はじめに
先日、某勉強会でLTをしました。その際に10秒だけ紹介したRのパッケージについて記事を書いてみようと思います。
LDATSパッケージについて
時系列でのトピックモデルを推定することができるパッケージです。
やっていることとしてはLDAでトピックを推定して次元を減らし、そのトピックの多変量時系列に関してベイズ手法による変化点検知のためのパラメータ推定を行っているようです。GitHubの該当しそうなソースコードに多変量のデータに対するsoftmax関数での回帰をやっているとの記述がある。(multinomial Bayesian Time Series analysis)
元となっている論文を見る限り、BoW(Bag of Words)を想定して作っておらず、20~30程度のグループからなるデータに対して適用するのがちょうど良いです。アクセスログのページカテゴリや、マーケティングの顧客セグメントであればそんなに数は多くないので扱いやすいと思います。
データ
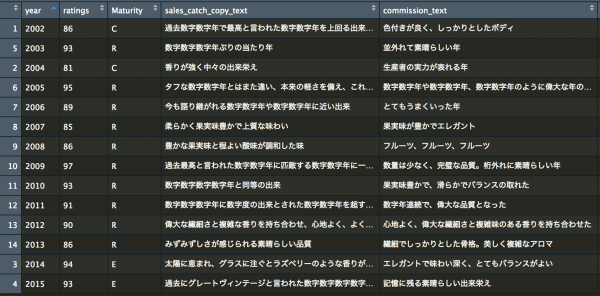
Webサイトから集めてきたボージョレ・ヌーボーのキャッチコピー14年分を今回は扱います。実は販売店側のキャッチコピーとワイン委員会が決めた評価が存在します。私の知っている世界は販売店側のキャッチコピーだけでした。
試してみた
今回はとにかく動くことだけを考えて、汚いコードとなっております。やっていることとしては、キャッチコピーを販売側とワイン委員会側のものを一つにつないで、数字を正規表現で「数字」に変換し、RMeCabで形態素解析をし、LDATS向けの形式のデータを作成していきます。
途中で、日本語の文字化け問題を回避するためにGoogle翻訳を使って単語名を置き換えています。
1時系列につき1文書となるようにデータを作っていく必要があるのですが、今回はボージョレ・ヌーボーのキャッチコピーなので最初から1時系列につき1文書となっているため都合が良いです。
データとソースコードはこちら。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 |
library(tidyverse) library(RMeCab) library(LDATS) wine_rating <- read_csv(file = "TimeseriesLDA/dataset.csv") wine_rating <- wine_rating %>% filter(!is.na(sales_catch_copy_text), !is.na(ratings), year > 1999, !is.na(commission_text)) wine_rating$sales_catch_copy_text <- gsub(pattern = "[0-9]", replacement = "数字", x = wine_rating$sales_catch_copy_text) wine_rating$commission_text <- gsub(pattern = "[0-9]", replacement = "数字", x = wine_rating$commission_text) wine_rating$bind_text <- paste0(wine_rating$sales_catch_copy_text , wine_rating$commission_text) # Bag of wordsの生成 res <- docMatrixDF(wine_rating$bind_text,minFreq=3) res <- data.frame(res) # View(rownames(res)) # Google Spread Sheetの=GOOGLETRANSLATE(C18,"ja","en")で変換した英語のデータを読み込む translate_df <- read_csv(file = "TimeseriesLDA/translate.csv",col_names = FALSE) colnames(translate_df) <- c("word_ja", "word_en") word_translate <- data.frame(word_ja=rownames(res)) word_translate <- word_translate %>% left_join(translate_df, by="word_ja") rownames(res) <- word_translate$word_en word_vector <- row.names(res) colnames(res) <- wine_rating$year # LDATSで扱えるデータ構造を作成 for (i in 1:nrow(res)) { nam <- paste( word_vector[i], sep = "") assign(nam, as.integer(res[i, ])) } # ここでの変数名が可視化の際に表示される document_term_table <- data.frame(list(sa=sa, fruits=fruits, Greatness=Greatness, Can=Can, workmanship=workmanship, taste=taste, quality=quality, Year=Year, Thenumbers=Thenumbers, Highest=Highest, fruit=fruit, Great=Great, delicate=delicate, complexity=complexity, rich=rich, past=past, fragrance=fragrance )) # 共変量データセット document_covariate_table <- data.frame(list(year=as.integer(colnames(res))), list(rating=as.integer(wine_rating$ratings))) test_set <- list(document_term_table=document_term_table, document_covariate_table=document_covariate_table) # 時系列トピックモデルの実行 r_LDATS <- LDA_TS(test_set, topics = 3:6, nseeds = 2, formulas = ~1, nchangepoints = 1:2, timename = "year") # 対数尤度などの出力 print(r_LDATS) # 時系列トピックモデルの可視化(先行研究に準拠) plot(r_LDATS) |
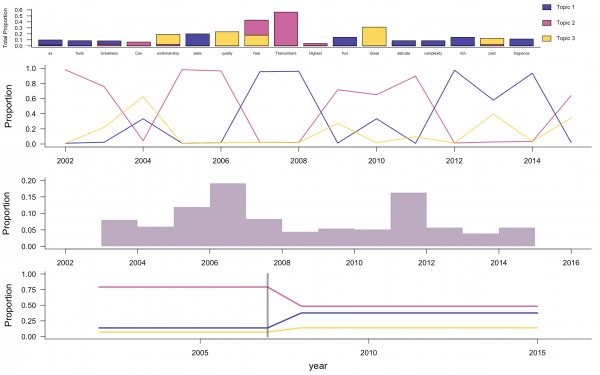
こちらは論文の図と同じものだとドキュメントの説明にあったので、論文の説明を見る限り、表すものとしては以下のようです。
- 一番上の積み上げグラフはトピックごとの単語の割合を表しています。
- 二番目の折れ線グラフはLDAによって推定されたトピックの時系列推移です。
- 三番目のヒストグラムは二番目の時系列における変化点を集計したものです。
- 四番目の折れ線グラフはモデルが推定したトピック割合の変化点の前後での推移です。
今回の図では文字が潰れていて見にくいですが、
- トピック1はボキャブラリーが比較的リッチなコメント(「フルーティー」「フレグランス」「複雑」)
- トピック2は数字を用いたコメント(「何年に一度の!」みたいな)
- トピック3はボキャブラリーが貧相なコメント(「すごい!」みたいな)
のようです。
二番目の折れ線グラフを見る限り、周期的に数字を用いたコメントが現れているように思われます。四番目の折れ線グラフの変化点を見る限り、近年は数字を用いたコメントが相対的に減ってきて、リッチなボキャブラリーになってきているようです。
おわりに
時系列トピックモデルをカジュアルに試せる面白そうなパッケージだなと思い、LDATSパッケージを触ってみましたが、そもそもBoWなどを想定して作られているパッケージではないので、単語数が多いような分析ではそもそも可視化ができず使いにくいだろうなと思いました。マーケティングなどでユーザーのセグメントの推移を分析したい場合などにちょうど良いのだろうと思われます。
参考情報
[1] Long‐term community change through multiple rapid transitions in a desert rodent community
[2] Latent Dirichlet Allocation coupled with Bayesian Time Series analyses
[3] Package ‘LDATS’