はじめに
仕事で使いそうなPythonのコードを残しておくドキュメントが欲しいなと思ったので、よく使うものをこちらに貯めていこうと思います。まだ19個しかないですが、30個を目標に追記していきます。
フォーマットとしては、
1.やりたい処理
2.コード
3.参考情報のリンク
の3つを1セットにしています。
まずは、自分自身や周りで仕事をしている人が楽をできるドキュメントになればいいなと思って作っていきます。
目次
・重複削除
・階級のデータを作りたい
・再起的にリストをコピーしたい
・ピボットテーブルでアクセスログから特徴量用のデータを作りたい
・データフレームのある列に対して特定の文字列で分割し、その任意のN番目のものを抽出したい
・データフレームの行単位で割り算を行いたい
・列単位で行を足し合わせて文字列を作りたい
・グループのレコードごとにidを割り当てたい
・正規表現で任意の合致した文字列で挟まれた文字列を抽出したい
・複数列の集計値同士で除した値が欲しい
・等間隔の実数の数列を作成したい
・スペース区切りの文字列において、ある単語の前後N個の語を抽出したい
・グループごとに文字列を結合したい
・文字列の置換をdict形式のデータで行いたい
・テキストを形態素解析してBoW形式のデータにして特徴量にしたい
・訓練データとテストデータで特徴量の数が足りない時に不足した変数を追加したい
・アクセスログのユーザーごとのレコードごとの累積和を計算したい
・選択したカラムで一気にダミー変数にしたい
・グループ化して平均値を計算し、プロットし、2軸でそれぞれのデータ数も載せたい
・参考情報
データセット
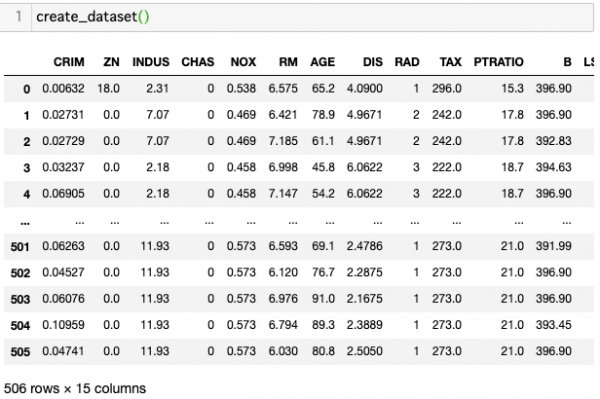
全体を通じて使うデータセットを生成する関数を用意しておきます。一つ目の
データはkaggleのBoston Housingのデータセットです。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# import pandas as pd def create_dataset(): df = pd.read_csv('https://raw.githubusercontent.com/rasbt/' 'python-machine-learning-book-2nd-edition/' 'master/code/ch10/housing.data.txt', header=None, sep='\s+') df.columns = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV'] df["id"] = df.index return df |
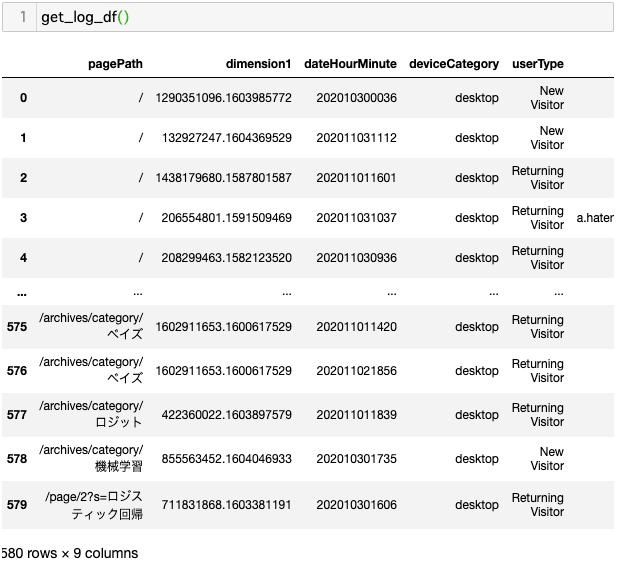
二つ目はアクセスログのデータが欲しかったので、Google Analytics APIを使ってデータを抽出したものとなります。ここではソースコードを載せますが、皆さんは当然見れません。一応、GitHubにデータを上げておきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
# from apiclient.discovery import build from oauth2client.service_account import ServiceAccountCredentials # AnalyticsAPIで取りたいものを指定する def get_logs(service, profile_id): return service.data().ga().get( ids='ga:' + profile_id, start_date='7daysAgo', end_date='today', dimensions = "ga:pagePath,ga:dimension1,ga:dateHourMinute,ga:deviceCategory,ga:userType,ga:fullReferrer", sort = "-ga:sessions", metrics = "ga:sessions,ga:goal1Completions,ga:pageviews").execute() def get_service(api_name, api_version, scopes, key_file_location): credentials = ServiceAccountCredentials.from_json_keyfile_name( key_file_location, scopes=scopes) service = build(api_name, api_version, credentials=credentials) return service # Google Analyticsの見たいビューなどを指定して、アクセスログを抽出する def get_log_df(): scope = 'https://www.googleapis.com/auth/analytics.readonly' # 認証用のjsonファイルの置き場所 key_file_location = '../perry_project/credential_key.json' service = get_service( api_name='analytics', api_version='v3', scopes=[scope], key_file_location=key_file_location) # Google Analyticsのアカウント。