今年の私の中でのベスト専門書オブザイヤーな書籍、『大規模言語モデル入門』について感想を述べたり、この本の魅力を伝えて布教活動をしていきたいと思い、久しぶりにブログを書こうと思います。

対象読者のイメージ
データサイエンティストとして働いている人やそれを専門にしている学生で、原理まで詳しく知りたい奇特な人が対象読者かなと思います。全国民レベルでChat-GPTが話題になった昨今、大規模言語モデルをただ使うだけでなく、仕組みや開発までの変遷などを詳しく知りたいかたにちょうど良い本です。Chat-GPTが登場して話題になった時期よりも以前に書籍の執筆を着手していると思われるので、Chat-GPTのことだけに興味がある人はそんなに満足しないのではないでしょうか。そもそもアルゴリズム自体は公開されてないですし、そういったものは書籍に求めるものではないでしょうが。
良いと思ったポイントについて
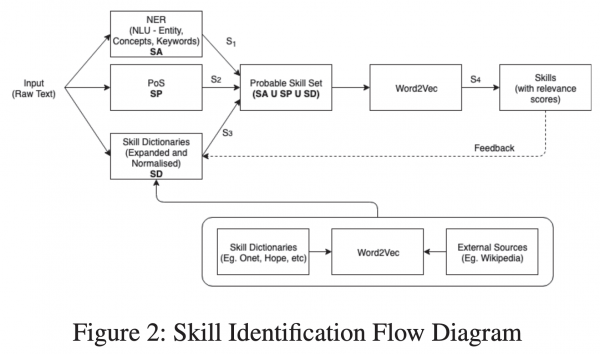
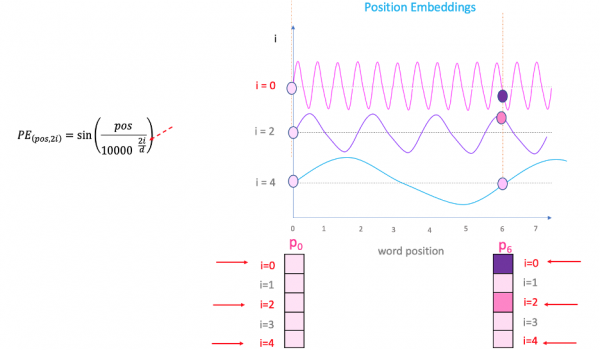
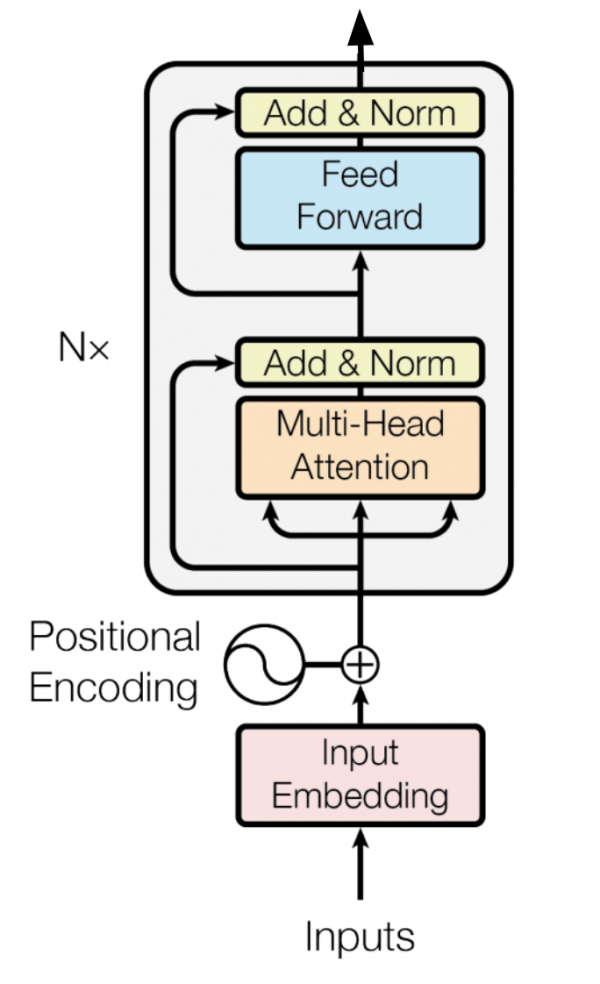
・Transformerの説明がわかりやすい
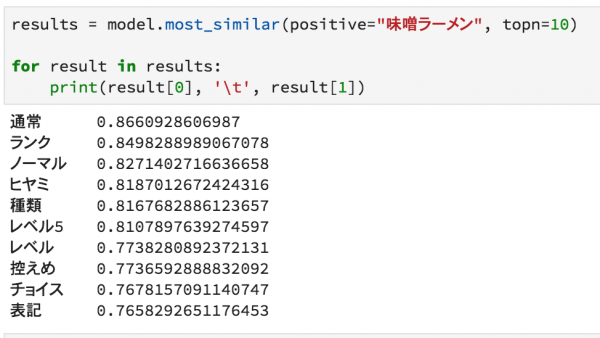
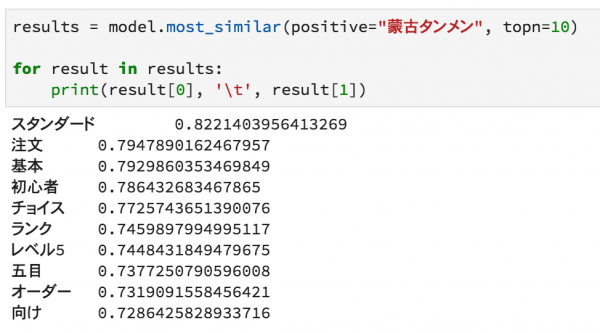
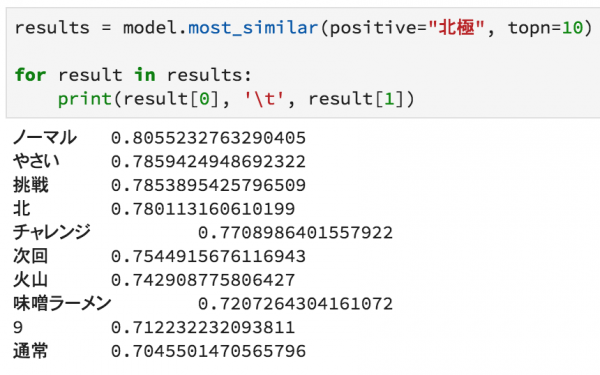
・Chat-GPTについて理解が深まるプロンプトによる言語モデルの制御について記されている
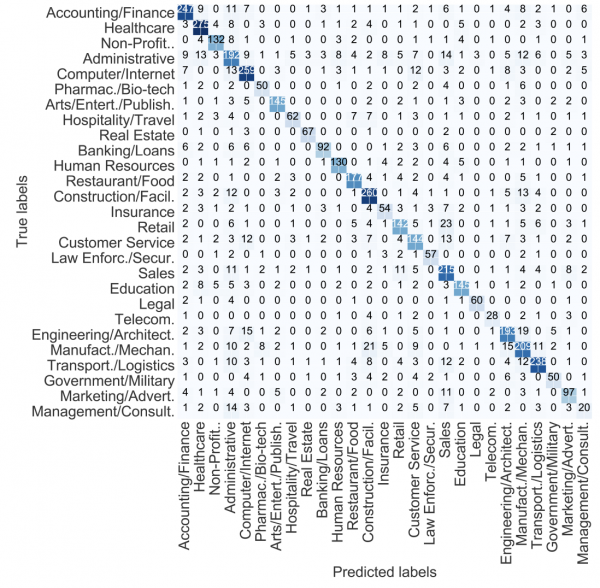
・感情分析、質問応答、固有表現抽出、要約生成、類似文書検索などの実装例が紹介されており、実務で使えそう
・個々の実装例についてファインチューニングについての記述がある
・個々の実装例についてエラー分析の記述がある
