はじめに
昨年のR Advent Calendarはポケモンのデータをrvestでスクレイピングして、レアポケモンがどのような種族値における特徴があるのかを探ったり、経験値が必要な割に種族値が低い「コスパの悪いポケモン」などを見つけました。
今年のR Advent Calendarでは、年末年始といえば一発屋芸人のテレビなどでの露出が多くなることから、一発屋芸人の検索トレンドのデータを手に入れて分析してみたいと思います。
分析工程
・データの収集
・データの整形
・可視化
・分析
データの収集
こちらのサイト(流行した一発屋芸人一覧/年代流行)に一発屋の芸人さんが列挙されていました。私は普段テレビを見ないので大体の芸人さんがわからないです。
Googleトレンドから、芸人名に関するGoogle検索の時系列データを収集します。
非常に残酷なデータだなと思いました。
ただ、一つ弁護すると、Googleトレンドはレベルではなくピークを1として標準化した数値をデータとして提供してくれていますので、
ピークが著しく高ければ、今の水準が低くてもそこそこ検索されている可能性はあるとだけ言っておきます。
本当の検索回数が必要な場合は、Google Adwords(検索連動型広告)のアカウントの開設とともに検索ボリューム取得APIなどの申請が必要なので、正確なデータが必要な場合は会社として取り組んだほうが良いと思います。個人では厳しいです。
データの整形
各芸人さん(総勢21名)の検索トレンドデータのピークの6ヶ月前までのデータと6ヶ月後のデータまでの合計1年間の検索トレンドを各々抽出してみようと思います。
GoogleトレンドのデータはCSVでダウンロードできますので、そのCSVを読み込み、トレンドのデータを文字列から数値にし、ピークの前後12ヶ月ずつのデータを抽出します。
そうすることで、一発屋芸人のピークの前後に関するデータを作ります。(ただし、今朝、Google Trendのデータを取得できるgtrendsRというパッケージがR bloggerで紹介されていました。APIないはずなんですが、URLの工夫か裏でSelenium動かしていたりするんですかね。)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
library(tidyverse) library(directlabels) library(TSclust) library(gghighlight) # データの準備 ------------------------------------------------------------------ trend_dataset <- data.frame() for (i in 1:21) { #データの読込 trend_data <- read_csv(file = paste0("multiTimeline_",i,".csv"),skip = 2) trend_data <- trend_data %>% mutate( gsub(": (日本)","",colnames(trend_data)[2]) ) colnames(trend_data) <- c("month", "trend", "keyword") #1未満のデータをゼロにする trend_data <- trend_data %>% mutate(trend = as.numeric(replace(trend, trend=="1 未満", 0))) #ピークの月の前後12ヶ月を抽出 trend_data <- trend_data[(which.max(trend_data$trend)-12):(which.max(trend_data$trend)+12),] trend_dataset <- trend_dataset %>% rbind(trend_data) } #キーワードごとにインデックスをふる trend_dataset <- trend_dataset %>% group_by(keyword) %>% mutate(period = 1:n()) |
