい。
- パープレキシティが低いと、高い精度で予測できるよい確率モデルと見なされる。汎化能力を表す指標。
- トピックの数をいくらでも増やせばパープレキシティは下がる傾向が出ている。
- 教科書でのパープレキシティの事例に関しては、トピック数を増やせば低くなるという傾向が出ている。
以下のコードでパープレキシティを計算します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
import pandas as pd from gensim import corpora, models import gensim as gensim import matplotlib.pyplot as plt import numpy as np from ipywidgets import FloatProgress from IPython.display import display, clear_output nakamoto_corpus = pd.read_pickle("nakamoto_corpus.pickle") output_list = pd.DataFrame(columns=["y","x"]) plt.ion() fig = plt.figure() axe = fig.add_subplot(111) for iterations in range(2, 100): clear_output(wait = True) nakamoto_test = nakamoto_corpus.sample(frac=0.1, replace=True) nakamoto_train= nakamoto_corpus[~nakamoto_corpus.index.isin(nakamoto_test.index)] texts = [ ] for line in nakamoto_train.text_wakati: texts.append(line.split()) texts_test = [ ] for line in nakamoto_test.text_wakati: texts_test.append(line.split()) # 辞書作成 dictionary = corpora.Dictionary(texts) dictionary.filter_extremes(no_below=20, no_above=0.3) # コーパスを作成 corpus = [dictionary.doc2bow(text) for text in texts] corpus_test = [dictionary.doc2bow(text) for text in texts_test] # LDA の計算 topic_N = 1 + iterations parameters = topic_N lda = gensim.models.ldamodel.LdaModel( corpus=corpus, alpha='auto', num_topics=topic_N, id2word=dictionary ) d = {'y':lda.log_perplexity(chunk=corpus_test),'x':parameters} df = pd.DataFrame(data=d,index=[0]) output_list = output_list.append(df) axe.plot(output_list.x,output_list.y) fig.set_size_inches(8, 8) display(fig) axe.cla() for i in range(topic_N): print('TOPIC:', i, '__', lda.print_topic(i)) |
実際に、中本コーパスで計算したトピック数に対してのパープレキシティは以下のように推移しました。
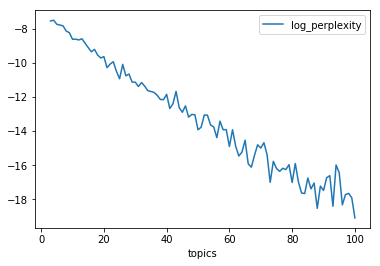
Ldaのモデル選択におけるperplexityの評価によると、
”複数のトピック数で比べて、Perplexityが最も低いものを選択する。」という手法は人間にとって有益なモデルを選択するのに全く役に立たない可能性がある。”と記されています。
『トピックモデルによる統計的潜在意味解析』には、”識別問題の特徴量として使う場合は識別問題の評価方法で決定すればよい”とあるので、目的によってはパープレキシティにこだわらなくても良いと思われます。
今回のケースだと、パープレキシティだけだと、決めかねてしまいますね。
- コヒーレンス
- トピックごとの単語間類似度の平均
- トピック全体のコヒーレンスが高ければ、良い学習アルゴリズムとみなす。
以下のコードでコヒーレンスを計算します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
