はじめに
仕事で深層学習を使うことはないのですが、扱える技術の幅を広げていきたいなと思い、BLSTMを用いた文書分類についてkerasでの簡単なサンプルコードをやってみようと思います。データは以前集めた、某不動産紹介サイトの賃貸マンションの設備に関する文書とそれがデザイナーズマンションかどうかのラベルを使います。そして文書内の単語からその文書がデザイナーズマンションかどうかを予測します。前回はAUCで83%だったので、それを超えれると良いですね。目次
単純なRNNとは
- モチベーション
- フィードフォワード型のニューラルネットワークではうまく扱うことができない時系列データをうまく扱えるようにすること。
- 特徴
- 入力が互いに関係している(多層パーセプトロンの際は置かれていない仮定)
- 直訳すると循環するニューラルネットワークとなる。
- 最初の文の単語が2つ目、3つ目の単語に影響を与える可能性を考慮。
- 入力が互いに関係している(多層パーセプトロンの際は置かれていない仮定)
- 具体的な関数の形としては、 $$ h_t = \tanh (W h_{t-1} + U x_t) \\\ y_t = softmax(V h_t) $$ で与えられる。
- \( h_t \)は隠れ層の状態を、\( x_t \)は入力変数を、\( y_t \)は出力ベクトルを表している。(他のアルファベットは重み行列)
LSTMとは
- モチベーション
- 単純なRNNの勾配消失問題を解決するために提案された手法。
- 特徴
- 単純なRNNに置き換えることで性能が大幅に向上することも珍しくない。
- 時系列データ、長い文章、録音データからなる長期的なパターンを取り出すことを得意としている手法。
- 勾配消失問題に強い
- Long Short-Term Memory:長短期記憶
- 長期依存性を学習できるRNNの亜種。
- 入力ゲート、忘却ゲート、出力ゲート、内部隠れ層という4つの層が相互に関わり合う。重要な入力を認識し、それを長期状態に格納すること、必要な限りで記憶を保持すること、必要なときに記憶を取り出すことを学習する。
- 入力ゲート:内部隠れ層のどの部分を長期状態に加えるかを決める。
- 忘却ゲート:長期状態のどの部分を消去するか決める。
- 出力ゲート:各タイムステップで、長期状態のどの部分を読み出し、出力するかを決める。
- 単純なRNNに置き換えることで性能が大幅に向上することも珍しくない。
i = \sigma (W_i h_{t-1} + U_i x_t) \\
f = \sigma (W_f h_{t-1} + U_f x_t) \\
o = \sigma (W_o h_{t-1} + U_ox_t ) \\
g = \tanh (W_g h_{t-1} + U_g x_t) \\
c_t = (c_{t-1} \otimes f ) \otimes ( g \otimes i) \\
h_t = \tanh (c_t) \otimes o
$$ i:入力ゲート(input)
f:忘却ゲート(forget)
o:出力ゲート(output)
\( \sigma \):シグモイド関数
g:内部隠れ層状態
\(c_t \):時刻tにおけるセル状態
\(h_t \):時刻tにおける隠れ状態
Bidirectional LSTMとは
- モチベーション
- 従来のRNNの制約を緩和するために導入。
- 特徴
- ある特定の時点で過去と将来の利用可能な入力情報を用いて訓練するネットワーク
- 従来のRNNのニューロンをフォワード(未来)なものとバックワード(過去)なものとの2つに分ける。
- 2つのLSTMを訓練している。
- 全体のコンテキストを利用して推定することができるのが良いらしい。
- 文章で言うと、文章の前(過去)と後(未来)を考慮して分類などを行うイメージ。
- 人間もコンテキストを先読みしながら解釈することもある。
- 従来のRNNのニューロンをフォワード(未来)なものとバックワード(過去)なものとの2つに分ける。
- BLSTMは全てのシークエンスの予測問題において有効ではないが、適切に扱えるドメインで良い結果を残す。
- 1997年とかなり歴史があるものらしい
- ある特定の時点で過去と将来の利用可能な入力情報を用いて訓練するネットワーク
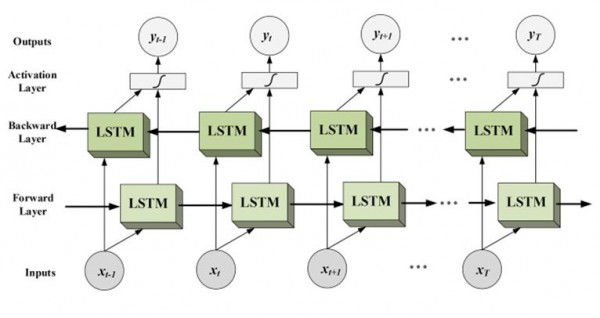 (出典:Deep Dive into Bidirectional LSTM)
(出典:Deep Dive into Bidirectional LSTM)
Bidirectional LSTMで文書分類
