はじめに
先日、近所の幹線道路の信号付き横断歩道を横断しようとした際に、2メートルほど先で回避不能な速度で車が赤信号を無視して横断歩道を突っ切きるという非常に恐ろしいイベントに遭遇しました。
そこで、私は「このイベント、何回かあったら死亡事故が起きるぞ」と思いました。警察署に近隣道路の不満について電話をしてみたのですが、「警察もちゃんと考えて取り締まっていたり対策してますので」と言われ、何の成果も獲れない電話となりました。
そのようなモヤモヤの中、私は民間でできることは「客観的なデータでもって、エリア、曜日、天候、時間帯ごとの、死亡事故のリスクを見積もり、それを公開して注意喚起していくこと」なのではないかと思うに至りました。
よって、警察庁が公開している交通事故のオープンデータについて、その前処理と機械学習によるエリアの死亡事故の発生予測などについて記していきます。
前処理のためのデータやコードはこちらのGitHubにあります。
https://github.com/KamonohashiPerry/traffic_accident_analysis
スターを10個以上いただけて、データ作って良かったなと思いました。
目次
・データについて
・先行研究について
・前処理について
・EDAからわかること
・機械学習
・さいごに
データについて
2019年と2020年の交通事故に関するデータが警察庁よりオープンデータとして公開されています。
オープンデータ 2020年(令和2年)
オープンデータ 2019年(平成31年/令和元年)
どのようなデータかというと、
それぞれ2019年と2020年の間に発生した全国の事故について、発生した状況(時、場所、天候)やその結果に関するデータからなり、項目の数としては58個とオープンデータとしてはかなり豊富な情報量となっています。
データは本票、補充票、高速票の3つからなるのですが、今回は本票だけを用います。
高速道路の精緻な分析をしようと思うと、高速票を繋ぐ必要がありますが、私の目的は一般道にあるので、繋がないものとします。
先行研究について
事故の予測に関する先行研究
交通事故の分析に関する研究は以下のものがあり、参考にしました。
死亡事故を予測するという問題設定として、その特徴量としては場所、時間帯、曜日、場所かつ時間、場所かつ曜日かつ時間、天候、季節、風速・風向き、車線の数、歩道の有無、制限速度などを用いていることがわかりました。
