はじめに
今回で3回目となるR advent Calendarですが、前回は「一発屋芸人の検索トレンドのデータ」を扱い、前々回は「ポケモンのデータ」を扱いました。今回は人の命に関わるようなデータを扱ってみたいと思い、某サイトから東京都の23区内における事故物件の住所と詳細を集めてきました。どのようなエリアが事故が起きやすいのかの分析を行います。(以下では、事故物件をAP(Accident Property)と呼びます。)
R advent calendar用に向けたデータ収集コードができたが、データがけっこう汚いのでアノテーション工数を覚悟したほうが良さそう。
今回は人の命に関わるデータですね。— SKUE (@Mr_Sakaue) December 8, 2019
分析工程
・データの収集
・データの整形
・可視化
・分析
データの収集
APに関する情報を某サイトより集める必要があります。そこで必要なライブラリとしては、RSeleniumやtwitteRがあげられます。
twitteRが必要な理由は、APに関するサイトにAPの一覧ページがなく、公式アカウントがAPに関するページのリンクを投稿しているところにあります。ただ、私が以前使っていた頃とはTwitterAPIの仕様が変わり、3ヶ月よりも前の情報にアクセスできなくなっていました。そのため、今後のデータに関してはTwitterAPIでいいのですが、過去のものに関しては別アプローチが必要となります。
また、APに関するサイトはJavaScriptで地図が表示されているだけなので、RSeleniumを使って地図をクリックさせ、表示された情報をスクレイピングするなどの処理が必要となります。
当初の想定ではTwitterのデータ収集、リンク先の情報をRSeleniumでスクレイピングするだけの簡単な仕事だと思っていたのですが、過去のデータにアクセスできないので、地図上で一つ一つ見つけていくためにRSeleniumだけで頑張ることにしました。(私の過去のアドカレ史上、一番面倒なデータとなりました。)
誰もやらないと思うのですが、一応手順を記しておきます。
RSeleniumだけでMapからAPの情報を抽出するための手順
1.都内の住所一覧を収集
2.検索窓に住所を入力
3.検索結果一覧の上位5件をクリック
4.一度地図を引くことでAPを広い範囲で捉えれるようにする
5.APのマークの要素を取得し、1件ずつクリックし、表示されたAPの情報をデータフレームに格納する
こちらが取得できたデータです。
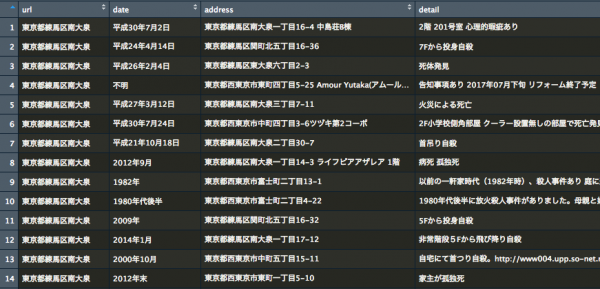
RSeleniumでAPの
・住所
・発生時期(フリーテキスト)
・AP詳細
・投稿日
を集めることができるので、その住所データに対して、Yahoo!のジオコードに関するAPIを利用します。(利用申請が必要なはずです。4年前くらいに申請していたのでそのまま使えました。)
Yahoo!のAPIを使えば、住所から緯度経度の情報を取得することができます。
APの緯度経度がわかれば、jpmeshパッケージを用いて1kmメッシュやら10kmメッシュやらのメッシュデータに変換することができます。
jpmeshを用いてメッシュデータに変換し、メッシュ単位でAPの発生件数を集計します。
データ収集用のソースコードは思いのほか長くなってしまったので、GitHubにあげておきました。
https://github.com/KamonohashiPerry/r_advent_calendar_2019
ここで再度、手順を整理しておきましょう。
Twitterに出てきたものだけを取得(直近3ヶ月〜)する場合、
run_tweet_collect.RでTweetを収集
↓
run_selenium.RでAPの情報をスクレイピング
↓
run_map_api.Rで住所から緯度経度の取得
↓
making_mesh_data_and_download_other_data.Rで緯度経度からメッシュデータへの変換、その他の人口データや地価データと接続をします。
直近3ヶ月以前のものを取得する場合、
run_selenium_from_map.Rで地図上から直接APの情報を取得する
↓
making_mesh_data_and_download_other_data.Rで緯度経度からメッシュデータへの変換、その他の人口データや地価データと接続をします。
データの整形
APの1kmメッシュデータを手に入れたら、kokudosuuchiパッケージを使って国土地理院の収集したデータをつなぎこみます。手順としては、以下のとおりです。
まずは推計人口というそのエリアの人口の予測値です。今回は2010年のものを抽出しました。こちらは1kmメッシュのデータなので、変換することなく使えて都合が良いです。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
library(kokudosuuchi) # 推計人口 estimated_population <- getKSJData("http://nlftp.mlit.go.jp/ksj/gml/data/m1000/m1000-17/m1000-17_GML.zip", cache_dir = "cached_zip") estimated_population_df <- data.frame(one_k_mesh=estimated_population$Mesh3_POP_00$MESH_ID, city_code=estimated_population$Mesh3_POP_00$CITY_CODE, population=estimated_population$Mesh3_POP_00$POP2010) estimated_population_df <- estimated_population_df %>% mutate(one_k_mesh=as.integer(one_k_mesh)) |