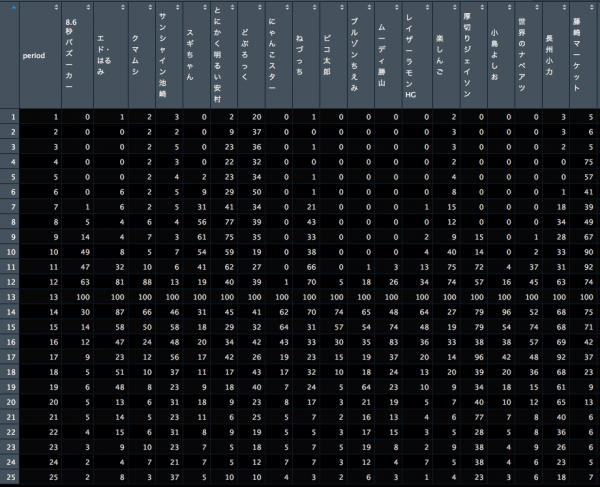
可視化
作成したデータを実際にプロットしてみます。
|
1 2 3 4 |
old = theme_set(theme_gray(base_family="HiraKakuProN-W3")) ggplot(data = trend_dataset, aes(x = period, y = trend, color=keyword)) + geom_line() |
一発屋にも盛り上がり方に違いがあるようですね。
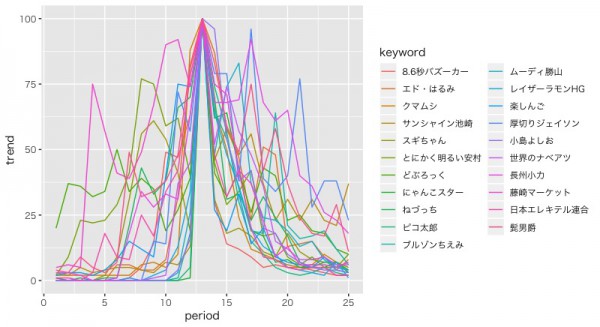
時系列クラスタリングの適用
多様な盛り上がり方があることから、TSclustというライブラリを使って時系列クラスタリングを行い、トレンドに関しての分類的なものを得たいと思います。
今回初めて使うのですが、参考文献によると様々な類似性指標を指定して、時系列ごとの類似性を計算するようです。ピアソン相関係数のようなシンプルなものもあれば、ユークリッド距離のものやFrechet距離とかいう聞いたことないものまで幅広く用意されています。今回はシンプルにピアソン相関係数にしてみます。そして、類似性指標を出してから、そのまま階層クラスタリングを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
trend_dataset_spread <- trend_dataset %>% select(-month) %>% tidyr::spread(key = keyword, value = trend) # COR距離で距離行列を作成 d <- diss(trend_dataset_spread %>% select(-period), "COR") #デフォルトの設定で階層クラスタリング h <- hclust(d) #階層クラスタリングの結果の可視化 par(cex=0.6) par(family = "HiraKakuProN-W3") plot(h, hang = -1) |
こちらが、TSclustのdiss関数を用いて計算した時系列データごとの距離を、階層クラスタリングにより描いたデンドログラムです。
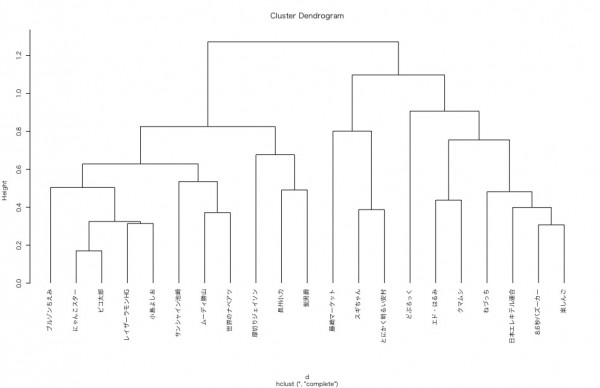
この分類だけ見ても、芸人さんを知らない私からすると何も共感がありませんので、先程のクラスタリング結果をもとに可視化をしてみます。
そこで、Tokyo.Rで知らない人はいないであろう、yutaniさんの作られたgghighlightを使ってみようと思います。
ただ、日本語のラベルの表示がうまくいかなかったので、芸人さんの名前をGoogleSpreadSheetのGoogle翻訳関数(GOOGLETRANSLATE)で英訳しておきます。
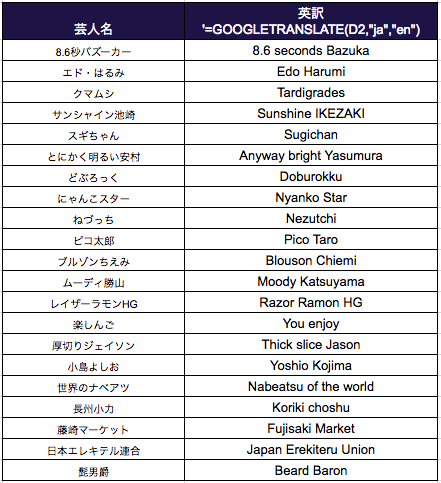
(Anyway bright YasumuraやThick slice Jasonは結構キャッチーなのでは?)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# クラスタ数は3とする data.frame(cutree(h, 3)) clusters <- data.frame(cluster_number=cutree(h, 3)) clusters$keyword <- rownames(clusters) rownames(clusters ) <- NULL trend_dataset_withcluster <- trend_dataset %>% left_join(clusters, by = "keyword") #英訳したデータの読み込みと結合 rename_keywordlist <- read_csv("rename_keywordlist.csv") trend_dataset_withcluster <- trend_dataset_withcluster %>% left_join(rename_keywordlist, by = "keyword") gghighlight_line(trend_dataset_withcluster, aes(period, trend, colour = keyword_en), predicate = max(cluster_number) == 1) gghighlight_line(trend_dataset_withcluster, aes(period, trend, colour = keyword_en), predicate = max(cluster_number) == 2) gghighlight_line(trend_dataset_withcluster, aes(period, trend, colour = keyword_en), predicate = max(cluster_number) == 3) |
まずはクラスター1
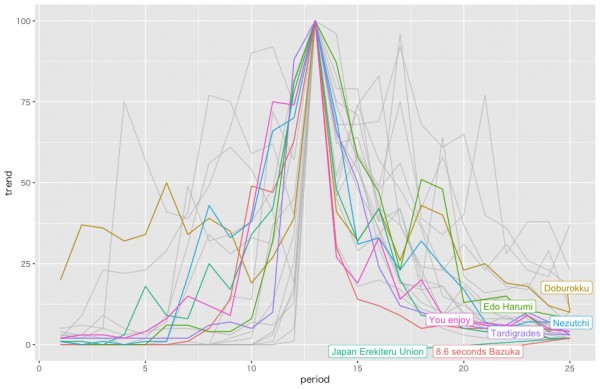
比較的短期でピークに達し、すぐに検索されなくなる、一発屋の名に相違ない傾向を持ったクラスターのように思われます。「日本エレキテル連合」とか「楽しんご」とか「8.6秒バズーカ」とかです。
続いてクラスター2
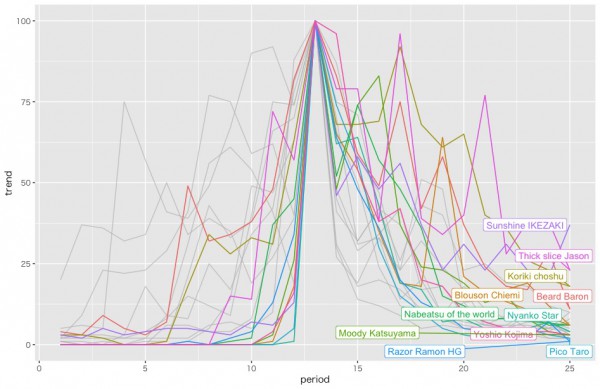
急激にピークに達するものの、ややしぶとく残り続けるような一発屋のクラスターなのかなと思います。「レイザーラモンHG」とか「厚切りジェイソン」とか「ピコ太郎」とか「世界のナベアツ」です。
そしてクラスター3
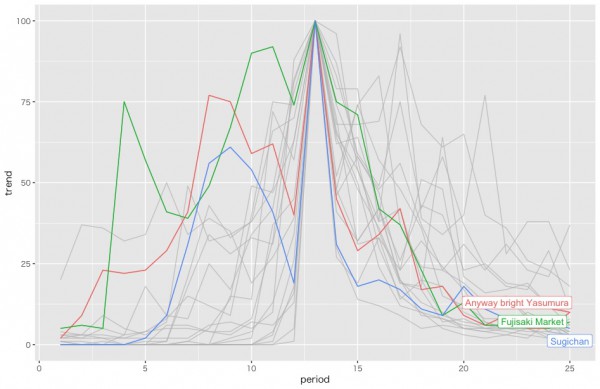
3人の芸人さんしか属していないですね。クラスターの数は2個でもよかったかもしれない。段階的にピークに達し、一気に落とされるという一発屋のクラスターのようです。「とにかく明るい安村」とか「藤崎マーケット」とか「すぎちゃん」とかです。
様々な傾向の一発屋さんがいるのがわかりました。
トレンドの推定
今回扱っているデータは芸人さんの数×時点のデータの多変量時系列となります。都合の良いものはないかと考えていましたが、古典的なVARではサンプルサイズ的にかなり苦しいと思い、Stanによるダイナミックパネルデータ分析などの事例はないか漁っていましたが、なかなかありませんでした。
松浦さんの『StanとRでベイズ統計モデリング (Wonderful R)』の241pに書かれている、モデル式12-8や12-9が今回のものに適しているなと思いましたが、コードを上げている方は見当たらなかったです。よしそれならば作ろうかと思った矢先、logics-of-blueさんのStan Advent Calendarの投稿、「Stanで推定する多変量時系列モデル」がかなりどんぴしゃな内容でしたので、コードを拝借してこの一発屋データの推定をしてみようと思います。
まずは、stanのコード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
data { int T; // データ取得期間の長さ int performer_num; // 芸人さんの数 matrix[T, performer_num] y; // 観測値 } parameters { vector[T] x; // 状態の推定値 vector[performer_num] r; // 芸人さん毎のランダム効果 real<lower=0> s_w; // 過程誤差の標準偏差 real<lower=0> s_v; // 観測誤差の標準偏差 real<lower=0> s_r; // ランダム効果の標準偏差 //vector[performer_num] sigma; //芸人さん毎の標準偏差 } model { // 状態方程式に従い、状態が遷移する for(i in 2:T) { x[i] ~ normal(x[i-1], s_w); } // ランダム効果 r ~ normal(0, s_r); // 観測方程式に従い、観測値が得られる for(i in 1:T) { for(j in 1:performer_num) { y[i, j] ~ normal(x[i] + r[j], s_v); } } } |