1つしか持っていないので0で指定する。 accounts = service.management().accounts().list().execute() account = accounts.get('items')[0].get('id') # プロパティは複数あるので、検索する必要がある。 properties = service.management().webproperties().list( accountId=account).execute() for i in properties['items']: if i['name']=="かものはしの分析ブログ": property = i['id'] # プロファイルまで行って、ようやくアクセスログを抽出できる。 profiles = service.management().profiles().list( accountId=account, webPropertyId=property).execute() # プロファイルのIDがAPIを叩く時に必要となる。 profile_id = profiles.get('items')[0].get('id') # データフレームの形でアクセスログを取得 df = pd.DataFrame(get_logs(service, profile_id)['rows']) df.columns = ['pagePath', 'dimension1', 'dateHourMinute', 'deviceCategory', 'userType', 'fullReferrer', 'sessions', 'goal1Completions', 'pageviews'] return df |
三つ目はテキストデータです。
|
1 2 3 4 5 |
def create_text_dataset(): df = pd.DataFrame(["フィニアスとファーブのペットのカモノハシ。なぜ水色の体なのかはツッコんではいけない。普段は何をしても反応しないノロノロした奴だが、陰でモノグラム少佐の指令のもとでエージェントPとして活動している。スパイとしての名前はエージェントP。(agent P)普段の姿からエージェントPになる時の性格と顔の変わりようが異常である。カモノハシなので当然人間語は話せず、「ガガガガガ」(もしくは「グルルルル」)という歯を鳴らすような奇妙な鳴き声で鳴く。フィニアス達の家の真下には、少佐から任務を聞いたりするための秘密の部屋があり、家の所どころにその部屋へ通じる隠し扉がある。ドゥーフェンシュマーツ博士が宿敵であり、彼の悪の企みを暴き、その計画を阻止するのがエージェントPの任務である。毎回博士の罠に掛かるが、自力かもしくは博士の間抜けなミスにより脱出する。", "ペリーはフィニアスとファーブに大事に飼われているペットのカモノハシ。うたたねをしていることが多い。何もかんがえていないかのように見えるが「ぼんやりした ただのペット」というのは世を忍ぶ仮の姿で本当はエージェントPとよばれる優秀なスパイで、世界を救っているのだ。"], columns=["document"]) return df |
前処理
- やりたいこと
重複したデータを除外したい。最初に現れたレコードだけを残したい。 - コード
1234567#df = create_dataset()df = pd.concat([df, df],axis=0) # わざとデータを重複させる。print(df.shape)df = df[~df.duplicated(subset=["id"], keep='first')].reset_index(drop=True) # 最初に登場したidのレコードだけを抽出。print(df.shape) - 参考情報
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.duplicated.html
- やりたいこと
任意の範囲に応じたラベルをつけた階級値を作りたい。 - コード
123456789101112#df = create_dataset()bins = [0,14,30,50,80]labels=["0~13","14~29","30~49","50~79"]df['AGE_bins'] = pd.cut(df['AGE'],bins=bins,labels=labels,include_lowest=True)df.AGE_bins.value_counts(normalize=True).round(2) - 参考情報
