はじめに
知人より、洋楽の流行りに疎いのでキャッチアップしたいという要望があり、某洋楽ヒットチャートの週次ランキングとTop100のデータを大量に集めてみようと思うに至りました。今回は深い考察を行うには至っていませんが、簡単にRにて集計・可視化を行います。
データ収集
Webスクレイピング対象の某洋楽ヒットチャートの週次ランキングは今週の順位・先週の順位・アーティスト名・曲名・詳細ページへのリンクなどが載せられおり、毎週土曜日更新されています。サイト内から導線はありませんが、URLのパラメータに法則があるため、うまく収集できます。今回は2010年8月〜2017年6月の約7年分のデータを集めます。
URLのリストをCSVで読み込み、BeautifulSoupでタグを指定して抽出します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
#ライブラリの読み込み import urllib from bs4 import BeautifulSoup from urllib.request import urlopen import requests from urllib.error import HTTPError import csv, time #URLのリストを読み込む f = open('url_list.csv', 'r') dataReader = csv.reader(f) #結果の出力用のリストを作る data01 =[] #URL data02 =[] #順位 data03 =[] #title&artist data04 =[] #link data05 =[] #artist for row in dataReader: for url in row: time.sleep(10.0) #sleep(秒指定) try: r = requests.get(url) soup = BeautifulSoup(r.content, 'html.parser') for body in soup.findAll("tbody"): for detail in body.findAll("tr"): for ranking in detail.findAll("td",{'class':'rank_td'}): for content in detail.findAll("div",{'class':'name_detail'}): for artist_name in content.findAll("span"): for link in artist_name.findAll("a"): data01.append(url) data02.append(''.join(ranking.findAll(text=True))) data03.append(''.join(content.findAll(text=True))) data04.append(link.get("href")) data05.append(''.join(artist_name.findAll(text=True))) data = zip(data01,data02,data03,data04,data05) #CSV出力 with open('result.csv','wt',errors='backslashreplace') as fout: writecsv = csv.writer(fout,lineterminator='\n') writecsv.writerows(data) except HTTPError as e: print(e.code) |
データ取得後は簡単にpandasのstr.replaceで整形すると、以下のような結果になります。今週の順位と先週の順位が引っ付いてしまっています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#Webスクレイピングしたデータをpandasで整形 import pandas as pd #データ読み込み data_list = pd.read_csv("result.csv", header = None, delimiter=",", encoding='utf-8') data_list.columns = ['url', 'ranking','title&artist','link','artist'] #文字列の置換 data_list['url'] = data_list['url'].str.replace('置換前','置換後') data_list['title&artist'] = data_list['title&artist'].str.replace('置換前','置換後') data_list['ranking'] = data_list['ranking'].str.replace('置換前','置換後') #CSVに保存 data_list.to_csv("dataset.csv",index=False) |