続いて、2015年の公示地価を抽出しました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 公示地価 published_land_price <- getKSJData("http://nlftp.mlit.go.jp/ksj/gml/data/L01/L01-15/L01-15_GML.zip", cache_dir = "cached_zip") published_land_price_df <- data.frame(price=as.integer(published_land_price$`L01-15`$L01_006), address=as.character(published_land_price$`L01-15`$L01_019), area_code=as.integer(published_land_price$`L01-15`$L01_017)) for (i in 1:nrow(published_land_price_df)) { published_land_price_df$latitude[i] <- as.character(published_land_price$`L01-15`$geometry[[i]][2]) published_land_price_df$longitude[i] <- as.character(published_land_price$`L01-15`$geometry[[i]][1]) } # 東京23区の地価に絞り込む published_land_price_df_tokyo <- published_land_price_df %>% filter(stringr::str_detect(address,"東京"), stringr::str_detect(address,"区")) published_land_price_df_tokyo$address_fixed <- gsub(pattern = " ", replacement = "", published_land_price_df_tokyo$address) published_land_price_df_tokyo$address_fixed <- stringi::stri_trans_nfkc(published_land_price_df_tokyo$address_fixed) for (i in 1:nrow(published_land_price_df_tokyo)) { published_land_price_df_tokyo$address_fixed[i] <- strsplit(published_land_price_df_tokyo$address_fixed,split="[0-9]")[[i]][1] } |
こちらはメッシュデータではないので、緯度経度の情報から1kmメッシュのデータに変換する必要があります。後で行います。
単純集計・可視化
今回のデータセットのデータ数は3919件です。本当は7000件以上はあると思われますが、マップから取ってくるという勝手上、なかなか全てを取り切ることができませんでした。
まずは、1kmメッシュごとのAP発生件数のヒストグラムです。
|
1 2 3 4 5 |
g <- ggplot(data = estimated_population_df_tokyo %>% filter(accident_count>0), aes(accident_count)) + theme_set(theme_bw(base_size = 14,base_family="HiraKakuProN-W3")) g <- g +geom_histogram(bins = 50) g <- g + ggtitle("1kmメッシュごとのAP件数のヒストグラム") g |
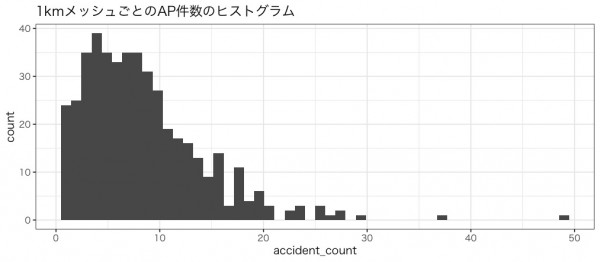
1kmメッシュにおける人口のヒストグラムです。
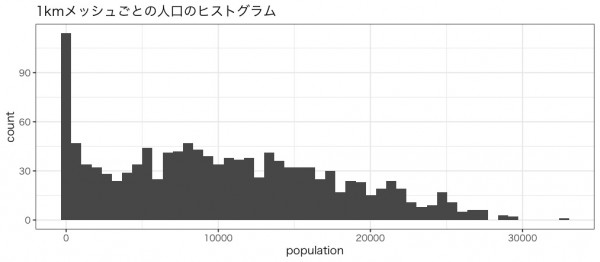
公示地価のヒストグラムです。
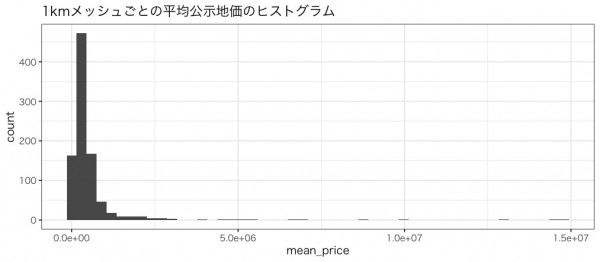
1kmメッシュにおける人口あたりのAP件数のヒストグラムです。
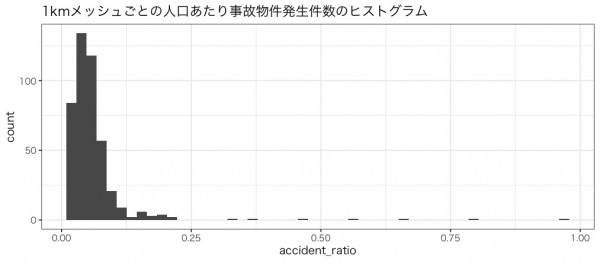
分析
ここでは、色々な軸でAPのデータに向き合ってみようと思います。
APの発生件数の集計
人口が多いところがAPの発生件数が多いところだと思われますが、とりあえず確認します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
> estimated_population_df_tokyo %>% group_by(市区町村) %>% summarize(sum_accident=sum(accident_count), population=sum(population), mean_accident_percapita=mean(accident_percapita_100)) %>% arrange(desc(sum_accident)) Simple feature collection with 49 features and 4 fields geometry type: GEOMETRY dimension: XY bbox: xmin: 139.15 ymin: 35.5 xmax: 139.9125 ymax: 35.84167 epsg (SRID): NA proj4string: NA # A tibble: 49 x 5 市区町村 sum_accident population mean_accident_percap… poligon <chr> <dbl> <dbl> <dbl> <GEOMETRY> 1 世田谷区 343 952572. 