今回は、BLSTMを使って、マンションの設備に関するテキスト情報から、そのマンションがデザイナーズマンションかどうかを予測します。全体のソースコードはGoogle Colabを御覧ください。データ
|
1 2 3 4 5 6 7 8 9 |
import pandas as pd from sklearn.model_selection import train_test_split # GitHubにおいてあるマンションのデータを読み込む raw_data = pd.read_csv("https://github.com/KamonohashiPerry/kamonohashiperry.com/blob/master/designers_apartment/designers_apartment.csv?raw=true") raw_data["text"] = raw_data["text"].str.replace("デザイナーズ", "") # 訓練データとテストデータを分割 train_x, test_x, train_y, test_y = train_test_split(raw_data["text"], raw_data["designer_flag"], test_size=0.3, random_state=123) |
データを確認してみると、
|
1 2 3 4 5 6 7 8 9 10 11 |
train_x 246 バストイレ別 バルコニー エアコン クロゼット フローリング 浴室乾燥機 オートロック シス... 1402 バストイレ別 バルコニー エアコン ガスコンロ対応 クロゼット フローリング TVインターホ... 1586 バストイレ別 バルコニー エアコン ガスコンロ対応 クロゼット フローリング TVインターホ... 375 バストイレ別 バルコニー エアコン クロゼット フローリング 浴室乾燥機 オートロック 室内... 1272 エアコン フローリング 室内洗濯置 シューズボックス 角住戸 光ファイバー 2面採光 最上階... 1122 バストイレ別 バルコニー エアコン ガスコンロ対応 クロゼット フローリング TVインターホ... 1346 バストイレ別 バルコニー エアコン ガスコンロ対応 クロゼット フローリング オートロック... 1406 バストイレ別 バルコニー エアコン ガスコンロ対応 フローリング シャワー付洗面台 オートロ... 1389 バストイレ別 エアコン クロゼット フローリング シューズボックス 押入 光ファイバー 即入... 1534 バルコニー エアコン クロゼット TVインターホン オートロック 陽当り良好 シューズボック... |
|
1 2 3 4 5 6 7 8 9 10 11 |
train_y 246 1 1402 0 1586 0 375 1 1272 0 1122 0 1346 0 1406 0 1389 0 1534 0 |
前処理
Google Colab上で形態素解析を行うために、MeCabをインストールする。|
1 2 3 4 5 6 7 8 9 10 11 12 |
!apt-get -q -y install sudo file mecab libmecab-dev mecab-ipadic-utf8 git curl python-mecab # せっかくなので、Neologdを使えるようにする。 !git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git !echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n !cat /etc/mecabrc !sed -e "s!/var/lib/mecab/dic/debian!/usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd!g" /etc/mecabrc > /etc/mecabrc.new !cat /etc/mecabrc.new !cp /etc/mecabrc /etc/mecabrc.org !cp /etc/mecabrc.new /etc/mecabrc !cat /etc/mecabrc !apt-get -q -y install swig !pip install mecab-python3 |
これでMaCab NeologdをGoogle ColabのPythonで実行できます。
テキストデータの前処理を行うために名詞だけを抽出してリスト形式で返す関数を定義します。
|
1 2 3 4 5 6 7 8 9 |