ここから横着してRで整形し、各週の順位データを作成しました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#引っ付いたランキングに関するデータを分離して、データテーブルに加える。 dataset <- strsplit(ranking_dataset$ranking, "from") rankings <- data.frame(current_ranking=as.integer(), previous_ranking=as.integer()) for( i in 1:nrow(ranking_dataset)){ rankings[i,1] <- as.integer(dataset[[i]][1]) rankings[i,2] <- as.integer(dataset[[i]][2]) } ranking_dataset <- cbind(ranking_dataset,rankings) ranking_dataset <- ranking_dataset %>% select(url,current_ranking,previous_ranking,title.artist,artist,link) colnames(ranking_dataset) <- c("date","current_ranking","previous_ranking","title", "artist","link") |
データ確認
データ構造はこのような形です。
|
1 2 3 4 5 6 7 8 9 |
#データ構造を確認する > str(ranking_dataset) 'data.frame': 22254 obs. of 6 variables: $ date : chr "2010/08/21" "2010/08/21" "2010/08/21" "2010/08/21" ... $ current_ranking : int 1 2 3 4 5 6 7 8 10 11 ... $ previous_ranking: int 1 3 NA 2 5 4 6 9 11 8 ... $ title : chr "Love The Way You Lie" "Dynamite" "Mine" "California Gurls" ... $ artist : chr "Eminem Featuring Rihanna" "Taio Cruz" "Taylor Swift" "Katy Perry Featuring Snoop Dogg" ... $ link : chr "/artists/detail/306903" "/artists/detail/464754" "/artists/detail/319433" "/artists/detail/450934" ... |
まず、どんな楽曲やアーティストがランキングに入っているのかを簡単に確認してみます。 ほとんど聞いたことない人の名前、曲名ですが。。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
#楽曲ごとのランクイン回数の上位20人 > ranking_dataset %>% count(title) %>% arrange(desc(n)) %>% print(n=20) # A tibble: 1,785 × 2 title n <chr> <int> 1 Radioactive 91 2 Sail 78 3 Party Rock Anthem 68 4 Counting Stars 67 5 Animals 66 6 Rolling In The Deep 65 7 Ho Hey 62 8 Sorry 62 9 Somebody That I Used To Know 61 10 Demons 60 11 All Of Me 58 12 Lights 57 13 Dark Horse Featuring Juicy J 56 14 Some Nights 56 15 Stay With Me 55 16 Hello 54 17 Can't Stop The Feeling! 52 18 Cheap Thrills Featuring 52 19 Don't Let Me Down 52 20 Pompeii 52 # ... with 1,765 more rows |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
#アーティストごとのランクイン回数の上位20位 > ranking_dataset %>% count(artist) %>% arrange(desc(n)) %>% print(n=20) # A tibble: 876 × 2 artist n <chr> <int> 1 Drake 350 2 Bruno Mars 325 3 Rihanna 301 4 Taylor Swift 299 5 Adele 294 6 Imagine Dragons 258 7 One Direction 254 8 Katy Perry 237 9 Justin Bieber 204 10 Chris Brown 195 11 Carrie Underwood 192 12 Lady Antebellum 184 13 Nicki Minaj 183 14 OneRepublic 183 15 Ellie Goulding 182 16 Maroon 5 182 17 The Weeknd 182 18 Ed Sheeran 169 19 Blake Shelton 167 20 Beyonce 152 # ... with 856 more rows |
