目次
・はじめに
・データ収集
・Rによる分析
・LDAの結果
・参考文献
はじめに
前回の投稿でBillboardの週次洋楽ランキングデータをWebスクレイピングで取得し、楽曲の消費サイクルのような順位の挙動を確かめることができました。(某洋楽ヒットチャートの週次ランキングデータをBeautiful Soupで集めてみた)今回は、歌詞の情報を用いて順位データとつなぐことにより、どのような単語の入っている洋楽がBillboardにおいてTop10に入る傾向があるのかをLDAを行うことで確かめたいと思います。
データ収集
残念なことに、Billboardのサイトに歌詞の情報は載っていません。そこで、洋楽の歌詞が取り上げられている某サイトをPython(3系)でWebスクレイピングし、名寄せを頑張って順位データと歌詞データを繋ぎます。
幸いなことに某サイトのURLに規則性があったので、アーティスト名からなるURLを生成し、そのURLをWebスクレイピングして楽曲のリストを集め、今回のBillboardのランキングに入った楽曲のみに絞ります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
#アーティストの楽曲一覧の取得 import urllib from bs4 import BeautifulSoup from urllib.request import urlopen import requests from urllib.error import HTTPError, URLError import csv, re, time from requests.exceptions import ConnectionError f = open('artist_url_list.csv', 'r') dataReader = csv.reader(f) #結果の出力用のデータフレームを作る。 data01 =[] #URL data02 =[] #曲名 data03 =[] #link for row in dataReader: for url in row: time.sleep(10.0) #sleep(秒指定) try: r = requests.get(url) soup = BeautifulSoup(r.content, 'html.parser') for body in soup.findAll("td",{'class':'colfirst'}): for link in body.findAll("a"): data01.append(url) data02.append(''.join(link.findAll(text=True))) data03.append(link.get("href")) data = zip(data01,data02,data03) #CSV出力 with open('artistpage_result.csv','wt',errors='backslashreplace') as fout: writecsv = csv.writer(fout,lineterminator='\n') writecsv.writerows(data) except HTTPError as e: print(e.code) except URLError: print("URLError") |
楽曲をランキングに含まれるもののみに絞ったら、歌詞詳細ページを取得します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
#歌詞詳細の歌詞該当部分のみ抽出 import urllib from bs4 import BeautifulSoup from urllib.request import urlopen import requests from urllib.error import HTTPError, URLError import csv, re, time from requests.exceptions import ConnectionError f = open('song_detail_url.csv', 'r') dataReader = csv.reader(f) #結果の出力用のデータフレームを作る。 data01 =[] #URL data02 =[] #歌詞 for row in dataReader: for url in row: time.sleep(10.0) #sleep(秒指定) try: r = requests.get(url) soup = BeautifulSoup(r.content, 'html.parser') for body in soup.findAll("div",{'id':'content_h'}): data01.append(url) data02.append(''.join(body.findAll(text=True))) data = zip(data01,data02) #CSV出力 with open('lyrics_result.csv','wt',errors='backslashreplace') as fout: writecsv = csv.writer(fout,lineterminator='\n') writecsv.writerows(data) except HTTPError as e: print(e.code) except URLError: print("URLError") |
うまいこと歌詞情報を手に入れることができました。ざっと947曲です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
url lyrics 0 http://www.lyricsfreak.com/e/eminem/love+the+w... Just gonna stand there and watch me burnBut th... 1 http://www.lyricsfreak.com/t/taio+cruz/dynamit... I came to dance-dance-dance-dance (Yeah)I hate... 2 http://www.lyricsfreak.com/t/taylor+swift/mine... Oh, oh, ohOh, oh, ohYou were in college, worki... 3 http://www.lyricsfreak.com/e/enrique+iglesias/... One life, one loveEnrique Iglesias, PitbullY'a... 4 http://www.lyricsfreak.com/b/bob/airplanes_208... Can we pretend that airplanesIn the night sky ... 