https://pandas.pydata.org/docs/reference/api/pandas.cut.html
- やりたいこと
リストをコピーした際に、コピーしたものを変更した際に、もとのものも変更されてしまうので、それを防ぎたい。 - コード
12345678910111213141516171819#df = create_dataset()# 上書きされるケースid_list = df.id.tolist()id_list2 = id_listid_list2[0] = 100print(id_list[0])print(id_list2[0])# 上書きされないケースimport copyid_list = df.id.tolist()id_list_2 = copy.deepcopy(id_list)id_list2[0] = 100print(id_list[0])print(id_list2[0]) - 参考情報
https://docs.python.org/3/library/copy.html
- やりたいこと
集計されていないアクセスログをもとに、セッションidごとの触れたページを集計し、Bag of Words形式のデータフレームにしたい。これは機械学習の特徴量に使えるので便利。 - コード
12345678910111213#df = get_log_df()df_pv = pd.pivot_table(data=df,fill_value=0,index="dimension1",columns="pagePath",aggfunc = {"pagePath":"count"}).reset_index()column_list = [df_pv.columns.levels[0][1]]column_list.extend(df_pv.columns.levels[1].tolist()[:-1])df_pv.columns = column_listdf_pv.head(10) - 参考情報
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.pivot_table.html
- やりたいこと
pandasのデータフレームである文字列の列に対して特定のキーワードで分割し、そのN番目のものをデータフレームの列として持たせる。今回はURLのパラメータの後ろについている文字列を抽出している。 - コード
123456789#df = get_log_df()keyword = "\?s="n_element = 1df = df[df.pagePath.str.contains(keyword)]df["expression"] = df.pagePath.str.split(keyword).apply(lambda x: x[n_element])df[['pagePath', 'dimension1', 'expression']] - 参考情報

- やりたいこと
各行の合計で、各行を割ることでレコード単位で重み付けを行いたい時や確率を計算したいときに良く使います。データはアクセスログをBag of Word形式したものを使います。 - コード
123456789101112# さきほどと同じdf = get_log_df()df_pv = pd.pivot_table(data=df,fill_value=0,index="dimension1",columns="pagePath",aggfunc = {"pagePath":"count"}).apply(lambda x:x/sum(x),axis=1).reset_index()column_list = [df_pv.columns.levels[0][1]]column_list.extend(df_pv.columns.levels[1].tolist()[:-1])df_pv.columns = column_list - 参考情報
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.div.html
- やりたいこと
データフレームの列の要素をつなぎ合わせて文字列を作成したい。複合キーを作らないとデータを繋げない時などによく使います。 - コード
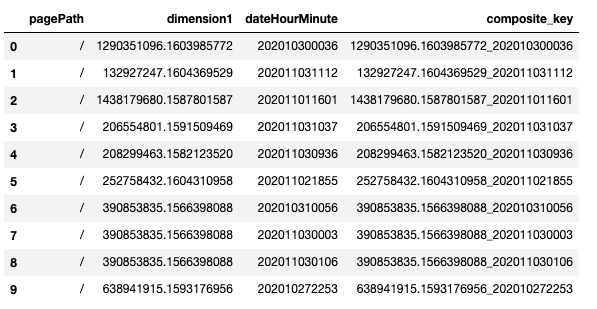
12345#df = get_log_df()df['composite_key'] = df[['dimension1', 'dateHourMinute']].apply(lambda x: '{}_{}'.format(x[0], x[1]), axis=1)df[['pagePath','dimension1','dateHourMinute', 'composite_key']].head(10) - 参考情報
https://www.kato-eng.info/entry/pandas-concat-pk