# 形態素解析を行い、名詞だけ抽出し、かつ名詞の中でも活用を絞り込んで抽出する関数 def nouns_extract(line): import re import MeCab keyword=[] m = MeCab.Tagger(' -d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd ') for l in m.parse(line).splitlines(): if l != 'EOS' and l.split('\t')[1].split(',')[0] == '名詞': if l != 'EOS' and re.search('^一般$|^形容動詞語幹$|^サ変接続$|^副詞可能$|^固有名詞 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import collections # 語彙に関するデータを作成するための処理 maxlen = 0 word_freqs = collections.Counter() num_recs = 0 for sentence in list(train_x): words = nouns_extract(sentence) maxlen = max(maxlen, len(words)) # リストの最大値を取得 # 単語の出現頻度を集計 for word in words: word_freqs[word] += 1 num_recs += 1 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 語彙のなかから2000語を選ぶ MAX_FEATURES = 2000 # 文の長さの最大値 MAX_SENTENCE_LENGTH = 40 # 語彙数 vocab_size = min(MAX_FEATURES, len(word_freqs)) + 2 # 単語とそのインデックスからなるdict形式のデータ word2index = {x[0]: i+2 for i, x in enumerate(word_freqs.most_common(MAX_FEATURES))} # 0番目と1番目にパディング用(PAD)と擬似単語(UNK)を指定する # パディングとは系列の長さを揃えること。 word2index['PAD'] = 0 word2index['UNK'] = 1 # インデックスとその単語からなるdict形式のデータ index2word = {v:k for k, v in word2index.items()} |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import numpy as np # 空の変数を作成 X = np.empty((num_recs, ), dtype=list) y = np.zeros((num_recs, )) i = 0 train_x_list = list(train_x) train_y_list = list(train_y) for i in range(len(train_x_list)): label = train_y_list[i] words = nouns_extract(train_x_list[i]) # 特徴量用の空の変数 seqs = [] for word in words: # 単語を照合してインデックスを取得 if word in word2index: seqs.append(word2index[word]) else: # 語彙に存在しない単語の場合はUNKのインデックスを付与する seqs.append(word2index["UNK"]) X[i] = seqs y[i] = int(label) i += 1 # パディングして、同じ長さに揃えてくれる関数 X = sequence.pad_sequences(X, maxlen=MAX_SENTENCE_LENGTH) |
実行
先程作成したデータを訓練データとテストデータに分けます。|
1 |