5 http://www.lyricsfreak.com/m/mike+posner/coole... If I could write you a song,And make you fall ... 6 http://www.lyricsfreak.com/j/jason+derulo/ridi... Yea yeah, yeah, yeah, yeah,I'm feeling like a ... 7 http://www.lyricsfreak.com/t/travie+mccoy/bill... I wanna be a billionaire so freakin' badBuy al... 8 http://www.lyricsfreak.com/d/drake/find+your+l... I'm more than just an option (hey, hey, hey) R... 9 http://www.lyricsfreak.com/u/usher/omg_2087748... Oh my goshBaby let meDid it again, so Imma let... 10 http://www.lyricsfreak.com/b/bob/magic_2087969... I got the magic in meEvery time I touch that t... 11 http://www.lyricsfreak.com/n/nicki+minaj/your+... [Chorus]Shawty I'm a only tell you this once, ... 12 http://www.lyricsfreak.com/m/maroon+5/misery_2... Oh yeahOh yeahSo scared of breaking itThat you... 13 http://www.lyricsfreak.com/t/train/hey+soul+si... Hey, hey, heyYour lipstick stains on the front... 14 http://www.lyricsfreak.com/b/bruno+mars/just+t... Oh her eyes, her eyesMake the stars look like ... 15 http://www.lyricsfreak.com/l/lady+gaga/alejand... I know that we are young,And I know that you m... 16 http://www.lyricsfreak.com/l/la+roux/bulletpro... Been there, done that, messed aroundI'm having... 17 http://www.lyricsfreak.com/f/flo+rida/club+can... You know I know howTo make 'em stop and stare ... 18 http://www.lyricsfreak.com/s/shontelle/impossi... I remember years agoSomeone told me I should t... 19 http://www.lyricsfreak.com/p/paramore/the+only... When I was youngerI saw my daddy cryAnd curse ... 20 http://www.lyricsfreak.com/u/usher/there+goes+... Yeah, Right,Usher baby, OKYeah man, rightThere... |
Rによる分析
ここから、Rにてテキストマイニングを行いたいと思います。まず、tmパッケージを用いて、不要語(stop word)を除去します。具体的にはtheとかyouとかを除外しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#歌詞データの読み込み lyrics_dataset <- read.csv(file = "lyrics_result.csv",as.is = TRUE,header = FALSE) colnames(lyrics_dataset) <- c("link","lyrics") library(tm) #歌詞を小文字にする document_dataset$lyrics <- tolower(document_dataset$lyrics) #stop wordを除去する stopwords_regex = paste(stopwords('en'), collapse = '\\b|\\b') stopwords_regex = paste0('\\b', stopwords_regex, '\\b') document_dataset$lyrics <- stringr::str_replace_all(document_dataset$lyrics, stopwords_regex, '') |
続いて、LDAを実行できるtopicmodelsパッケージで扱えるようにするために、テキストデータに以下の処理を施します。
|
1 2 3 4 5 6 |
#文書単語行列の作成 corpus <- Corpus(VectorSource(document_dataset$lyrics)) inspect(corpus) dtm <- DocumentTermMatrix(corpus) findFreqTerms(dtm) |
あとは以下のコードでLDAを実行するだけです。トピック数はアドホックに20としています。研究者の方、いい加減ですみません。
|
1 2 3 4 5 6 |
#LDAの実行 library(topicmodels) nbo_topics <- 20 lda <- LDA(dtm,control=list(verbose=1), k = nbo_topics,method = "Gibbs") |
LDAの結果
まずは推定されたトピックごとの上位10単語をみてみます。トピック1はラブソングとかでしょうか。トピック17にパリピっぽい単語が、トピック18にスラングが含まれていますね。
|
1 2 |
#トピックの上位10単語を確認する terms_each_topics <- data.frame(terms(lda,10)) |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