- やりたいこと
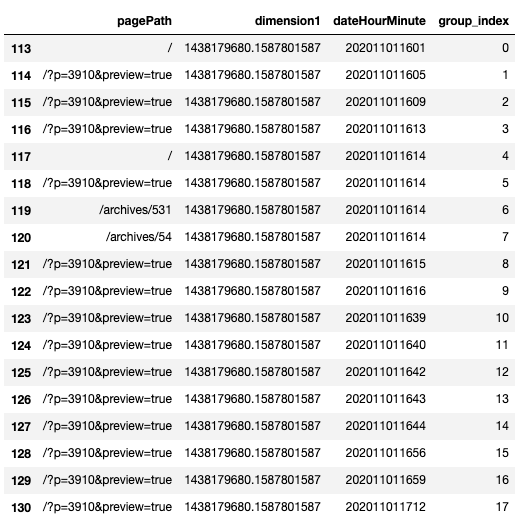
アクセスログなどで、任意のユーザーの初回に触れたページや、N番目に触れたページなどを抽出しやすいように、ユーザーごとのログにidを付与したい。 - コード
1234567891011121314#df = get_log_df()# グループごとに時刻の昇順で並び替える。df = df.sort_values(by=['dimension1', 'dateHourMinute'], ascending=True).reset_index(drop=True)# ユニークな変数を使う必要があるので、インデックスを列で持つ。df["const"] = df.index# グループごとにインデックスを付与していく。df["group_index"] = df.groupby('dimension1')['const'].transform(lambda x: pd.factorize(x)[0])most_heavy_user = df.dimension1.value_counts()[[0]].index[0]df[df.dimension1 == most_heavy_user][['pagePath', 'dimension1','dateHourMinute','group_index']] - 参考情報
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.factorize.html
- やりたいこと
正規表現を用いて、文字列に対して「指定した文字列と文字列の間にある表現」を抽出するための処理です。URLのデータや規則性のあるテキストデータに対して特徴量を作りたい時に使えます。 - コード
12345678910#df = get_log_df()import numpy as npimport retarget_expression = '/?p=(.+?)&preview=true'df['extract_number'] = [re.search(target_expression, i).group(1) if re.search(target_expression, i) else np.nan for i in df.pagePath ]df[~df.extract_number.isna()][['pagePath', 'extract_number']].head(10) - 参考情報
https://docs.python.org/ja/3/library/re.html

- やりたいこと
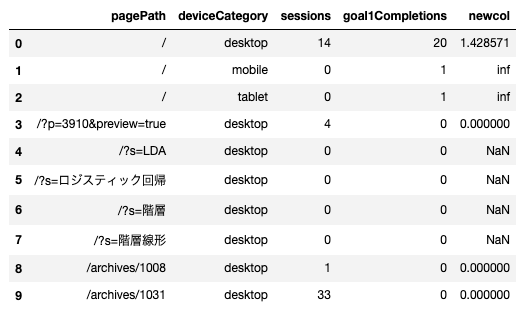
複数の列で集計した値同士を用いて、さらにそこから比率のデータを作りたい。ターゲットエンコーディングを行いたい場合に使える。 - コード
12345678910111213#df = get_log_df()# 複数の列をまとめて型の変換を行う。cols = ['sessions', 'goal1Completions', 'pageviews']df[cols] = df[cols].astype(int)# pagePathとdeviceCategoryごとにsessionsとgoal1Completionsを集計し、それらを除す。df_summary = df.groupby(['pagePath','deviceCategory'])\.agg({'sessions': np.sum,'goal1Completions':np.sum})\.assign(newcol=lambda x: x['goal1Completions']/x['sessions']).reset_index()df_summary.head(10) - 参考情報
https://stackoverflow.com/questions/45075626/summarize-using-multiple-columns-in-python-pandas-dataframe
- やりたいこと
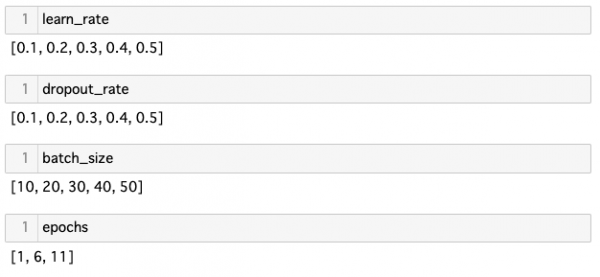
パラメータチューニングをする際に、各パラメータについて等間隔の実数列を作りたいときがあるので、その時に使うコード。 - コード
1234567891011#def frange(start, stop, step):i = startwhile i < stop:yield ii += steplearn_rate = list(map(lambda value:round(value,2) , frange(0.1, 0.6, 0.1)))dropout_rate = list(map(lambda value:round(value,2) , frange(0.1, 0.6, 0.1)))batch_size = list(map(lambda value:round(value,2) , frange(10, 51, 10)))epochs = list(map(lambda value:round(value,2) , frange(1, 12, 5))) - 参考情報