そしてキックして結果を可視化するためのRコード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
library(rstan) library(bayesplot) T <- trend_dataset_spread %>% select(-period) %>% nrow() performer_num <- trend_dataset_spread %>% select(-period) %>% ncol() data <- list(T = T, performer_num = performer_num , y = trend_dataset_spread %>% select(-period)) fit <- stan(file = 'multivariate_time_series.stan', data = data, seed = 1, iter = 30000, warmup = 10000, thin = 10 ) mcmc_rhat(rhat(fit)) # データの整形 stan_df_1 <- fit %>% rstan::extract() %$% x %>% apply(2, quantile, probs = c(0.025, 0.5, 0.975)) %>% t() %>% cbind(1:nrow(trend_dataset_spread)) %>% data.frame # 列名の変更 colnames(stan_df_1) <- c("lwr", "fit", "upr", "time") # 結果 head(stan_df_1, n = 3) ggplot(data = trend_dataset_withcluster) + ggtitle("推定結果(ピコ太郎)") + geom_line(aes(x = period, y = trend, color = keyword_en)) + gghighlight(keyword_en == "Pico Taro", use_group_by = FALSE) + geom_line(data = stan_df_1, aes(x = time, y = fit), size = 1.2) + geom_ribbon(data = stan_df_1, aes(x = time, ymin = lwr, ymax = upr), alpha = 0.3) |
そのまんま実行して、一発屋の時系列の中央値を可視化したらこんな感じになりました。一発屋のトレンドをうまく抽出できているのかなと思います。
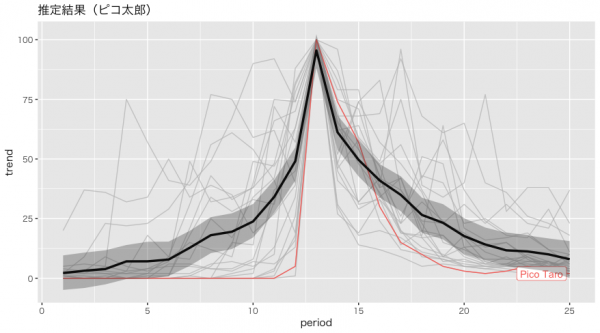
今後の改良としては、階層性を持たせ、芸人さんごとのハイパーパラメータを持たせるとかなのですが、正月にでも取り組みたいと思います。(芸人さん以外のデータでやりたい。)
一方で、他にも多変量時系列で何かないか漁っていたのですが、Applied Time Series Analysis for Fisheries and Environmental Sciences : Dynamic factor analysisで紹介されている、Dynamic Factor Analysisというものが面白そうだなと思いました。