・Google Colabでも頑張れるように限られたメモリでの作法が記されている
・性能アップの強い味方であるアノテーションツールの紹介がある
・文書要約技術の概要が簡潔にまとまっている、性能指標についてもわかりやすい
・Chat-GPT APIの料金見積もりを試せるスクリプトが載っている
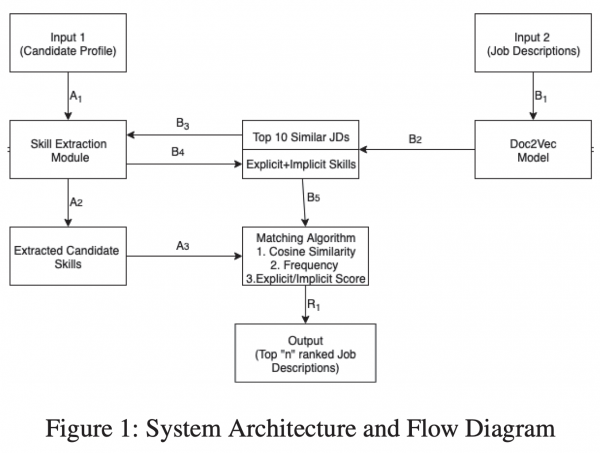
・外部の情報を大規模言語モデルで取り込み、その結果をChat-GPTに選ばさせるというアプリケーションの事例が載っている
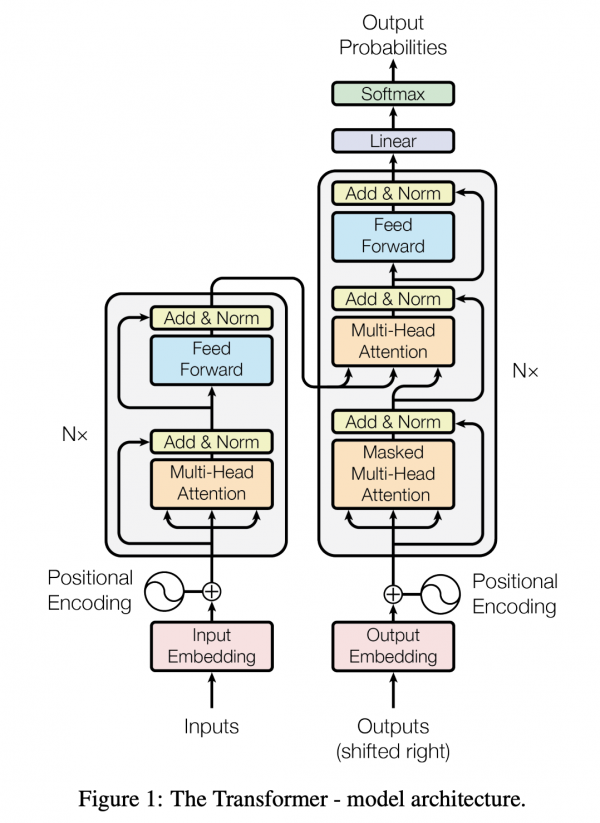
Transformerの説明がわかりやすい
余談ですが、先日私の親に、「Chat-GPT」って何?と聞かれたのですが、T、つまりTransformerの説明が一番大変でした。自分が完全に的を得た説明ができているか不安だったのですが、この書籍の説明はすごくわかりやすく、自分が説明した内容と大きな相違がなかったので安心しました。
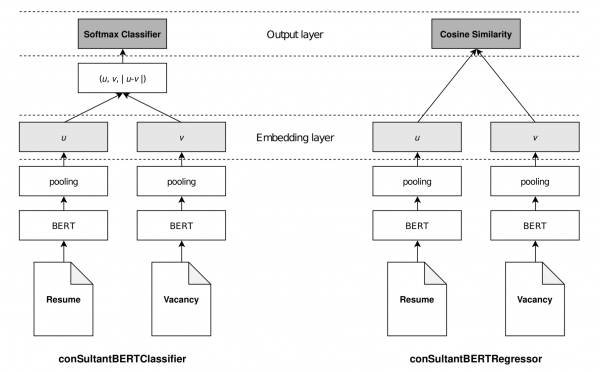
Chat-GPTについて理解が深まるプロンプトによる言語モデルの制御について記されている
zero-shot、one-shot、few-shotなどの説明から、chain-of-thought推論などプロンプトエンジニアリングについてわかりやすく解説されています。また、人間によるフィードバックのデータに関する強化学習についても記述されており、Chat-GPTの仕組みを知ることに一歩近づけます。
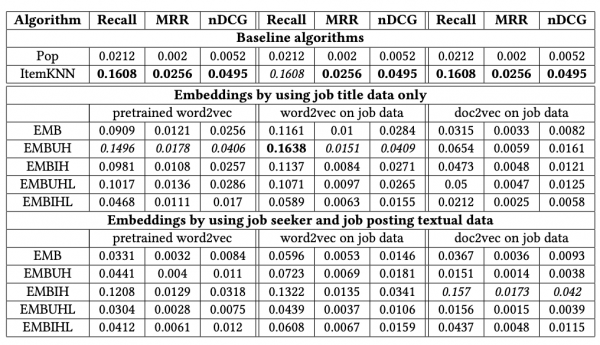
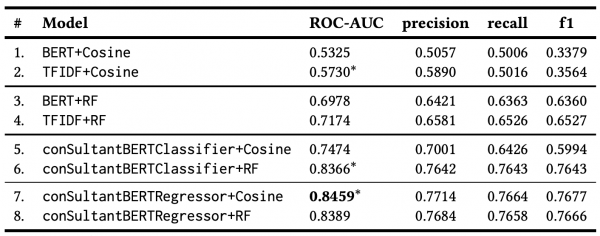
感情分析、質問応答、固有表現抽出、要約生成、類似文書検索などの実装例が紹介されており、実務で使えそう