> terms_each_topics Topic.1 Topic.2 Topic.3 Topic.4 Topic.5 Topic.6 Topic.7 Topic.8 Topic.9 Topic.10 Topic.11 Topic.12 Topic.13 Topic.14 Topic.15 Topic.16 Topic.17 Topic.18 Topic.19 Topic.20 1 love know feel better wanna hey one chorus back yeah gonna never like got ’m keep stop ain let get 2 like now heart world want said ooh way time baby low will new like don’t even just like can good 3 make just life whoa take old call verse know girl hear still city back ’re getting hands shit say night 4 touch need away run rock every cause can come little mean ever high right young one put fuck believe ain 5 know think just light see woo gettin pre long like sound eyes bout wish ’s give party got fly kind 6 nobody cause break things kiss left born tell like just shaky always ride hold ’ll lose crazy hook fall really 7 baby much real find come told day got best right just everything yeah boom que please live gon made sleep 8 cause give enough show make nothing makes like home get solo leave fun know ain’t youand lights nigga first champion 9 name mind every see body daddy came used til can tonight hope know one para just play niggas words catch 10 loving really find waiting tonight sweet stand made alright look wicked stay get come can’t without see money lonely til |
見ずらいので、行を一つにまとめて、トピックにidを割り振ります。
|
1 2 3 |
#トピックの上位10単語をまとめて、トピックにidをふる topic_keywords <- data.frame(topic_keywords_10=apply(t(terms_each_topics),1,paste,collapse=",")) topic_keywords <- topic_keywords %>% mutate(topic_id=1:n()) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
> topic_keywords topic_keywords_10 topic_id 1 love,like,make,touch,know,nobody,baby,cause,name,loving 1 2 know,now,just,need,think,cause,much,give,mind,really 2 3 feel,heart,life,away,just,break,real,enough,every,find 3 4 better,world,whoa,run,light,things,find,show,see,waiting 4 5 wanna,want,take,rock,see,kiss,come,make,body,tonight 5 6 hey,said,old,every,woo,left,told,nothing,daddy,sweet 6 7 one,ooh,call,cause,gettin,born,day,makes,came,stand 7 8 chorus,way,verse,can,pre,tell,got,like,used,made 8 9 back,time,know,come,long,like,best,home,til,alright 9 10 yeah,baby,girl,little,like,just,right,get,can,look 10 11 gonna,low,hear,mean,sound,shaky,just,solo,tonight,wicked 11 12 never,will,still,ever,eyes,always,everything,leave,hope,stay 12 13 like,new,city,high,bout,ride,yeah,fun,know,get 13 14 got,like,back,right,wish,hold,boom,know,one,come 14 15 ’m,don’t,’re,young,’s,’ll,que,ain’t,para,can’t 15 16 keep,even,getting,one,give,lose,please,youand,just,without 16 17 stop,just,hands,put,party,crazy,live,lights,play,see 17 18 ain,like,shit,fuck,got,hook,gon,nigga,niggas,money 18 19 let,can,say,believe,fly,fall,made,first,words,lonely 19 20 get,good,night,ain,kind,really,sleep,champion,catch,til 20 |
最後に、BillboardでTop10に入ったかどうかのデータを作っておき、そのデータと各歌詞を繋ぎ、各歌詞ごとに割りふられた確率が最大のトピックで集計をします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