https://www.pythoncentral.io/pythons-range-function-explained/
- やりたいこと
テキストマイニングをする際に、関心のある単語の前後N文字を抽出したい時がある。もちろん、関心のある単語の周辺の単語というものを特徴量にすることも良いと思われる。ここではMeCabによる形態素解析により分かち書きにする関数と共に紹介する。 - コード
12345678910111213141516171819202122232425262728293031#df = create_text_dataset()import reimport MeCabdef nouns_extract(line):keyword=[]m = MeCab.Tagger("-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd/")for l in m.parse(line).splitlines():if l != 'EOS' and l.split("\t")[1].split(",")[0] == "名詞":if l != 'EOS' and re.search("^一般$|^形容動詞語幹$|^サ変接続$|^副詞可能$|^固有名詞$",l.split("\t")[1].split(",")[1]):keyword.append(l.split("\t")[0])keyword = str(keyword).replace("', '"," ")keyword = keyword.replace("\'","")keyword = keyword.replace("[","")keyword = keyword.replace("]","")return keyworddf['nous_wakati'] = list(map(lambda text:nouns_extract(text) ,list(df.document)))target_word = "エージェントP"window_size = 5df["neighbor_words"] = list(map(lambda text:search(text,window_size,target_word) ,df['nous_wakati']))df - 参考情報
https://stackoverflow.com/questions/17645701/extract-words-surrounding-a-search-word

- やりたいこと
テキストマイニングなどで、任意のグループごとのテキストデータをスペース区切りで繋ぎたいときがあります。任意のグループごとのテキストを一気に連結できて便利です。これを形態素解析して特徴量にするのも良いと思います。 - コード
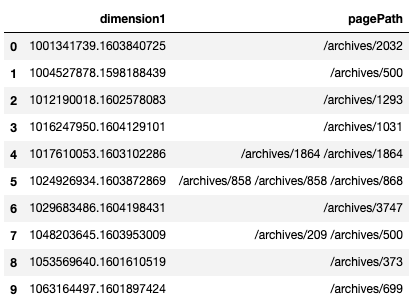
12345#df = get_log_df()df_concat = pd.DataFrame(df.groupby('dimension1')['pagePath'].apply(lambda x: ' '.join(x))).reset_index()df_concat.head(10) - 参考情報
https://stackoverflow.com/questions/17841149/pandas-groupby-how-to-get-a-union-of-strings
- やりたいこと
事前に用意した置換のリストを使って、文字列の置換を一気に行いたい。 - コード
12345678910111213141516171819202122232425262728#df = create_text_dataset()import redef multiple_replace(text, adict):rx = re.compile('|'.join(adict))def dedictkey(text):for key in adict.keys():if re.search(key, text):return keydef one_xlat(match):return adict[dedictkey(match.group(0))]return rx.sub(one_xlat, text)replace_list = {'カモノハシ':'鴨嘴','ペット':'家畜','エージェントP':'探偵','スパイ':'罪人','ペリー':'彼理'}df['document_fixed'] = list(map(lambda text:multiple_replace(text, replace_list) ,df['document']))df - 参考情報
http://omoplatta.blogspot.com/2010/10/python_30.html