Xtrain, Xtest, ytrain, ytest = train_test_split(X, y, test_size=0.2, random_state=42) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import tensorflow as tf from sklearn.metrics import roc_auc_score from keras.callbacks import Callback, EarlyStopping # define roc_callback, inspired by https://github.com/keras-team/keras/issues/6050#issuecomment-329996505 def auc_roc(y_true, y_pred): # any tensorflow metric value, update_op = tf.contrib.metrics.streaming_auc(y_pred, y_true) # find all variables created for this metric metric_vars = [i for i in tf.local_variables() if 'auc_roc' in i.name.split('/')[1]] # Add metric variables to GLOBAL_VARIABLES collection. # They will be initialized for new session. for v in metric_vars: tf.add_to_collection(tf.GraphKeys.GLOBAL_VARIABLES, v) # force to update metric values with tf.control_dependencies([update_op]): value = tf.identity(value) return value |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
from keras.layers import Activation, Dense, Dropout, Embedding, LSTM, Bidirectional from keras.models import Sequential from keras.preprocessing import sequence from keras.callbacks import TensorBoard LOG_DIR = "drive/Colab Notebooks/NLP/logs" # 分散表現層の次元 EMBEDDING_SIZE = 128 # 隠れ層の数 HIDDEN_LAYER_SIZE = 64 # バッチサイズ BATCH_SIZE = 32 # エポックの数 NUM_EPOCHS = 10 model = Sequential() # 分散表現の層 model.add(Embedding(vocab_size, EMBEDDING_SIZE, input_length=MAX_SENTENCE_LENGTH)) # Bidirectional LSTMの層 model.add(Bidirectional(LSTM(HIDDEN_LAYER_SIZE ))) # ドロップアウト層 model.add(Dropout(0.5)) # 活性化層 model.add(Dense(1, activation='sigmoid')) # モデルのコンパイル model.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy", auc_roc]) my_callbacks = [EarlyStopping(monitor='auc_roc', patience=300, verbose=1, mode='max'), TensorBoard(LOG_DIR)] # ネットワークの学習 history = model.fit(Xtrain, ytrain, batch_size=BATCH_SIZE, epochs=NUM_EPOCHS, callbacks=my_callbacks, validation_data=(Xtest, ytest)) |
|
1 2 3 4 5 |
# testデータでの予測 score, acc, auc = model.evaluate(Xtest, ytest, batch_size=BATCH_SIZE) print("Test score: {:.3f}, accuracy: {:.3f}, auc: {:.3f}".format(score, acc, auc)) Test score: 0.444, accuracy: 0.824, auc: 0.844 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
for i in range(20): idx = np.random.randint(len(Xtest)) xtest = Xtest[idx].reshape(1, 40) ylabel = ytest[idx] ypred = model.predict(xtest)[0][0] sent = " ".join([index2word[x] for x in xtest[0].tolist() if x != 0 ]) print("{:.0f}\t{:.0f}\t{}".format(ypred, ylabel, sent)) 0 0 バルコニー エアコン クロゼット フローリング 室内 洗濯 置 シューズボックス システムキッチン 住戸 外壁 タイル 入居 ガスレンジ 都市ガス 0 0 ウォークインクロゼット 保証 不要 敷金 バイク 置場 ネット 専用 回線 トランクルーム 事務所 相談 楽器 相談 トイレ ルームシェア 相談 利用 沿線 利用 徒歩 10分 専有 面積 平面 駐車場 LDK 居室 都市ガス 高速 ネット 対応 礼金 保証 会社 利用 初期 費用 カード 決済 0 0 バス トイレ エアコン ガスコンロ 対応 クロゼット フローリング 室内 洗濯 置 シューズボックス システムキッチン 脱衣所 入居 礼金 不要 最上階 敷金 ガスレンジ ダブル ロック キー 上 都市ガス 0 0 室内 洗濯 置 焚 機能 浴室 住戸 脱衣所 洗面所 独立 駐輪場 光ファイバー 入居 ペット 相談 敷金 居室 フローリング 採光 収納 内装 リフォーム 済 事務所 相談 ルームシェア 相談 利用 沿線 利用 徒歩 5分 東南 都市ガス 玄関 収納 礼金 保証 会社 利用 0 0 居室 フローリング 採光 沿線 利用 内装 リフォーム 済 眺望 良好 事務所 相談 24時間 換気 システム 南面 リビング 外装 リフォーム 済 利用 利用 沿線 利用 徒歩 10分 敷地内 ごみ 置き場 都市ガス BS 保証 会社 利用 初期 費用 カード 決済 通風 良好 0 0 TV インターホン 浴室 乾燥機 オートロック 室内 洗濯 置 システムキッチン 住戸 エレベーター 洗面所 独立 コンロ 宅配ボックス 光ファイバー 外壁 タイル BS CS 防犯カメラ 保証 不要 敷金 保証金 不要 プール 利用 沿線 利用 徒歩 10分 24時間 ゴミ 敷地内 ごみ 置き場 5年 都市ガス 礼金 0 0 バルコニー エアコン クロゼット フローリング 室内 洗濯 置 シューズボックス システムキッチン 住戸 外壁 タイル 入居 ガスレンジ 都市ガス 0 1 バス トイレ バルコニー エアコン クロゼット フローリング TV インターホン 浴室 乾燥機 オートロック 室内 洗濯 置 シューズボックス システムキッチン 温水洗浄便座 エレベーター 洗面所 独立 コンロ 駐輪場 礼金 不要 バイク 置場 ガスレンジ ネット 専用 回線 利用 沿線 利用 徒歩 10分 都市ガス BS 1 1 システム 居室 フローリング ディンプルキー ダブル ロック キー 24時間 換気 システム フロント サービス 耐火構造 耐震 構造 利用 沿線 利用 徒歩 5分 24時間 ゴミ 敷地内 ごみ 置き場 セキュリティ 会社 加入 済 間接照明 LAN 保証 会社 利用 初期 費用 カード 決済 通風 良好 0 0 バス トイレ バルコニー フローリング TV インターホン 浴室 乾燥機 オートロック 室内 洗濯 置 システムキッチン 住戸 エレベーター 洗面所 独立 CATV 入居 防犯カメラ グリル 居室 洋室 仲 エアコン 納戸 徒歩 10分 専有 面積 南西 0 0 エアコン ガスコンロ 対応 クロゼット フローリング シャワー 洗面 TV インターホン 浴室 乾燥機 室内 洗濯 置 シューズボックス 温水洗浄便座 脱衣所 洗面所 独立 駐輪場 CATV 保証 不要 CATV インターネット 平坦 保証 不要 始発駅 利用 沿線 利用 徒歩 10分 バス停 徒歩 3分 南西 都市ガス BS 0 1 住戸 浴室 窓 24時間 換気 システム クロゼット ルームシェア 相談 南面 リビング 学生 相談 一部 フローリング 利用 沿線 利用 徒歩 5分 駅 徒歩 10分 24時間 ゴミ 敷地内 ごみ 置き場 都市ガス 洗面所 ドア 南面 バルコニー BS 初期 費用 カード 決済 通風 良好0 0 対面 キッチン IH クッキング ヒーター グリル ウォークインクロゼット 保証 不要 敷金 二人 入居 相談 ネット 使用 不要 テラス 保証 不要 3年 南面 リビング 浴室 利用 沿線 利用 バス停 徒歩 3分 敷地内 ごみ 置き場 LDK 都市ガス 南面 バルコニー 天井 シューズ クロゼット 礼金 0 0 バス トイレ バルコニー エアコン フローリング 室内 洗濯 置 シューズボックス 焚 機能 浴室 駐輪場 宅配ボックス 入居 礼金 不要 敷金 不要 IH クッキング ヒーター