0.0337 POLYGON ((139.675 35.60833, 139.6875 35.60833, 139.6875 35.6, 139.675 35.6… 2 新宿区 302 398145. 0.0795 POLYGON ((139.7 35.69167, 139.7 35.68333, 139.6875 35.68333, 139.6875 35.6… 3 大田区 291 803602. 0.03 MULTIPOLYGON (((139.775 35.55, 139.7875 35.55, 139.7875 35.55833, 139.775 … 4 板橋区 283 471726. 0.0570 POLYGON ((139.7125 35.75, 139.7125 35.74167, 139.7 35.74167, 139.7 35.75, … 5 練馬区 276 575022. 0.0484 POLYGON ((139.6875 35.74167, 139.6875 35.73333, 139.675 35.73333, 139.6625… 6 杉並区 268 549477. 0.0477 POLYGON ((139.65 35.675, 139.65 35.66667, 139.6375 35.66667, 139.6375 35.6… 7 中野区 214 332012. 0.0619 MULTIPOLYGON (((139.675 35.69167, 139.675 35.68333, 139.6625 35.68333, 139… 8 豊島区 203 278974. 0.0723 POLYGON ((139.725 35.725, 139.725 35.71667, 139.7125 35.71667, 139.7125 35… 9 港区 159 188168. 0.137 MULTIPOLYGON (((139.7875 35.63333, 139.7875 35.625, 139.775 35.625, 139.77… 10 品川区 159 325433. 0.0382 POLYGON ((139.7625 35.59167, 139.7625 35.58333, 139.75 35.58333, 139.75 35… # … with 39 more rows |
世田谷区は最も人口が多いことから、AP発生件数では一番となっています。続いて、歌舞伎町などがある新宿が来ています。しかしながら、人口に占めるAP発生件数で言うと、港区がかなり高く出ているのがわかります。
人口あたりのAP件数
ここでは、メッシュデータをsfパッケージ用のオブジェクトに変換して、1kmにおける人口あたりのAP発生割合を可視化しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 |
library(jpmesh) library(sf) library(tidyverse) library(kokudosuuchi) library(jpndistrict) library(mapview) # load dataset load(file = "accident_df_with_coordinate_from_map.RData") # メッシュデータの追加 accident_df <- accident_df %>% mutate(k_mesh="") accident_df <- accident_df %>% filter(latitude != "", !is.na(upload_date)) # 緯度、軽度の情報から任意のメッシュのデータを得る for (i in 1:nrow(accident_df)) { accident_df$k_mesh[i] <- jpmesh::coords_to_mesh( as.numeric(accident_df$longitude[i]), as.numeric(accident_df$latitude[i]), mesh_size = "1km") } # メッシュを整数にする accident_df <- accident_df %>% mutate(k_mesh=as.integer(k_mesh)) # 東京都に絞る accident_df <- accident_df %>% filter(stringr::str_detect(formatted_address,"東京")) accident_df %>% group_by(k_mesh) %>% count() %>% arrange(desc(n)) # 公示地価 published_land_price <- getKSJData("http://nlftp.mlit.go.jp/ksj/gml/data/L01/L01-15/L01-15_GML.zip", cache_dir = "cached_zip") published_land_price_df <- data.frame(price=as.integer(published_land_price$`L01-15`$L01_006), address=as.character(published_land_price$`L01-15`$L01_019), area_code=as.integer(published_land_price$`L01-15`$L01_017)) for (i in 