- やりたいこと
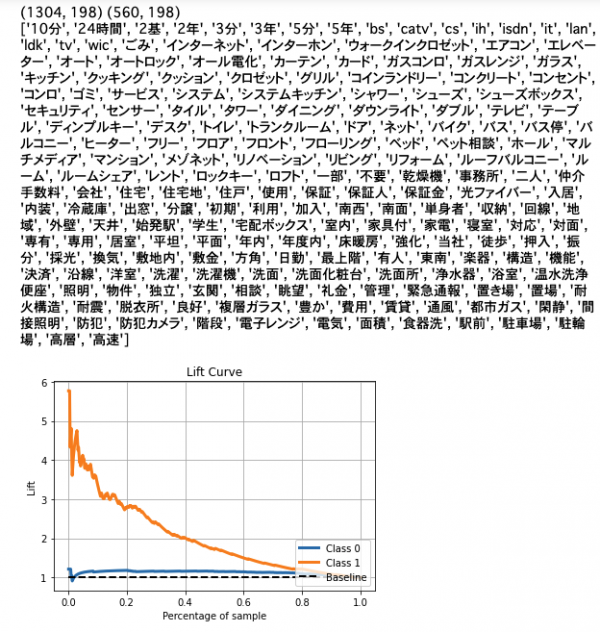
任意の日本語のテキストとラベルの組み合わせがあるとして、テキストを形態素解析してTF-IDFを計算し、それを特徴量としてラベルを予測するということをやりたい。ここでは以前集めて、GitHubに載せてあるデザイナーズマンションのデータを使い、MeCabで形態素解析をしたあとに、TF-IDFを計算し、それを特徴量にしてsklearnで簡単に予測をし、リフト曲線を描いている。 - コード
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253#import reimport MeCabdef nouns_extract(line):keyword=[]m = MeCab.Tagger("-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd/")for l in m.parse(line).splitlines():if l != 'EOS' and l.split("\t")[1].split(",")[0] == "名詞":if l != 'EOS' and re.search("^一般$|^形容動詞語幹$|^サ変接続$|^副詞可能$|^固有名詞$",l.split("\t")[1].split(",")[1]):keyword.append(l.split("\t")[0])keyword = str(keyword).replace("', '"," ")keyword = keyword.replace("\'","")keyword = keyword.replace("[","")keyword = keyword.replace("]","")return keyworddf = pd.read_csv("https://raw.githubusercontent.com/KamonohashiPerry/kamonohashiperry.com/master/designers_apartment/designers_apartment.csv")df.text = df.text.str.replace("デザイナーズ", "")df['nous_wakati'] = list(map(lambda text:nouns_extract(text) ,list(df.text)))df.head(3)from sklearn.model_selection import train_test_splitfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.linear_model import LogisticRegressionimport scikitplot as skpltX_train, X_test, y_train, y_test = train_test_split(df['nous_wakati'],df.designer_flag,test_size=0.3, random_state=1,stratify=df.designer_flag )vectorizer = TfidfVectorizer(min_df=20)# 訓練データでvectorizerを計算するX_train_vec = vectorizer.fit_transform(X_train)# テストデータにvectorizerを適用するX_test_vec = vectorizer.transform(X_test)print(X_train_vec.shape, X_test_vec.shape)print(vectorizer.get_feature_names())lr = LogisticRegression(C=100.0,random_state=1)lr.fit(X_train_vec, y_train)y_probas = lr.predict_proba(X_test_vec)# リフト曲線(縦軸は倍率になっている。)skplt.metrics.plot_lift_curve(y_test, y_probas); - 参考情報
https://scikit-plot.readthedocs.io/en/stable/metrics.html
- やりたいこと
訓練データとテストデータの変数の数が違う時に、そのままではモデルを使えないので、補うために使う。 - コード
1234567891011## 訓練データの列名を残しておくtrain_column_list = train_df.columns# 訓練データにはあるが、テストデータにはない変数を0で生成させるcompensate_list = list(set(train_column_list) - set(test_df.columns))if compensate_list != []:for each_column in compensate_list:test_df[each_column] = 0.0test_df = test_df[train_column_list] - 参考情報