エレベーター 2基 利用 沿線 利用 徒歩 5分 都市ガス 1 1 コンロ 宅配ボックス 光ファイバー 外壁 タイル BS CS 防犯カメラ 照明 保証人 不要 敷金 沿線 利用 ディンプルキー 洗濯機 耐火構造 始発駅 沿線 利用 徒歩 10分 24時間 ゴミ 敷地内 ごみ 置き場 居室 都市ガス 高速 ネット 対応 礼金 保証 会社 利用 初期 費用 カード 決済 0 0 バルコニー エアコン クロゼット フローリング シューズボックス 住戸 エレベーター 入居 防犯カメラ 分譲 賃貸 仲 眺望 良好 保証 不要 利用 沿線 利用 徒歩 5分 敷地内 ごみ 置き場 日勤 管理 敷金 礼金 不要 通風 良好 1 1 24時間 換気 システム 南面 リビング 一部 フローリング ISDN 対応 耐火構造 耐震 構造 利用 徒歩 5分 バス停 徒歩 3分 制震 構造 高層 24時間 ゴミ 敷地内 ごみ 置き場 都市ガス 南面 バルコニー 玄関 収納 BS 高速 ネット 対応 LAN 初期 費用 カード 決済 0 0 バイク 置場 南西 住戸 ガスレンジ ディンプルキー 内装 リフォーム 済 眺望 良好 照明 センサー 利用 沿線 利用 徒歩 10分 24時間 ゴミ 敷地内 ごみ 置き場 南西 当社 管理 物件 都市ガス 洗面所 ドア 南面 バルコニー 室内 物干 礼金 保証 会社 利用 通風 良好 0 0 駅 平坦 ネット 使用 不要 ダブル ロック キー 保証 不要 2年 24時間 換気 システム 複層ガラス 照明 センサー 利用 徒歩 10分 外壁 サイディング 24時間 ゴミ 敷地内 ごみ 置き場 南西 都市ガス 玄関 収納 年内 入居 年度内 入居 礼金 初期 費用 カード 決済 0 1 フローリング TV インターホン 浴室 乾燥機 オートロック 室内 洗濯 置 陽 良好 シューズボックス システムキッチン 焚 機能 浴室 住戸 エレベーター 洗面化粧台 コンロ 駐輪場 宅配ボックス CATV 光ファイバー BS CS 対面 キッチン 沿線 利用 楽器 相談 ウッドデッキ 利用 徒歩 10分 東南 LDK 居室 都市ガス |
追記
TensorBoardの検証のloglossを見てみます。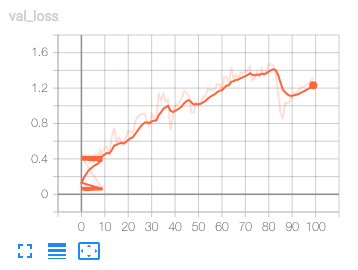 エポックに対してloglossが非常に荒れています。学習曲線としてはセオリー的にアウトなようです。一方で、検証のAUCはエポックに従って高まるようです。
エポックに対してloglossが非常に荒れています。学習曲線としてはセオリー的にアウトなようです。一方で、検証のAUCはエポックに従って高まるようです。
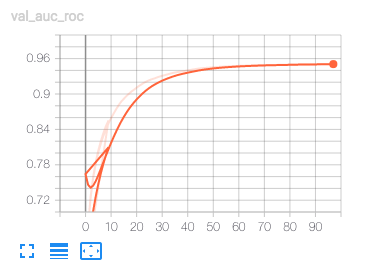 AUCは良くなっているけどloglossが増え続けている。loglossが下がらないと過学習している可能性が高いので、これは過学習しているだけなのだろう。
AUCは良くなっているけどloglossが増え続けている。loglossが下がらないと過学習している可能性が高いので、これは過学習しているだけなのだろう。
参考文献
- [1] Antonio Gulli , Sujit Pal (2018) , 『直感 Deep Learning ―Python×Kerasでアイデアを形にするレシピ』, オライリージャパン
- [2] 斎藤 康毅 (2018), 『ゼロから作るDeep Learning ❷ ―自然言語処理編』, オライリージャパン
- [3] Sebastian (2018),『[第2版]Python 機械学習プログラミング 達人データサイエンティストによる理論と実践 (impress top gear)』, インプレス
- [4] How to compute Receiving Operating Characteristic (ROC) and AUC in keras?
- [5] TimeseriesGenerator
- [6] KerasでF1スコアをmetircsに入れる際は要注意
- [7] How to Develop a Bidirectional LSTM For Sequence Classification in Python with Keras
- [8] Deep Dive into Bidirectional LSTM
- [9] Aurélien Géron (2018) , 『scikit-learnとTensorFlowによる実践機械学習』, オライリージャパン
- [10] Trains a Bidirectional LSTM on the IMDB sentiment classification task.