大規模言語モデルを一般的な事業会社のデータサイエンティストが業務で使うとなると、類似文書検索や感情分析、固有表現抽出は使うイメージが湧きやすいです。そのため、この書籍は仕事で隣に置いておきたいと思いました。
個々の実装例についてファインチューニングについての記述がある
ゼロからモデルを訓練して学習するのは現実的ではない事業会社がほとんどだと思いますので、ファインチューニングという記載があるとグッときます。
個々の実装例についてエラー分析の記述がある
これまでの書籍でエラー分析について記されたものは中々なかった気がします。実務では必ず通る道ですので、「わかってらっしゃる」という気持ちでした。こういう実務で大事にしていることを書籍でしっかり記してもらえると、布教もしやすいので良いです。
Google Colabでも頑張れるように限られたメモリでの作法が記されている
多くの個人、事業会社がColab乞食をしていると思います。Colabの無料GPUはベーシックインカムなのではないかと思うくらいです。そのColabでも動かせるように思いやりのあるメモリ削減技術について紙面が割かれています。
性能アップの強い味方であるアノテーションツールの紹介がある
Label Studioというオープンソースのアノテーションツールの使い方について記されていました。このツールは知らなかったので、大変勉強になります。実務でアノテーションする機会は当然あって、3万件くらい一人でやったこともあります。。。
文書要約技術の概要が簡潔にまとまっている、性能指標についてもわかりやすい
文書要約自体をあまり業務で使うことがなかったので、無知だったのですが色々な要約の種類があったり、評価指標があって目から鱗でした。
Chat-GPT APIの料金見積もりを試せるスクリプトが載っている
クラウド破産にならないためにも重要な観点ですね!会社で稟議をあげて、ドキドキしながら使っている人がほとんどだと思うので、しっかり見積もっていきたいですね。
外部の情報を大規模言語モデルで取り込み、その結果をChat-GPTに選ばさせるというアプリケーションの事例が載っている