1:nrow(published_land_price_df)) { published_land_price_df$latitude[i] <- as.character(published_land_price$`L01-15`$geometry[[i]][2]) published_land_price_df$longitude[i] <- as.character(published_land_price$`L01-15`$geometry[[i]][1]) } # 東京の地価に絞り込む published_land_price_df_tokyo <- published_land_price_df %>% filter(stringr::str_detect(address,"東京"), stringr::str_detect(address,"区")) published_land_price_df_tokyo$address_fixed <- gsub(pattern = " ", replacement = "", published_land_price_df_tokyo$address) published_land_price_df_tokyo$address_fixed <- stringi::stri_trans_nfkc(published_land_price_df_tokyo$address_fixed) for (i in 1:nrow(published_land_price_df_tokyo)) { published_land_price_df_tokyo$address_fixed[i] <- strsplit(published_land_price_df_tokyo$address_fixed,split="[0-9]")[[i]][1] } # 緯度経度を1kmメッシュにする for (i in 1:nrow(published_land_price_df)) { published_land_price_df$mesh[i] <- jpmesh::coords_to_mesh( as.numeric(published_land_price_df$longitude[i]), as.numeric(published_land_price_df$latitude[i]), mesh_size = "1km") } published_land_price_df <- published_land_price_df %>% mutate(mesh=as.integer(mesh)) published_land_price_df_summary <- published_land_price_df %>% group_by(mesh) %>% summarise(mean_price=mean(price)) # 推計人口 estimated_population <- getKSJData("http://nlftp.mlit.go.jp/ksj/gml/data/m1000/m1000-17/m1000-17_GML.zip", cache_dir = "cached_zip") estimated_population_df <- data.frame(one_k_mesh=estimated_population$Mesh3_POP_00$MESH_ID, city_code=estimated_population$Mesh3_POP_00$CITY_CODE, population=estimated_population$Mesh3_POP_00$POP2010) estimated_population_df <- estimated_population_df %>% mutate(one_k_mesh=as.integer(one_k_mesh)) accident_summary <- accident_df %>% group_by(k_mesh) %>% summarise(accident_count=n()) %>% arrange(desc(accident_count)) estimated_population_df <- estimated_population_df %>% left_join(accident_summary, by = c("one_k_mesh"="k_mesh")) estimated_population_df$accident_count <- replace_na(estimated_population_df$accident_count, 0) estimated_population_df <- estimated_population_df %>% mutate(accident_percapita=accident_count/population) estimated_population_df <- estimated_population_df %>% left_join(published_land_price_df_summary, by=c("one_k_mesh"="mesh")) estimated_population_df <- estimated_population_df %>% mutate(accident_ratio_class=if_else(estimated_population_df$accident_percapita > 0.05, "0.05以上", if_else(estimated_population_df$accident_percapita > 0.01, "0.01以上","0.01未満"))) estimated_population_df <- estimated_population_df %>% mutate(accident_percapita_100 = round(estimated_population_df$accident_percapita*100,2) ) estimated_population_df_tokyo <- estimated_population_df %>% filter(city_code>=13000, city_code<13300) estimated_population_df_tokyo <- estimated_population_df_tokyo %>% mutate(poligon="") for (i in 1:nrow(estimated_population_df_tokyo)) { estimated_population_df_tokyo$poligon[i] <- export_mesh(estimated_population_df_tokyo$one_k_mesh[i]) } # sfオブジェクトに変換 estimated_population_df_tokyo <- sf::st_as_sf(estimated_population_df_tokyo) # マップでの可視化 estimated_population_df_tokyo %>% mapview::mapview(zcol = "accident_percapita_100") |
こちらのmapviewパッケージで作ったマップはインタラクティブにいじることができます。ぜひ関心のあるエリアでいじってみてください。
1kmメッシュ人口あたりのAP発生件数(×100)の可視化
1kmメッシュでのAP発生件数の可視化
比率ベースで、色の明るいメッシュのところを見ると、港区、中央区、新宿区、渋谷区などがAPが発生しやすいようです。件数ベースで言うと新宿が一番多いですね。
一番色が明るい港区はてっきり六本木ではないかと思ったのですが、新橋から日比谷にかけたエリアでした。会社員による自○が多いようです。恐ろしいものです。
APの名前の集計
APの名前を集計してみます。これは別にこの名前だからAPになりやすいというわけではなく、単純に数が多いだけの可能性がありますし、実際にそうだろうと思われます。AP発生率を知るには、APではないものも含めた全物件名に占めるAP発生件名を手に入れないといけませんが、全物件名を収集するのが難しいことから単純に頻度の集計となります。今回は、wordcloud2パッケージを使って、ワードクラウドにしてみます。文字が大きいと頻度が高いものとなります。
|
1 2 3 4 5 6 7 8 |
library('wordcloud2') library(RMeCab) load(file = "accident_df_with_coordinate__from_map.RData") address_bow <- docMatrixDF(accident_df$address,minFreq=1) word_list <- data.frame(word=rownames(address_bow), count=rowSums(address_bow)) word_list %>% filter(count<100, !stringr::str_detect(word, "[0-9]")) %>% wordcloud2() |

ハイツ、荘、コーポ、マンション、号棟、アパート、ハウスなどが多く出現しているようです。ただ、物件の名前としても頻度が高いとも考えられますね。
地価と人口あたりのAP発生件数の関係
ここでは地価のデータとAP発生の関係性について見てみます。
|
1 2 3 4 5 6 7 8 9 |
estimated_population_df_tokyo <- estimated_population_df_tokyo %>% mutate(bin = ntile(mean_price, 10)) vis_df <- estimated_population_df_tokyo %>% filter(accident_count>0) %>% group_by(bin) %>% summarize(mean_accident_percapita=mean(accident_percapita), count=n(), mean_price=mean(mean_price)) g <- ggplot(data = vis_df, aes(x = bin, y =mean_accident_percapita)) + theme_set(theme_bw(base_size = 14,base_family="HiraKakuProN-W3")) g <- g +geom_point() + stat_smooth(se=T,fullrange = T,level = 0.95) g <- g + ggtitle("地価の階級値と平均人口あたりのAP発生件数") g |
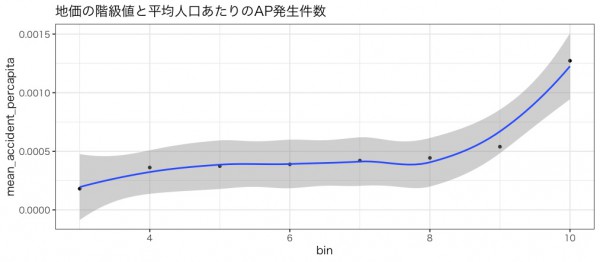
地価の階級値(10個のパーセンタイルに分割)を横軸に、縦軸に人口あたりAP発生数をおくと、地価が上がるに従い人口あたりAP発生数が高まる傾向があります。これは、人口密度が高く地価の高いところではAPが発生しやすいということを示しているのではないでしょうか。人口密度が高いと地価があがる、人口密度が高いと治安が悪くなるという可能性が考えられます。
APの詳細の集計
ここではAPになってしまった詳細の内容について先ほどと同様に形態素解析を行いワードクラウドにしてみます。
|
1 2 3 |
