はじめに
深層学習が流行りだして久しいですが、マーケティングにおいて適用することが全くないため、学習のモチベーションを維持する事ができておりません。そろそろアカデミアの領域でマーケティング事例での深層学習の盛り上がりがあるのではないかと期待して、調べてみようと思います。
基本的に各研究ごとに
・目的と結果
・対象となるデータ
・手法の概要
・PDFのリンク
について記していきます。リンクは下の方にある参考情報を参照ください。
調べ方
いったん、皆さんの大好きなarXiv.orgに掲載されている論文の中から、マーケティングに関わりそうなものを見つけます。見つけ方としては、Google検索において、「marketing deep learning site:https://arxiv.org」するものとします。site:コマンドを使うことでarXiv.org以外の情報を弾いて検索できます。
今回紹介する研究
- Predicting online user behaviour using deep learning algorithms
- Churn analysis using deep convolutional neural networks and autoencoders
- Customer Lifetime Value Prediction Using Embeddings
Predicting online user behaviour using deep learning algorithms
目的と結果
大規模ECサイトのユーザー行動からの24時間以内での購買意図の予測を目的としており、ベースラインである既存の手法と比べて、深層学習の手法(Deep Belief Networks・Stacked Denoising auto-Encoders)が予測において勝り、不均衡データの分類においても秀でているという結果となった。
対象となるデータ
- 6ヶ月間のECサイトのユーザー行動データ
- ユーザーID
-
タイムスタンプ
-
イベントタイプ
- 商品のPageView(価格などの詳細データが伴う。商品数は25,000個)
- カゴのPageView(価格などの詳細データが伴う。)
- 購入
- 広告クリック(今回の分析では無視)
- 広告ビュー(今回の分析では無視)
手法の概要
- 前処理
・購入までのセッション期間
・ユーザーごとの購入に対するクリックの比率
・購入までのセッション数の中央値
・商品の説明文
・商品の価格
・商品に費やされたセッション時間の合計
・セッションが発生した時刻
・セッション単位でのクリック数
・セッション単位での購入した商品の平均価格
・過去24時間でのページビュー数
・先週のページビュー数- 購入アイテムの説明文に対して、word2vecにより50次元の分散表現を作成しその算術平均をとった。
- サイトにおいてクリック数が10回以下のユーザーのデータを除外。
- 特徴量の次元圧縮のためにNMF(Non-Negative Matrix Factorization)を適用。
- アルゴリズム(評価方法はAUC、10分割交差検証。Kerasで実行。)
- Deep Belief Networks
2006年にHintonが提案した教師なし学習アルゴリズム。制約付きボルツマンマシン(RBM)を多数重ねて、最上位層だけ無向でそれ以外は下層への有向エッジを伴うネットワーク。
RBMよりも複雑なデータ生成の仕組みをモデル化することができるとされている。 - Stacked Denoising auto-Encoders
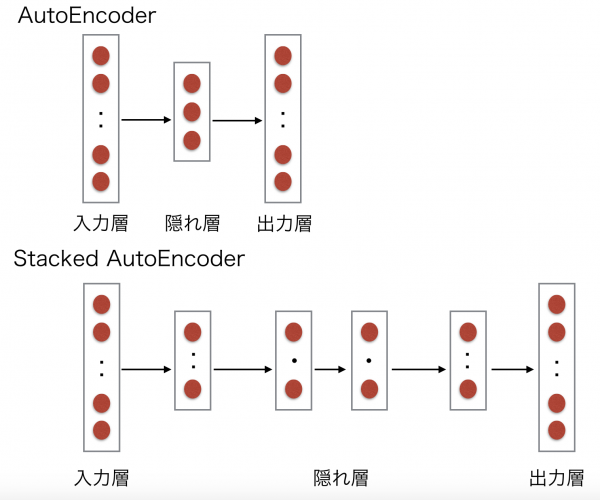
AutoEncoderは出力データが入力データをそのまま再現するニューラルネットワークで、入力層から中間層への変換器をencoder、中間層から出力層への変換器をdecoderと呼ぶ。
そのAutoEncoderを高次元に写像できるように改良したものがDenoising auto-Encodersと言われています。
さらに、そのDenoising auto-Encodersを層ごとに学習し積み重ねて教師ありの学習器を繋いだものをStacked Denoising auto-Encodersと呼びます。 - 決定木
- ランダムフォレスト
- Drop outによる正則化
過学習を避けるために、ランダムに隠れ層や入力層を除いている。
- Deep Belief Networks
PDFのリンク
Predicting online user behaviour using deep learning algorithms
Churn analysis using deep convolutional neural networks and autoencoders
目的と結果
電話通信業におけるユーザーの解約予測を行うことを目的とし、深層学習を用いた予測の結果、既存手法よりも精度が高いことがわかった。