そして、データをクラスタリングするためにDBSCANを用いたり、不均衡データであることから、アンダーサンプリングを行ったりしているようです。
最後に、アルゴリズムはSVMやロジスティック回帰、深層学習と色々と使われているようです。
・Live Prediction of Traffic Accident Risks Using Machine Learning and Google Maps
・A Deep Learning Approach for Detecting Traffic
Accidents from Social Media Data
・A BASIC STUDY ON TRAFFIC ACCIDENT DATA ANALYSIS USING
SUPPORT VECTOR MACHINE
その他
・Taxi Demand Prediction System
・2019年04月号トピックス 警察庁のオープンデータを活用した独自AIによる犯罪発生予測
前処理について
ソースコードに関しては、GitHubに上げておりますので、
.pyなら
https://github.com/KamonohashiPerry/traffic_accident_analysis/blob/main/src/preprocess.py
https://github.com/KamonohashiPerry/traffic_accident_analysis/blob/main/src/preprocess_second.py
.ipynbなら
https://github.com/KamonohashiPerry/traffic_accident_analysis/blob/main/Traffic_Accident_Analysis.ipynb
を参照ください。
基本方針
・天候、時間帯、曜日、平日、道路の形状、スピード制限など、事故の結果(死亡の有無)を明らかに予測できそうなもの以外を特徴量にします。
・メッシュ単位での過去の事故に関する情報に関する特徴量の作成(学習を行う時点よりも過去の時点のデータのみ利用)
詳細
・事故の発生日時のdatetime化(列で年・月・日・時・分が分かれているため)
・マスタ情報(PDF)をもとにマスタのIDを名前に変換
・緯度経度のデータについて、度分秒から度への変換を行い、3次メッシュ(1km四方)のデータを作成
・メッシュ単位での特徴量として、過去の事故発生件数、死亡数などを集計