accident_bow <- docMatrixDF(accident_df$detail,minFreq=1) word_list <- data.frame(word=rownames(accident_bow), count=rowSums(accident_bow)) word_list %>% filter(count<300, !stringr::str_detect(word, "[0-9]")) %>% wordcloud2() |

どうやら孤独死が多いようです。高齢者の人口構成比が関係しているのだろうと思われます。
APの発生時期に関するテキストマイニング
ここでは、発生時期に含まれる四桁の数字を集計して、何年くらいのAPが多いのかをざっくりと掴みます。
|
1 2 3 |
date_bow <- docMatrixDF(accident_df$date,minFreq=1) word_list <- data.frame(word=rownames(date_bow), count=rowSums(date_bow)) word_list %>% filter(stringr::str_detect(word, "[0-9][0-9][0-9][0-9]")) %>% wordcloud2() |

どうやら昔のデータはあまり登録されていないようです。記憶が確かではないかもしれませんし、古すぎるものは消されているのかもしれませんね。あのサイトはユーザー生成コンテンツ(UGC)なので、投稿する人はそこまで昔のことをわざわざ投稿しないのかもしれないですね。
APの詳細に関するテキストマイニング
ここではトピック数10として、topicmodelsパッケージを使いLDAを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
library(RMeCab) library(topicmodels) accident_df$detail_fixed <- gsub(x = accident_df$detail, pattern = "\\(|\\)|(|)|/|\\.|:|_|-|[0-9]|[0-9]", replacement = " ") # Bag of wordsの生成 res <- docMatrixDF(accident_df$detail_fixed,minFreq=4) colnames(res) <- accident_df$k_mesh res <- t(res) res <- res[rowSums(res) >=1, ] # トピック数 k <- 10 # 出力単語数 i <- 5 # 出力トピック数 j <- 5 # LDAの推定 LDA_estimate <- LDA(res, k,method="Gibbs",control=list(verbose=1)) # トピックごとの単語の出力 terms_each_topics <- data.frame(terms(LDA_estimate,i)) |
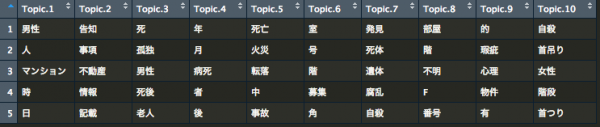
なかなか恐ろしいキーワードが多いですが、なんとなくですがうまく分類されているのではないかと思われます。
トピック1は男性の不幸
トピック2は不動産屋に言われた告知事項
トピック3は孤独死
トピック4は病死
トピック5は火災・転落・事故
トピック6は事故のあった建物に関する記載
トピック7は腐乱した事例
トピック8は建物に関して不明であることの記載
トピック9は心理的瑕疵あり
トピック10は自○
となっているように思われます。まさかこのようなデータにトピックモデルを使うことになるとは。
おわりに
今回はR言語のみを用いて、APに関するデータを収集し、地図にプロットしたり他のメッシュデータとつなぎ合わせて分析をするなどしました。APが発生しやすいエリア、APと地価との関係、APのテキストマイニングなど興味深い結果が得られたと思います。
一つ残念なのは、時系列情報がフリーテキストなので、APがどのエリアでどの頻度で発生していくのかの分析のコストが高く、今回は時系列情報を用いた分析にチャレンジできませんでした。
今後はタクシーの需要推定の分析で行われているように、メッシュ単位でのAP発生確率の推定などを機械学習で行えると面白いなと思います。どなたか一緒にアノテーションしましょう!
それでは、どうか良い年末をお過ごし下さい!
メリークリスマス!
参考情報
数多くの方々の記事を見てどうにか仕上げることができました。感謝します。
[1]【追記あり】sfパッケージでシェープファイルを読み込んでmapviewパッケージで可視化するまで
[2]How to use mesh cord in R
[3]Rを使ってワードクラウドを作ってみました
[4]国土数値情報ダウンロードサービスWeb APIからデータを取得するためのRパッケージです
[5]東京の地価公示データを眺める
[6]Chapter 1 Introduction to spatial data in R
[7][翻訳] RSelenium vignette: RSeleniumの基本
[8]RからYahoo!のジオコーディングを利用する方法
[9]EMBEDDING A LEAFLET MAP ON WORDPRESS
[10]mapview advanced controls
[11]RSeleniumでChromeからファイルをダウンロードするディレクトリを指定する方法
[12]Selenium Serverが立ち上がらないときはportが被っているかも!?
[13]brew install selenium-server-standalone
[14]ナウでヤングなRの環境変数管理方法
[15]タクシードライバー向け需要予測について
[16]LDA with topicmodels package for R, how do I get the topic probability for each term?
[17]dplyr — 高速data.frame処理