また、解約予測だけでなく、解約理由を探るに際しての可視化においてもAutoencoderを用いることで理解が深まることが示されている。
対象となるデータ
- ユーザー情報(おそらく携帯電話会社であるタイのトゥルー・コーポレーションのデータ)
- データ使用量
モバイルのプリペイド補充金額
モバイルのプリペイド補充頻度
音声通話
通話時間
SMSメッセージ
など
- データ使用量
手法の概要
- ユーザーの情報を画像のように扱う。各々の行が日にちを表し、各々の列がユーザー行動の種類を表す。
- 二値変数の定義
解約の定義は30日間行動が観察されなかったかどうか。(解約率は3.57%)
最後の通話は過去14日間での通話として、最後の14日間に記録のなかったユーザーは分析対象から除外している。プロアクティブな解約予測をするに祭して、すでに解約してしまったと思われる人を除外するということとなる。 - ユーザー行動を画像のように変換したデータに対してCNN(Convolutional Neural Network)を実行しています。
CNNの構成としては、
・2連続のConvolutional Layer
・2×1の最大Pooling Layer
・128個のFully Connected Layer
・バイナリーな結果を返すsoftmax output
となっています。 - 訓練データとテストデータは80:20で分割
- Docker上で環境を構築
- オープンソースライブラリとしてはTheano、TensorFlow、Kerasを利用。
- ユーザー理解のためにAutoencoderを適用している。
PDFのリンク
Churn analysis using deep convolutional neural networks and autoencoders
Customer Lifetime Value Prediction Using Embeddings
目的と結果
手探りで特徴量を構築してきた、既存のCustomer Lifetime Value(CLTV)の算出手法に勝るモデルを作ることを目的とし、十分なデータがあれば、既存の特徴量よりも予測パフォーマンスにおいて秀でていることが示されている。しかしながら、ランダムフォレストを超えるレベルの精度を追求するとニューロンの数を大幅に増やす必要があり、計算コストがかかるため商業的なバリューにおいて懸念がある。
対象となるデータ
- ユーザー情報(アパレルECサイトのASOS.comのデータ)
注文数
注文日の標準偏差
直近四半期のセッション数
売り上げ
など
手法の概要
- 特徴量の生成
word2vecを行うに際して、単語の代わりとしてユーザーの商品ビューデータを入力としてニューラルネットワークによる分散表現の生成を行なっている。出力層において、全てのユーザーへのノードがあり、ユーザー数が1億人近くいるため計算が膨大になってしまうが、Negative Sampling(NE)によるSkipGramを行うことで、計算の高速化(近似による計算コストの低減)が図られている。分散表現の次元は32-128次元までが望ましい傾向を示している。 - Hybridモデルの適用
既存の特徴量に分散表現を加えた、ロジスティック回帰とのHybridなDNNによるモデルの適用を行なっている。 - CLTVの研究ながらも、予測し検証する目的変数は解約(12ヶ月購買なし)の有無。
- 検証用のデータは5万人のユーザーデータ
- ベースラインとの比較となる評価指標はAUCが使われている。ベースラインはロジスティック回帰とランダムフォレスト。
- オープンソースライブラリとしてはTensorFlowを利用。GPUはTesla K80を利用。
PDFのリンク
Customer Lifetime Value Prediction Using Embeddings
まとめ
- ユーザーの行動ログに対して、縦を時間、横にカテゴリとして画像データのように扱うアプローチを知れた。
- データ数が十分に多そうな企業の適用例が多かったが、扱うデータの規模感が少しわかった。
- 画像や音声ではなく、ユーザーデータにおいてもDNNでランダムフォレストを超える精度を叩き出せる可能性はあるが、計算コストがかかってしまい商業的なバリューが下がってしまう可能性もある。
- ログや閲覧したページのコンテンツベースに生成した分散表現を特徴量とするアプローチが3例中、2例あった。
データ量の観点からまだまだ社内での適用は視野に入っていないですが、私のDNN理解も浅いので、今回のような分析事例をモチベーションにして勉強を進め適用可能性を探っていきたいと思います。
参考情報
Chainer v2による実践深層学習
深層学習 (機械学習プロフェッショナルシリーズ)
Stacked Denoising Autoencoderを用いた語義判別
Dropoutの実装と重みの正則化
RBMから考えるDeep Learning ~黒魔術を添えて~
Convolutional Neural Networkとは何なのか