output_list = pd.DataFrame(columns=["y","x"]) plt.ion() fig = plt.figure() axe = fig.add_subplot(111) for iterations in range(2, 100): clear_output(wait = True) nakamoto_test = nakamoto_corpus.sample(frac=0.1, replace=True) nakamoto_train= nakamoto_corpus[~nakamoto_corpus.index.isin(nakamoto_test.index)] texts = [ ] for line in nakamoto_train.text_wakati: texts.append(line.split()) texts_test = [ ] for line in nakamoto_test.text_wakati: texts_test.append(line.split()) # 辞書作成 dictionary = corpora.Dictionary(texts) dictionary.filter_extremes(no_below=20, no_above=0.3) # コーパスを作成 corpus = [dictionary.doc2bow(text) for text in texts] corpus_test = [dictionary.doc2bow(text) for text in texts_test] # LDA の計算 topic_N = 1 + iterations parameters = topic_N lda = gensim.models.ldamodel.LdaModel( corpus=corpus, alpha='auto', num_topics=topic_N, id2word=dictionary ) cm = models.coherencemodel.CoherenceModel(model=lda, corpus=corpus, coherence='u_mass') # tm is the trained topic model d = {'y':cm.get_coherence(),'x':parameters} df = pd.DataFrame(data=d,index=[0]) output_list = output_list.append(df) axe.plot(output_list.x,output_list.y) fig.set_size_inches(8, 8) display(fig) axe.cla() for i in range(topic_N): print('TOPIC:', i, '__', lda.print_topic(i)) |
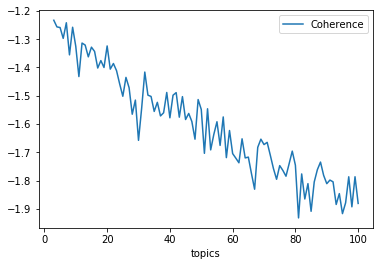
実際に推定してみたところ、トピック数が20を超えたあたりからコヒーレンスが下がる傾向があるので、
それ以上のトピック数は追い求めない方が良いのかもしれません。
Rでもやってみる
Rでトピック数を決める良い方法がないか調べてみたところ、ldatuningとかいうパッケージがあることがわかりました。複数の論文(Griffiths2004, CaoJuan2009, Arun2010,Deveaud2014)で扱われている手法を元に、適切なトピック数を探れるようです。このパッケージを紹介しているブログの事例では、90から140の範囲で最適なトピック数となることが示されています。詳しくはこちらを見てください。
Select number of topics for LDA model
以下のコードで実行しました。一部、驚異のアニヲタさんのコードを拝借しております。なお、ldaパッケージのlexicalize関数を用いることで、ldatuningに入力するデータを作成することができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
library(ldatuning) library(topicmodels) library(tidyverse) nakamoto_data <- read_csv(file = "nakamoto_dataset.csv") TFIDF <- function(corpus, progress=FALSE){ res <- matrix(0, nr=length(corpus$vocab), nc=4) dimnames(res) <- list(corpus$vocab, c("documents", "count", "freq", "score")) res[, "documents"] <- length(corpus$documents) wordset <- mapply(function(x) x[1,], corpus$documents) allfreq <- matrix(unlist(corpus$documents), nr=2) wordfreq <- tapply(allfreq[2,], allfreq[1,], sum) for(v in seq(corpus$vocab)){ count_docs <- sum(sapply(lapply(wordset, "==", v-1), any)) # res[v, "freq"] <- count_docs if(progress){ pb <- txtProgressBar(min=1, max=length(corpus$vocab), style=3) setTxtProgressBar(pb, v) } } res[, "count"] <- wordfreq