はじめに
2018年1月のTokyoR( TokyoR67に行ってきました )で機械学習結果の解釈可能性について多く語られていたので、Hello World的な試行を赤ワインのデータで行ってみたいと思います。コードは論文を書いた人のGitHubのものを拝借しました。
営業やマーケティングのメンバーに機械学習手法を提案する際に、ひとつひとつの予測結果において、なんでその予測結果になったのか理由が知りたいという要望を受けることが多いです。
ある講演で、実装用のモデルにランダムフォレストやSVMを使い、マネジャーに説明する用に決定木の結果を見せたとかいう話もありました。わざわざモデルを二つ作って説明のための工数を取らなくてよくなると思うと非常にありがたい技術です。事業側の解釈可能性を重視するあまり、シンプルな手法を取らざるを得ない現場には朗報ですね。
目次
・LIMEとは
・データ
・コード
・結果の解釈
・参考情報
LIMEとは
Local Interpretable Model-agnostic Explanationsの頭文字をとったもので、機械学習によって構築したモデルに関して、その予測結果を人間が解釈しやすくする技術です。
流れとしては、
- まずランダムフォレストなりXGBoostなりで分類器を作る。
- 任意のデータxを取り出し、解釈可能バージョンのx’(x’∈{0,1}で、xの非ゼロ要素を1としている。)を用意する。
- x’の周辺のデータをサンプリングする。
- サンプリングしたデータを使って、元のモデルを近似するために、モデルの距離を目的関数とした最適化問題を解く。
(K-LASSOという線形モデルの手法を使うことで、最終的に近似するモデルの変数の数を決めている。) - 学習したモデルの偏回帰係数を確認して、予測結果への影響度を見る。
という流れのようです。間違っているかもなので、参考情報をご覧になってください。
紹介動画も作られているようです。そういえば、Stanも紹介動画ありましたね。
データ
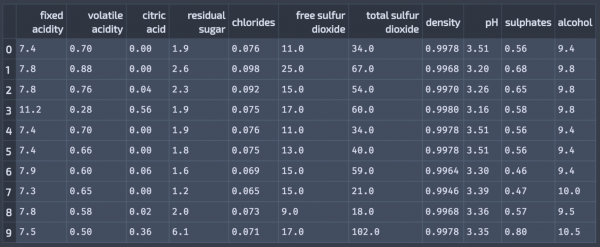
ワインデータから赤ワインのデータのみを利用します。データの詳細はこちらにあります。
http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality.names
このようなデータセットでデータサイズは1599です。
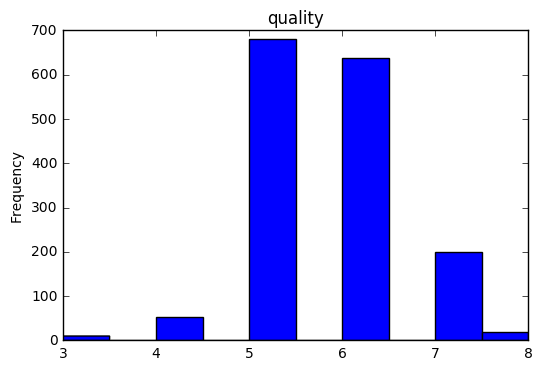
ワインの質に関するヒストグラムはこんな感じです。
今回の分析の目的
赤ワインの評価値が7以上であれば良いワイン(Y=1)、そうでなければ悪いワイン(Y=0)として、評価値が7を超えるような赤ワインの分類器を学習させ、任意のテストデータを取り出し、そのテストデータが良いワインである要因を探るものとします。
進め方
・LIMEのインストール(pip install lime で一発)
・scikit-learnによる機械学習(ランダムフォレスト)
・LIMEを用いた予測結果の解釈の提示
コード
今回のコードはこちらにもあります。
( kamonohashiperry.com/lime_study/Lime_With_Wine Data.ipynb )
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
import sklearn import sklearn.ensemble import numpy as np import lime import lime.lime_tabular import pandas as pd from __future__ import print_function np.random.seed(1) # データのインポート wine_dataset = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv", sep=";") #ワインの質に関する数値 Y = wine_dataset.quality.values #質に関するデータを落としている。 wine_dataset = wine_dataset.drop('quality', axis =1) #7よりも小さかったら0、それ以外は1とする。 Y = np.asarray([1 if i >= 7 else 0 for i in Y]) Y_label = np.asarray(['good' if i>=1 else 'bad' for i in Y]) # 訓練データ、テストデータの作成 train, test, labels_train, labels_test = sklearn.model_selection.train_test_split(wine_dataset.values, Y, train_size=0.80) # ランダムフォレストの学習 rf = sklearn.ensemble.RandomForestClassifier(n_estimators=500, class_weight="balanced" ) rf.fit(train, labels_train) sklearn.metrics.accuracy_score(labels_test, rf.predict(test)) # LIMEの計算 explainer = lime.lime_tabular.LimeTabularExplainer(train, feature_names = list(wine_dataset.columns.values), class_names = np.unique(Y_label.astype('<U10')), discretize_continuous=True) |