bayesdfaというパッケージを用いて、多変量時系列データに存在するであろうトレンドをStanを用いて推定することができるようです。元となった論文には各エリアごとのノルウェーロブスターの個体数のトレンドを推定し、3つのトレンドが発見されたとしています。ただ、同時点間のデータではないという点から今回のデータへの適用は不適切です。
同時点間に観測されていないデータであるという問題を認識した上で、このパッケージを使ってどんなトレンドを抽出できるのか試してみようと思います。
|
1 2 3 4 5 6 |
mod_3 = bayesdfa::fit_dfa(y = trend_dataset_spread %>% select(-period) %>% t(), num_trends = 3) rot = bayesdfa::rotate_trends(mod_3) names(rot) matplot(t(rot$trends_mean), type = "l", lwd = 2, ylab = "mean trend") |
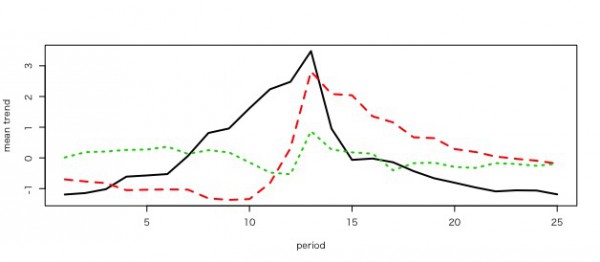
徐々に増えてから一気に落ちるトレンドや、一気に増えてから徐々に落ちるトレンドなどがうまく捉えれている気がします。
さらなる試行として、AICのような情報量基準である、Leave One Out Information Criterion (LOOIC)が最も低くなるトレンドの数を探索してみます。
|
1 2 3 4 5 |
mod_1 = fit_dfa(y = trend_dataset_spread %>% select(-period) %>% t(), num_trends = 1) mod_2 = fit_dfa(y = trend_dataset_spread %>% select(-period) %>% t(), num_trends = 2) mod_3 = fit_dfa(y = trend_dataset_spread %>% select(-period) %>% t(), num_trends = 3) mod_4 = fit_dfa(y = trend_dataset_spread %>% select(-period) %>% t(), num_trends = 4) mod_5 = fit_dfa(y = trend_dataset_spread %>% select(-period) %>% t(), num_trends = 5) |
トレンド数を1から5まで指定して実行した結果、5の時が一番LOOICが低くなりました。
|
1 2 3 |
rot = bayesdfa::rotate_trends(mod_5) names(rot) matplot(t(rot$trends_mean), type = "l", lwd = 2, ylab = "mean trend") |
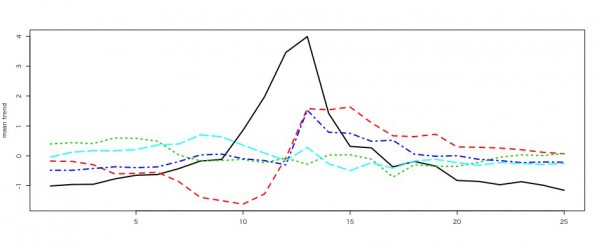
まぁ、適切な使い方ではないのですが、徐々に増えてから一気に落ちるトレンドや、一気に増えてから徐々に落ちるトレンドなどが引き続き捉えれているようです。
今後の課題
・Stanによる多変量時系列のモデリングをしてみる。(Dynamic Panel分析とかもできると良い。少なくともStanのドキュメントにはない。)
・Dynamic Factor Analysisの適切な事例での適用をしてみる。
それでは、どうか良い年末をお過ごし下さい!
メリークリスマス!
参考情報
Introduction to gghighlight: Highlight ggplot’s Lines and Points with Predicates
{TSclust} ではじめる時系列クラスタリング
Applied Time Series Analysis for Fisheries and Environmental Sciences 9.7 Dynamic factor analysis
読了:Montero & Vilar (2014) RのTSclustパッケージで時系列クラスタリング