#上位10位に入ったことがあるかどうかのダミーを作成 top_10_songs <- merge_dataset %>% group_by(link.y) %>% summarise(top_10=sum(top_10)) top_10_songs <- top_10_songs %>% mutate(top_10_dummy=ifelse(top_10>0,1,0)) #割り振られた最大の確率のトピックを抽出し、歌詞データと統合する topics_each_document <- data.frame(topic_id=topics(lda,1)) topics_each_document <- cbind(link.y=document_dataset$link.y,topics_each_document) #上位10位ダミーを繋ぎ、トピックの上位10単語の表現も繋ぐ topics_each_document <- topics_each_document %>% left_join(top_10_songs,by="link.y") topics_each_document <- topics_each_document %>% left_join(topic_keywords,by="topic_id") #トピックごとのBillboardのTop10ランクイン割合をもとめる topics_each_document %>% group_by(topic_keywords_10) %>% summarise(top_10_dummy=mean(top_10_dummy),count=n()) # A tibble: 20 × 3 topic_keywords_10 `mean(top_10_dummy)` count <fctr> <dbl> <int> 1 ’m,don’t,’re,young,’s,’ll,que,ain’t,para,can’t 0.12195122 41 2 ain,like,shit,fuck,got,hook,gon,nigga,niggas,money 0.14705882 68 3 back,time,know,come,long,like,best,home,til,alright 0.21666667 60 4 better,world,whoa,run,light,things,find,show,see,waiting 0.25000000 40 5 chorus,way,verse,can,pre,tell,got,like,used,made 0.14814815 54 6 feel,heart,life,away,just,break,real,enough,every,find 0.10416667 48 7 get,good,night,ain,kind,really,sleep,champion,catch,til 0.22857143 35 8 gonna,low,hear,mean,sound,shaky,just,solo,tonight,wicked 0.22857143 35 9 got,like,back,right,wish,hold,boom,know,one,come 0.13888889 36 10 hey,said,old,every,woo,left,told,nothing,daddy,sweet 0.09756098 41 11 keep,even,getting,one,give,lose,please,youand,just,without 0.18918919 37 12 know,now,just,need,think,cause,much,give,mind,really 0.21333333 75 13 let,can,say,believe,fly,fall,made,first,words,lonely 0.15217391 46 14 like,new,city,high,bout,ride,yeah,fun,know,get 0.14705882 34 15 love,like,make,touch,know,nobody,baby,cause,name,loving 0.17021277 47 16 never,will,still,ever,eyes,always,everything,leave,hope,stay 0.22222222 72 17 one,ooh,call,cause,gettin,born,day,makes,came,stand 0.28205128 39 18 stop,just,hands,put,party,crazy,live,lights,play,see 0.25000000 48 19 wanna,want,take,rock,see,kiss,come,make,body,tonight 0.10810811 37 20 yeah,baby,girl,little,like,just,right,get,can,look 0.14814815 54 |
|
1 2 3 4 5 |
#トピックごとのランクイン割合を高い順に棒グラフで描写 library(ggplot2) ggplot(topics_and_top10, aes(x=reorder(topic_keywords_10,top_10_dummy), y=top_10_dummy)) + geom_bar(stat='identity') + coord_flip() + xlab("topics") |
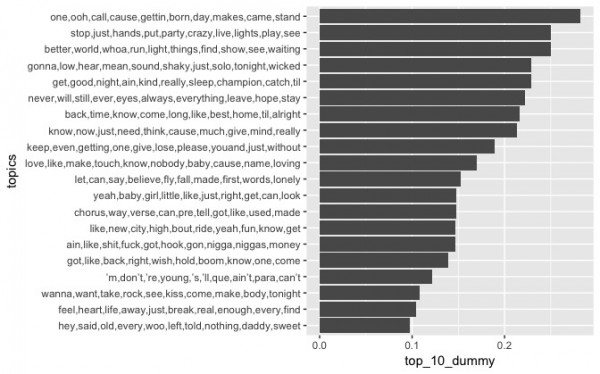
BillboardのTop10ランクイン割合の高いトピックTop3
「one,ooh,call,cause,gettin,born,day,makes,came,stand」
「better,world,whoa,run,light,things,find,show,see,waiting」・・・明るい感じ?
「stop,just,hands,put,party,crazy,live,lights,play,see」・・・パリピぽい
BillboardのTop10ランクイン割合の低いトピックTop3
「wanna,want,take,rock,see,kiss,come,make,body,tonight」・・・欲求系?
「feel,heart,life,away,just,break,real,enough,every,find」・・・癒し系?
「hey,said,old,every,woo,left,told,nothing,daddy,sweet」
あまり洋楽を聴かないので、得られたトピックの解釈が中々できないのがもどかしいです。ただ、スラングの歌詞を含む歌詞はそんなにランクイン割合が悪いわけではなさそうですね。洋楽をもっと聴いて、前処理などもう少し工夫してリベンジしたいですね。
参考文献
トピックモデルによる統計的潜在意味解析 (自然言語処理シリーズ)
Pythonクローリング&スクレイピング -データ収集・解析のための実践開発ガイド-
モダンなRによるテキスト解析topicmodels: An R Package for Fitting Topic Models