・メッシュ単位での特徴量として、過去に発生した事故に関するもろもろのデータの集計(そのメッシュで事故を起こした平均年齢や事故が発生してきた時間帯など)
・もろもろの変数のダミー変数化
EDAからわかること
EDAに関しては.ipynbのみで行っております。
https://github.com/KamonohashiPerry/traffic_accident_analysis/blob/main/Traffic_Accident_Analysis.ipynb
私がよく分析で使うのは、データの該当件数とカテゴリごとの率の可視化なのですが、以下の図の見方としては、青の棒グラフが各カテゴリの件数、赤の折れ線グラフが死亡率となっています。
都道府県
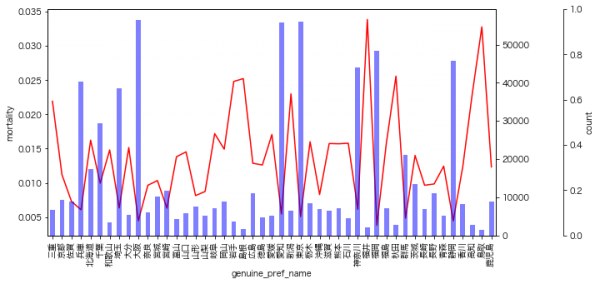
福井県、鳥取県、秋田県、島根県、岩手県などは死亡率が高そうです。
道路種別
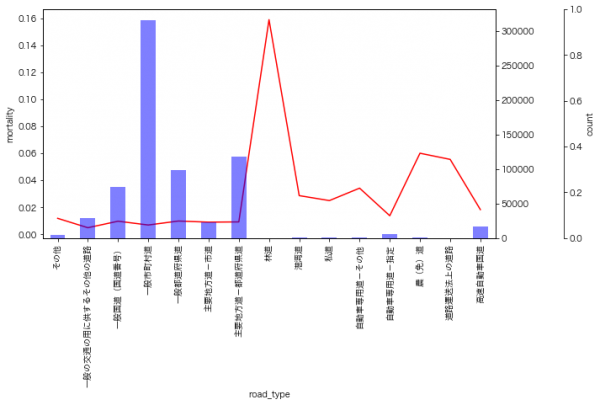
農道(815件)や林道(88件)で起きる事故非常に死亡率が高くなるようです。
時間帯
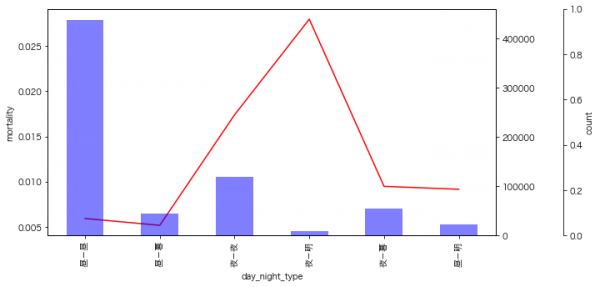
夜間や明け方は死亡率が高くなるようです。
天候
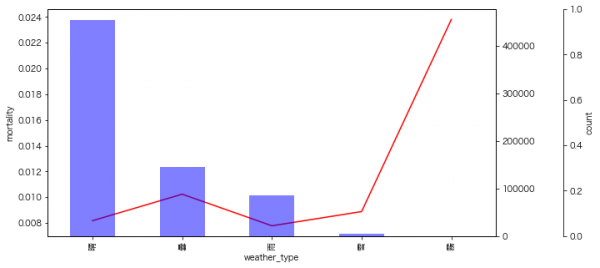
霧の天候(294件)では死亡率が高くなるようです。
人口密集地かどうか
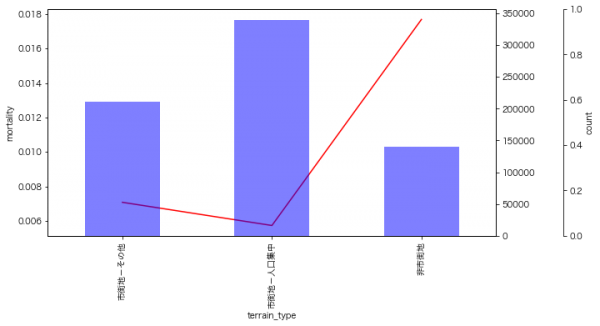
市街地ではないところでは死亡率が高くなるようです。
道路の形状
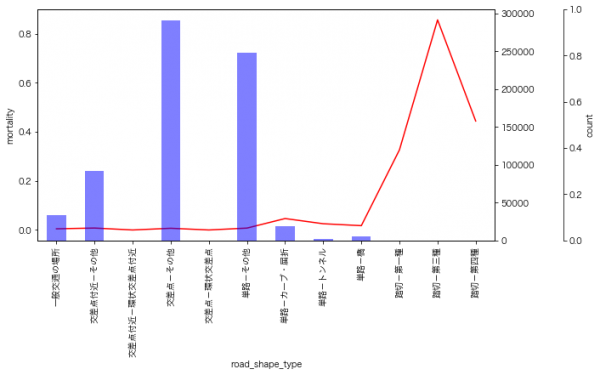
踏切-第一種(254件)はかなり死亡率が高くなるようです。カーブも死亡率が高くなります。そういえば実家の近くにも魔のカーブと呼ばれるところはありますし、事故も起きていました。
信号機のタイプ
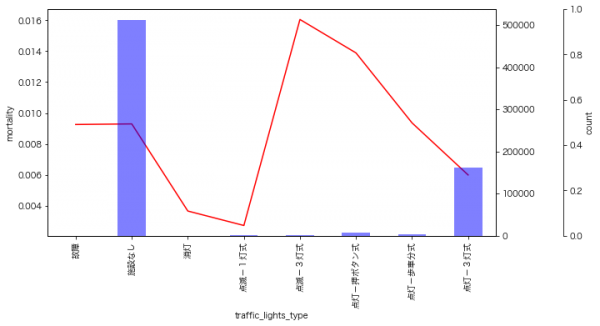
点滅-3灯式(2566件)や点灯-押ボタン式(7703件)は死亡率が高いようです。
道路の幅
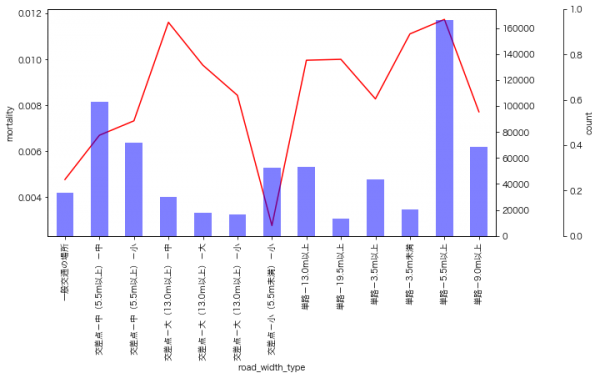
大きな交差点では死亡率が高い傾向にあります。単路に関しては一様な傾向ではないですが、小さい方が死亡率が高そうです。
道路の区切り
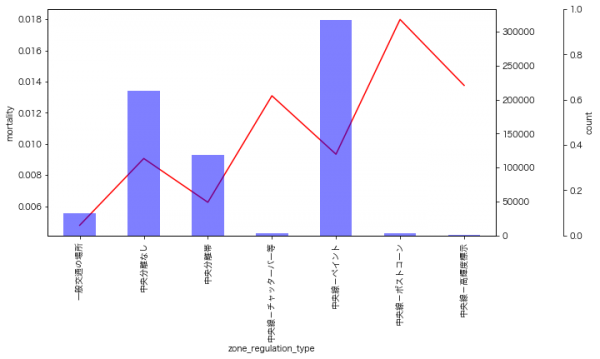