最後の章でChat-GPTと別の大規模言語モデルの合わせ技についての実装例が載っています。これは仕事で使えるかもと思える実装例だったので、色々やってみると思います。外部の情報(自社にしかない情報)を用いたChat-GPTならいろんな可能性が広がりますね。データ抜かれる可能性はゼロではないですが。
おわりに
大規模言語モデルの開発の流れやモデルを改良するためのテクニックについて十分な紙面が割かれていて、仕事で使える本だなと思いました。
あと、先日買ったライト目な本として、『大規模言語モデルは新たな知能か――ChatGPTが変えた世界 (岩波科学ライブラリー)』も良かったです。大規模言語モデルを開発した人間に関してもフォーカスしていて、そんなすごい人がいるんだと胸が高鳴りました。仕事で必ずいるわけではないですが、開発に至るまでの変遷も教養として知っておくのはいいかもしれませんね。





















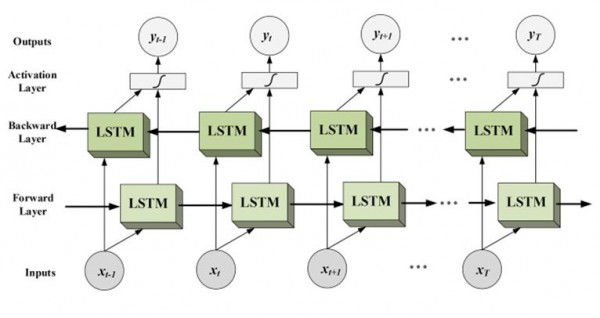 (
(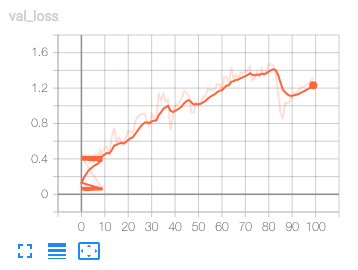 エポックに対してloglossが非常に荒れています。学習曲線としてはセオリー的にアウトなようです。一方で、検証のAUCはエポックに従って高まるようです。
エポックに対してloglossが非常に荒れています。学習曲線としてはセオリー的にアウトなようです。一方で、検証のAUCはエポックに従って高まるようです。
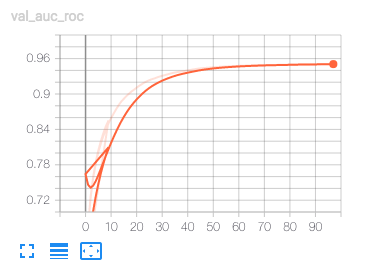 AUCは良くなっているけどloglossが増え続けている。loglossが下がらないと過学習している可能性が高いので、これは過学習しているだけなのだろう。
AUCは良くなっているけどloglossが増え続けている。loglossが下がらないと過学習している可能性が高いので、これは過学習しているだけなのだろう。