結果を解釈する以前に、二値分類モデルとして精度が低かったら元も子もないので、精度やAUCを確認してみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# accuracyの計算 sklearn.metrics.accuracy_score(labels_test, rf.predict(test)) 0.93125 # confusion_matrixの確認 sklearn.metrics.confusion_matrix(labels_test, rf.predict(test)) array([[284, 4], [ 18, 14]]) # AUCの計算 fpr, tpr, thresholds = sklearn.metrics.roc_curve(labels_test, rf.predict(test), pos_label=1) sklearn.metrics.auc(fpr, tpr) 0.7118055555555556 |
scikit-learnの引数でclass_weight=”balanced”にしているので、少しは不均衡データに対応できているようです。AUCは8割を超えたかったですが、いったんこれで進めます。
結果の解釈
こちらのコードで、ランダムにインスタンスを選んで、その予測結果とその予測結果に影響を与えている変数を見てみます。
|
1 2 3 4 |
i = np.random.randint(0, test.shape[0]) exp = explainer.explain_instance(test[i], rf.predict_proba, num_features=2, top_labels=1) exp.show_in_notebook(show_table=True, show_all=False) |

どうやら、このインスタンスを良いワインと予測しており、sulphates(硫酸)が0.74を超えていた、volatile acidity(酢酸とその派生物質)が0.39よりも小さいというのが理由のようです。画像では結果が消えていますが、exp.as_list()で結果を抽出できます。
著者のコードには続きがあって、このインスタンスに対して、値を足したりすることで分類確率がどのように変わるのかが記されていました。今回はアルコールを3%ポイント増やして、総亜硫酸濃度を30増やしてみるものとします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
feature_index = lambda x: list(wine_dataset.columns.values).index(x) print('Increasing alcohol') temp = test[i].copy() print('P(Bad) before:', rf.predict_proba(temp.reshape(1,-1))[0,0]) temp[feature_index('alcohol')] = test[i][feature_index('alcohol')] + 3 print('P(Bad) after:', rf.predict_proba(temp.reshape(1,-1))[0,0]) print () print('Increasing total sulfur dioxide') temp = test[i].copy() print('P(Bad) before:', rf.predict_proba(temp.reshape(1,-1))[0,0]) temp[feature_index('total sulfur dioxide')] = test[i][feature_index('total sulfur dioxide')] + 30 print('P(Bad) after:', rf.predict_proba(temp.reshape(1,-1))[0,0]) print() print('Increasing both') temp = test[i].copy() print('P(Bad) before:', rf.predict_proba(temp.reshape(1,-1))[0,0]) temp[feature_index('alcohol')] = test[i][feature_index('alcohol')] + 3 temp[feature_index('total sulfur dioxide')] = test[i][feature_index('total sulfur dioxide')] + 30 print('P(Bad) after:', rf.predict_proba(temp.reshape(1,-1))[0,0]) |

これを見る限り、アルコールを3%ポイント増やすと、悪いワインの確率が6.2%ポイントあがり、総亜硫酸濃度を30増やすと、悪いワインの確率が49.8%ポイントあがることが示されています。
ワインあまり飲まないので結果の解釈以前に変数の解釈ができていないのは今回のオチになるんでしょうか。このコードをもとに、仕事現場で使ってみようと思います。きっと解釈できるはず。
参考情報
“Why Should I Trust You?” Explaining the Predictions of Any Classifier
lime/doc/notebooks/Tutorial – continuous and categorical features.ipynb
3.2.4.3.1. sklearn.ensemble.RandomForestClassifier
機械学習と解釈可能性 by Sinhrks
機械学習モデルの予測結果を説明するための力が欲しいか…?
LIMEで機械学習の予測結果を解釈してみる
ワインの味(美味しさのグレード)は予測できるか?(1)