res[, "score"] <- log(res[, "count"]) * log(res[, "documents"]/res[, "freq"]) return(as.data.frame(res)) } lex1 <- lda::lexicalize(nakamoto_data$text_wakati_remove_freq) s0 <- TFIDF(lex1, TRUE) term1 <- rownames(s0)[s0$score > 0] lex2 <- list(documents=lda::lexicalize(nakamoto_data$text_wakati_remove_freq, vocab=term1), vocab=term1) dtm2 <- ldaformat2dtm(lex2$documents, lex2$vocab) result <- FindTopicsNumber( dtm2, topics = seq(from = 2, to = 100, by = 1), metrics = c("Griffiths2004", "CaoJuan2009", "Arun2010", "Deveaud2014"), method = "Gibbs", control = list(seed = 77), mc.cores = 2L, verbose = TRUE ) FindTopicsNumber_plot(values = result) |
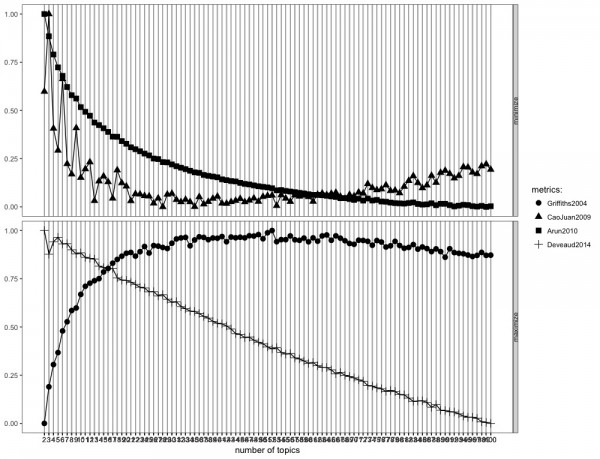
これを見る限りは、60〜70個の辺りに落ち着くのでしょうか。
トピックの吐き出し
Rでの結果から、60個程度のトピックで推定し、各記事に割り当てが最大のトピックを付与して、トピック別の口コミ評価をみてみようと思います。
以下のコードではトピック別の口コミ評価のしやすさからtopicmodelsパッケージを用いた推定となっています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
nbo_topics <- 60 lda_estimate <- topicmodels::LDA(dtm2,control=list(verbose=1, alpha = 0.1), k = nbo_topics, method = "Gibbs") #トピックの上位5単語を確認する terms_each_topics <- data.frame(terms(lda_estimate,5)) topic_keywords <- data.frame(topic_keywords_5 = apply(t(terms_each_topics),1,paste,collapse=",")) topic_keywords <- topic_keywords %>% mutate(topic_id=1:n()) #割り振られた最大の確率のトピックを抽出し、口コミデータと統合する topics_each_document <- data.frame(topic_id=topics(lda_estimate,1)) topics_each_document <- nakamoto_data %>% bind_cols(topics_each_document) #トピックごとの口コミ評価を計算する topic_rating_summary <- topics_each_document %>% group_by(topic_id) %>% summarise(average_rating = mean(rating), count=n()) %>% left_join(topic_keywords, by = "topic_id") %>% arrange(desc(average_rating)) |
口コミ評価の点数が上位のトピックはこんな感じです。

口コミ評価の点数が下位のトピックはこんな感じです。
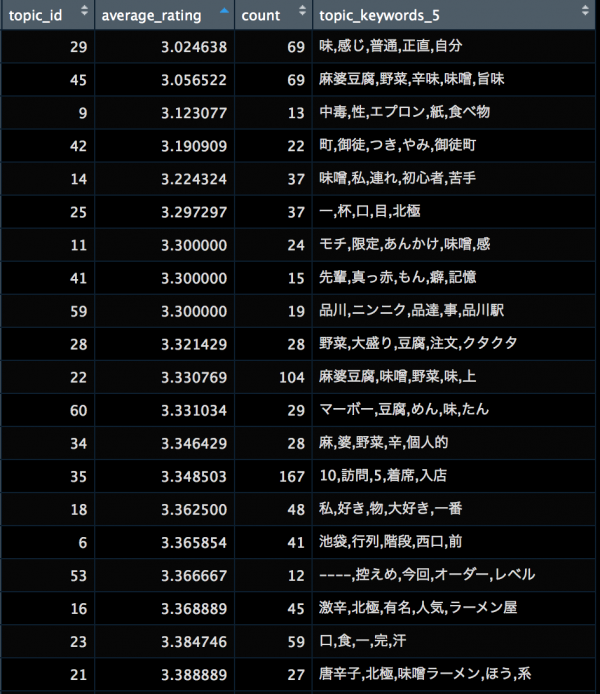
中本は社会人2〜3年目で新規メディアの立ち上げのストレス解消で数回行きましたが、北極の赤さは異常だと思います。北極を食べたり、トッピングする余裕のある人、ましてや辛さを倍にするという時点で口コミ評価も高くなると考えるのは自然なのかもしれません。
参考情報
トピックモデル (機械学習プロフェッショナルシリーズ)
トピックモデルによる統計的潜在意味解析 (自然言語処理シリーズ)
models.ldamodel – Latent Dirichlet Allocation
Ldaのモデル選択におけるperplexityの評価
pythonでgensimを使ってトピックモデル(LDA)を行う
gensim0.8.6のチュートリアルをやってみた【コーパスとベクトル空間】
LDA 実装の比較
Jupyter notebookにMatplotlibでリアルタイムにチャートを書く
Inferring the number of topics for gensim’s LDA – perplexity, CM, AIC, and BIC
Select number of topics for LDA model
47の心得シリーズをトピックモデルで分類する。 – 驚異のアニヲタ社会復帰への道