道路の区切りがペイントだけのケースは、中央分離帯がある場合よりも死亡率が高い傾向にあります。あと、中央線がポストコーン(チンアナゴみたいなやつ)だと死亡率が上がるようです。
歩道との区別
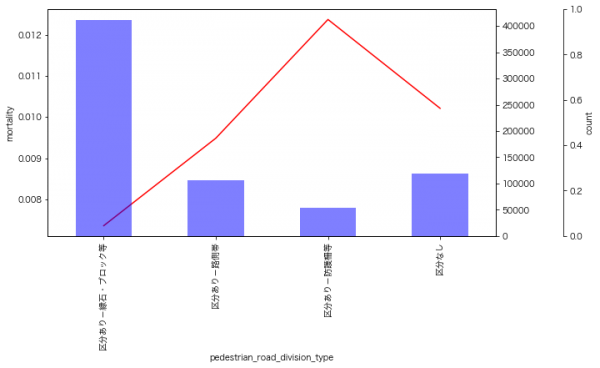
道路について歩道との区分がない場合に死亡率が高くなるようです。
速度制限
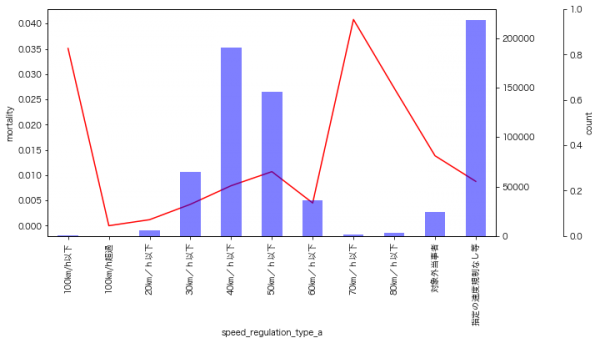
速度域が高くなるにつれ、死亡率が高くなるようです。あと、速度規制がされていないところも高くなっています。
曜日
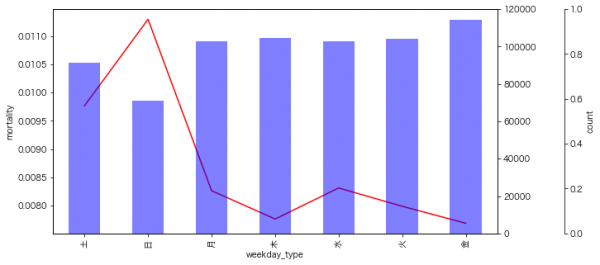
土日の死亡率が高い。
祝日・その前日
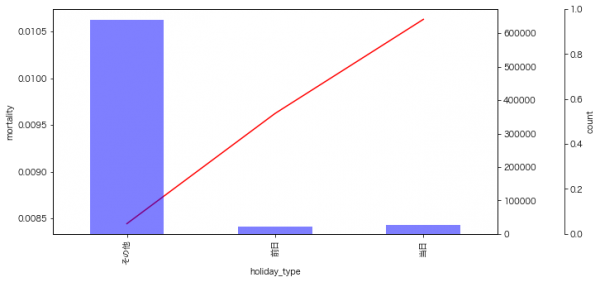
祝日とその前日の死亡率は高い傾向にある。
以上のことから、得られた考察としては、
・土日や祝前日の道路はいつもより危ない
・夜間や明け方の道路は危ない
・制限速度の高い道路は危ない
・大きな交差点は危ない
・点滅信号は危ない
・カーブは危ない
・霧は危ない
でした。普段、出歩く際に意識しておくといいと思います。
機械学習
教師データを事故発生からの死亡有無(1or0)、特徴量を先行研究を参考にオープンデータから作れるものとして、
基本的には、LightGBMでの学習、ハイパーパラメータ探索、モデルの訓練(メッシュ番号でグループ化したクロスバリデーション)、テストデータ(学習は2020年11月まで、テストは2020年12月以降としている)での予測、日本地図への可視化を行っています。
ソースコードはGitHubに上げてあるので、ここでは記しません。
.pyなら(学習のみ)
https://github.com/KamonohashiPerry/traffic_accident_analysis/blob/main/src/train_model.py
.ipynbなら(学習だけでなく、予測と日本地図への可視化もしている)
https://github.com/KamonohashiPerry/traffic_accident_analysis/blob/main/Traffic_Accident_Analysis.ipynb
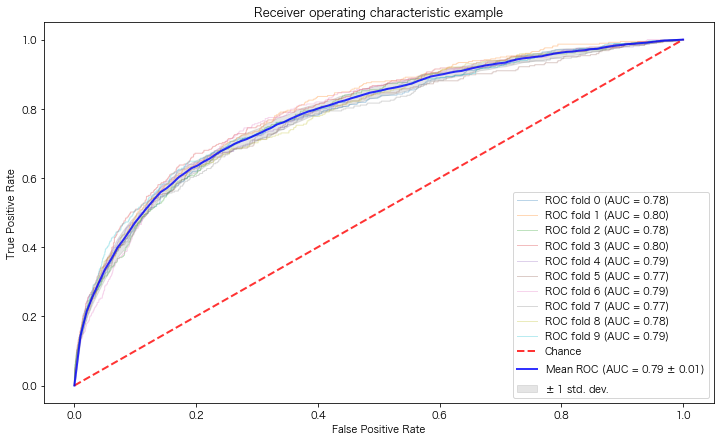
10-foldのCVをメッシュ番号でグループ化して学習させた際のAUCです。高い部類に入りますが、今回は不均衡データなので、抜群に当たっている感じではないです。