なし
- やりたいこと
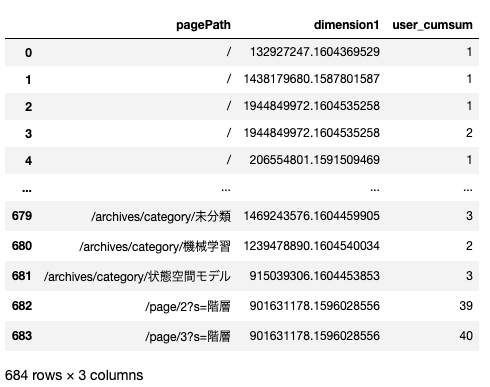
アクセスログや購買データなどで、レコードごとの累積の値を計算したいときに使う。時系列に従いどんどん足されていく。 - コード
1234567#df = get_log_df()df['view_count'] = 1df['user_cumsum'] = df.groupby('dimension1').cumsum()['view_count']df[['pagePath', 'dimension1', 'user_cumsum']].head(10) - 参考情報
https://ohke.hateblo.jp/entry/2018/05/05/230000
- やりたいこと
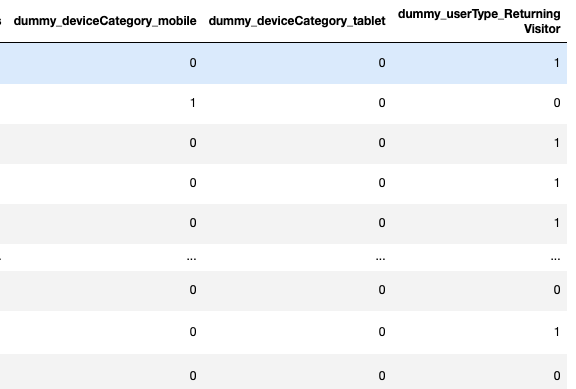
ダミー変数を一気に生成したい。名前も一気に付けたい。 - コード
123456789101112131415#df = get_log_df()# 一気にカテゴリ化cols = ["deviceCategory", "userType"]df[cols] = df[cols].astype('category')# ダミー変数を一気に作るfor each_columns in cols:dummy_df = pd.get_dummies( df[each_columns], drop_first=True)dummy_df.columns = ["dummy_" + each_columns + "_" + str(i) for i in dummy_df.columns.tolist()]df = pd.concat([df,dummy_df], axis=1) - 参考情報
なし
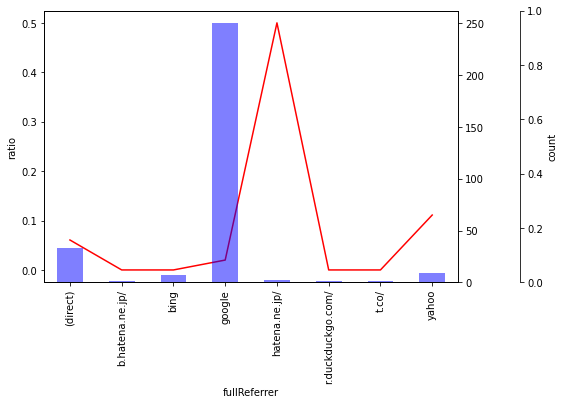
- やりたいこと
EDAの時に、グループ化して平均値などを計算するだけでなく、該当するデータ数も2軸でプロットしたい。 - コード
123456789101112131415161718192021222324252627282930313233343536373839#df = get_log_df()df.goal1Completions = df.goal1Completions.astype(int)import matplotlib.pyplot as pltimport numpy as npimport pandas as pd# 後でデータの型を指定しておくdef GroupbyPlot(df:pd.DataFrame,group:str,target:str,y_label:str,x_label:str):group_name_summary = df.groupby(group)[target].agg([np.mean, "count"])index_list = group_name_summary.index.tolist()group_name_summary = group_name_summary.reset_index()fig, ax = plt.subplots(figsize=(10,5))ax3 = ax.twinx()rspine = ax3.spines['right']rspine.set_position(('axes', 1.15))ax3.set_frame_on(True)ax3.patch.set_visible(False)fig.subplots_adjust(right=0.7)group_name_summary["mean"].plot(ax=ax, style='r-', kind="line")group_name_summary["count"].plot(ax=ax, secondary_y=True,kind="bar",color='b',alpha=0.5 );# ax.set_title('');ax.set_ylabel(y_label);ax.set_xlabel(x_label);ax.set_xticklabels(index_list);ax3.set_ylabel('count');return group_name_summarytarget_string = "fullReferrer"df_summary = GroupbyPlot(df,group=target_string,target="goal1Completions", y_label="ratio", x_label=target_string) - 参考情報
なし
参考情報
前処理大全[データ分析のためのSQL/R/Python実践テクニック]
はじめてのアナリティクス API: サービス アカウント向け Python クイックスタート
カモノハシペリー
ペリー|フィニアスとファーブ|ディズニーキッズ公式