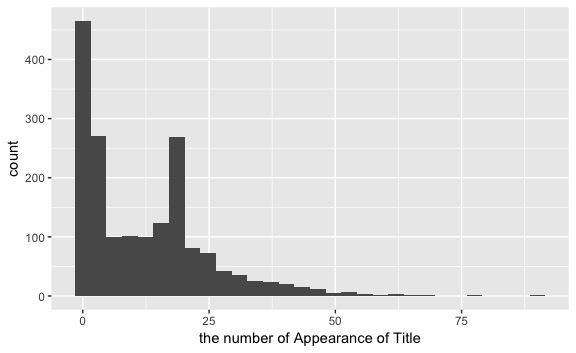
続いて、2010年8月〜2017年6月の間に100位以内に入った数を楽曲ごとにヒストグラムにしてみます。べき乗分布な形かと思いきや、20回前後で盛り上がっているのが気になりますね。
|
1 2 3 |
#タイトルごとのランクイン回数の集計値をヒストグラムに示す title_ranking <- ranking_dataset %>% count(title) %>% arrange(desc(n)) ggplot(data = title_ranking,aes(x = n)) + geom_histogram() + xlab("the number of Appearance of Title") |
|
1 2 3 4 |
#楽曲のランクイン回数のサマリー > summary(title_ranking$n) Min. 1st Qu. Median Mean 3rd Qu. Max. 1.00 1.00 9.00 12.47 20.00 91.00 |
中央値が9週間なので、意外と長い期間Top100には入っています。
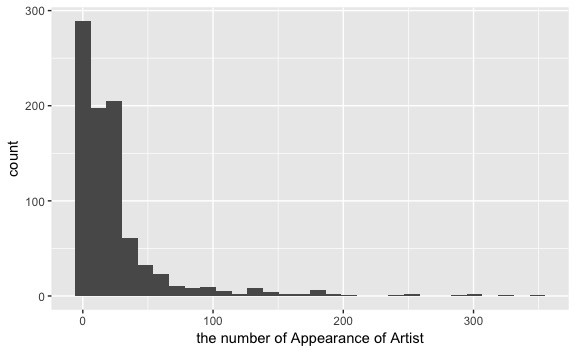
続いて、100位以内に入った数をアーティストごとにヒストグラムにしてみます。こちらはべき乗分布のような形になっています。
|
1 2 3 |
#アーティストごとのランクイン回数の集計値をヒストグラムに示す artist_ranking <- ranking_dataset %>% count(artist) %>% arrange(desc(n)) ggplot(data = artist_ranking,aes(x = n)) + geom_histogram() + xlab("the number of Appearance of Artist") |
Top10入りの楽曲の実態
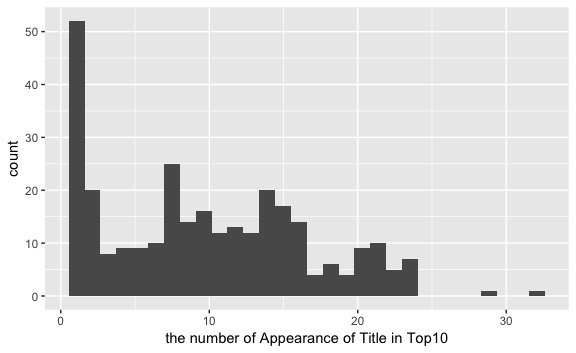
Top10に入っている楽曲のみに絞って、ヒストグラムを描いてみます。
|
1 2 3 |
#Top10入りのデータに絞ってヒストグラムを描く top_10 <- ranking_dataset %>% filter(current_ranking<=10) %>% count(title) %>% arrange(desc(n)) ggplot(data = top_10,aes(x = n)) + geom_histogram() + xlab("the number of Appearance of Title in Top10") |
|
1 2 3 4 |
#Top10に入っている楽曲の10位以内ランクイン回数サマリー > summary(top_10$n) Min. 1st Qu. Median Mean 3rd Qu. Max. 1.000 3.000 10.000 9.779 15.000 32.000 |
Top10に入ったら、10週近くは10位以内に含まれるようです。上位はすぐに取って代わられるのかと思いきや、人気が人気を呼ぶとかなのでしょうか。確か、某ECサイトの方が、生キャラメルは売れるから売れたんだとか言っていた気がします。
順位の推移
100位以内にランクインした回数が最も多かった楽曲のTop10に関して、時系列プロットをしてみます。
|
1 2 3 4 5 6 7 8 9 |
#100位内ランクイン回数が上位の10曲に関して時系列プロットを行う。 title_ranking_top10 <- title_ranking[1:10,] title_ranking_top10 <- ranking_dataset %>% filter(title %in% title_ranking_top10$title) title_ranking_top10$date <- as.Date(title_ranking_top10$date) ggplot(data = title_ranking_top10,aes(x = date, y = current_ranking, colour=title)) + geom_line() + ylab("current ranking") + ggtitle("Time Series Plot of Top10") |
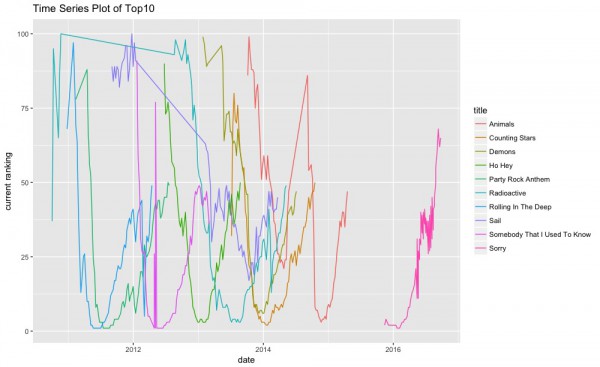
初回に上位にランクインして、後は下がるだけの楽曲や、じわじわとランキングを上げていく楽曲などが観察されています。楽曲の消費のサイクルみたいなものがあるのでしょう。
今後について
せっかく面白そうなデータが手に入ったので、リンク先も辿って、どのような楽曲やアーティストの特徴が人気に繋がりうるのか見てみるのも良いですね。あと、もう少し洋楽聴いてみようと思います。私はクラシック音楽とジャズしかウォークマンに入っていないので。
参考文献