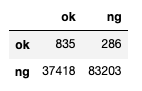
事故の死亡率は、0.9%なので、この予測の場合、2.2%が死亡すると当てれているということになります。また、予測から、全体の72%の死亡事故を当てているという結果です。
この性能に関しては今後、もっと高めていく余地はいくらでもあると思います。
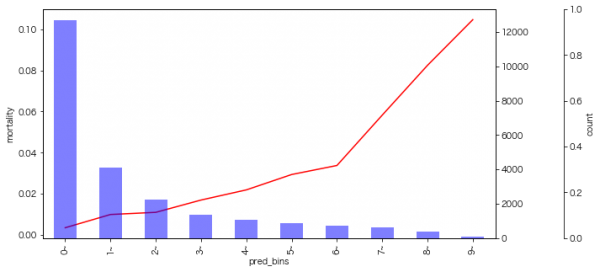
こちらは、テストデータでの予測スコアの階級値(青い棒グラフ)と実際の死亡率(赤い線グラフ)を示したものです。スコアが高いものは信じてもいいかなぁと思いました。
特徴量重要度の上位10件は以下の通りです。
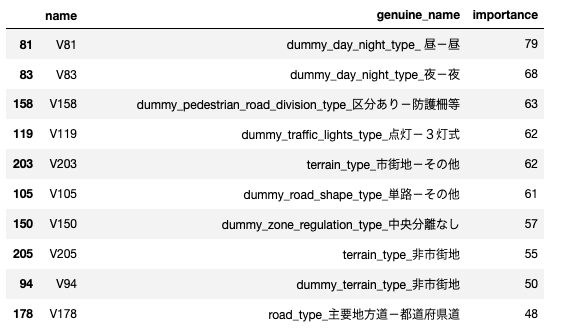
時間帯とか、防護策とか、信号機のタイプとか、市街地かどうかなどが予測に役立っているようです。
死亡事故発生を予測した確率を日本地図の関東エリアにプロットしたものが以下の図になります。
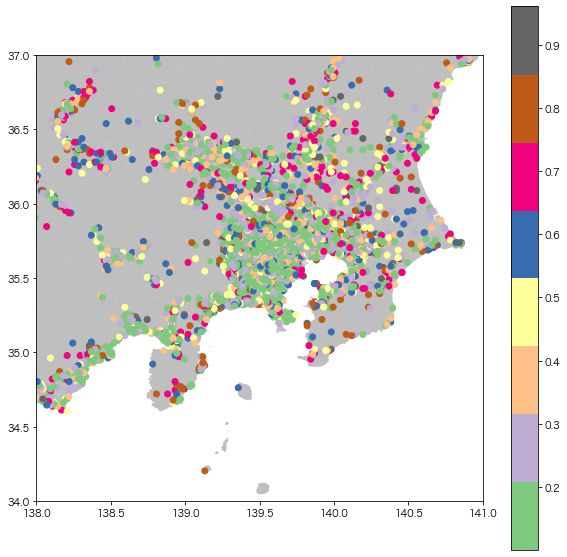
市街地のほうが死亡事故が起きやすいように見えますね。
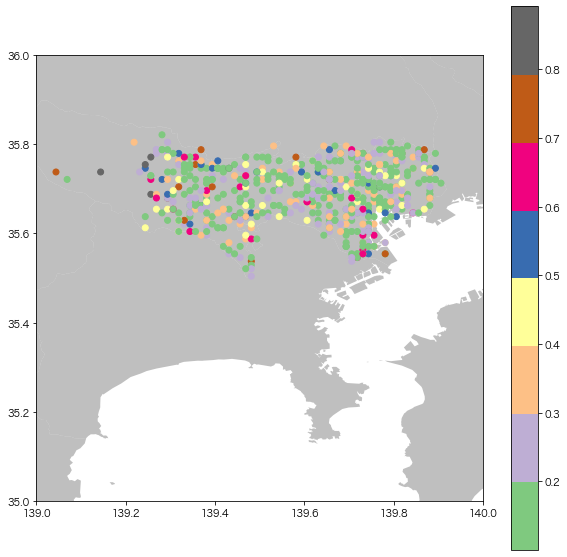
東京都だけに絞ってみましたが、危険なエリアは都心に点在はしていますが、郊外のほうが死亡率が高そうです。
さいごに
交通事故にあいかけて、その怒りの感情を警察庁のデータにぶつけてみましたが、死亡事故が起きやすい条件などがある程度見えてきたと思いました。もちろん、なんとなく思っていた傾向もあったのですが、数字でハッキリと出せるのは良いですね。今後、旅行などをする際に、確率の高いエリアを警戒して行動するようにしたいです。
そして、地図への可視化は普段の仕事でほとんど行わないのですが、こうしてデータに触れて可視化の練習ができたのも有意義に思いました。
この警察庁のデータは分析するまでに工数がかかるデータとも言えるので、この記事をとっかかりとして、オープンデータの分析に挑戦して安全な生活を送る上での知見をシェアしていけると良いな、というか民間としてはこれくらいしかできないなと思っています。
参考情報
・[第3版]Python機械学習プログラミング 達人データサイエンティストによる理論と実践 (impress top gear)
・Pythonでプロットした地図を出力する
・Pythonで度と度分秒を相互に変換する