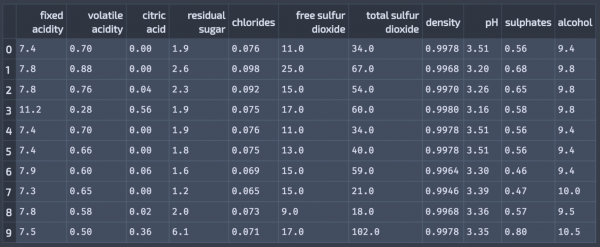
はじめに
もともとデータアナリストとして働いているのですが、最近、エンジニアと一緒に仕事をすることが増えたので、良いとされている教科書を読むなどしています。その中で、『新しいLinuxの教科書』がわかりやすく書かれていたので、今回はそこで出てきたコマンドたちを箇条書きにして忘備録としておきたいと思います。なのでいつもよりショボいです。
普段、Rをメインとして機械学習・クローリング目的でPythonを扱うものとしては、エンジニア寄りの知識が薄いなぁと課題に感じていたので、これを良い機会と思ってCLIへの耐性を付けていきたいと思います。
感想
分析業務において、仮想環境でCentOSやUbuntuを扱うことはあるのですが、分析環境を作った上で、クローリング業務・RPAシステムなどのスケジュール実行をするくらいで基礎からちゃんと勉強したわけではありませんでした。そのため、教科書には知らないコマンドもありました。
この本はLinuxを使って開発する際の作法(移植性大事、GUI使うな、十字キー使うな)から、歴史的なコマンドの変遷、シェルスクリプトを用いた作業の効率化、Gitなどのチーム開発ツールの紹介まで幅広く扱われていて十分な内容だと思いました。図による解説もあるので、普段R使っているような非エンジニアでも読めるはずです。これからエンジニアと一緒に分析業務をしていくデータアナリストの方には強くおすすめできる本だと思います。Rでの当たり前の機能が、Linuxのシェルで普通にあるんだと色々と学びがありました。
コマンドたち
date
現在の日時の表示
echo
文字列の表示
pwd
現在のディレクトリを確認
cd
カレントディレクトリの変更
ls
ディレクトリ内のファイルの表示、オプションでパターン指定も可能
mkdir
ディレクトリを作成する、pオプションで深い階層も一気に作れる
touch
ファイルを作成する
rm
ファイル・ディレクトリを削除する
rmdir
空のディレクトリを削除する
cat
ファイルを表示する
less
ファイル内容をスクロール表示する
cp
ファイル・ディレクトリをコピーする
mv
ファイル・ディレクトリを移動する
ln
ファイルにリンクを張る
find
ディレクトリツリーからファイルを探す
locate
ファイル名データベースからファイルを探す(高速)、何日か前のファイルを探すの適している。
which
コマンドのフルパスを表示する
alias
エイリアスの設定(わかりやすい別名を与える)
set
bashのオプションを切り替える
shopt
bashのオプションを切り替える(種類豊富)
PATH
コマンド検索パス
printenv
環境変数の表示
export
環境変数の設定
sudo
コマンドをスーパーユーザとして実行
ps
プロセスの表示(x, ux, ax, aux, auxww)
jobs
現在のジョブ一覧を表示
fg
ジョブをフォアグラウンドにする(入力受付状態にする)
bg
ジョブをバックグラウンドにする
kill
ジョブ・プロセスを終了させる
|
パイプライン(処理と処理をつなぐ)
R使いからするとRのdplyrでパイプ処理を知ったので、Linuxに普通にあるのを知れて新鮮な気分になった。
head
先頭の部分を表示
こちらもRでよく使うものですね。
du
指定したファイルやディレクトリの使用容量を表示する
wc
入力ファイルの行数・単語数・バイト数を数える
sort
行単位でテキストを並び替える
uniq
同じ内容の行を省く
cut
入力の一部を切り出して出力する(元データから特定の部分を抽出したい際など)
tr
入力の文字を置き換える・削除もできる(-d)
tail
ファイルも末尾部分を表示する
diff
二つのファイルの差分を表示する
grep
文字列を検索する
sed
テキストの編集を元ファイルを変更せずに行える
awk
テキストの検索や抽出・加工などの編集操作を行う(sedより高機能で、スクリプトは「パターン」と「アクション」からなる)
・列選択もできる
・CSVファイルからのスコア集計などもできる。
・あんちべさんの本『データ解析の実務プロセス入門』でも紹介されていた。
xargs
標準入力として引数のリストを与える(findやgrepとの組み合わせで使うことが多いらしい)
tar
ファイルをアーカイブファイルにまとめたり、アーカイブファイルから元のファイルを取り出したりする
gzip
ファイルを圧縮・展開する(一つのファイルしか圧縮できないのでtarとの併用を行う)
bzip2
gzipよりも高い圧縮率で圧縮を行うが、gzipよりも圧縮・展開に時間がかかる
zip
アーカイブと圧縮を同時に行う(多くのディストリビューションで標準インストールされていない。unzipも必要)
git
ファイル変更履歴を保存し管理するツール
・git init リポジトリを作成
・git add コミット対象として登録
・git commit コミットする
・git status ワークツリーの状態を表示
・git diff 差分を表示する
・git log 履歴を表示する
・git revert コミットを取り消す
・git branch ブランチの一覧表示、新しくブランチを作成
・git checkout ブランチを切り替える
・git merge 指定したブランチを現在のブランチにマージする
・git branch -d ブランチを削除する
・git push 変更の履歴を送る
・git clone リポジトリを複製する
・git remote add リポジトリパスに別名を設定する
・git fetch 他のリポジトリの変更を取り込む
yum
パッケージ管理(CentOS)
・yum install パッケージのインストール
・yum erase/remove パッケージのアンインストール、削除
・yum search パッケージの検索
・yum info パッケージの詳細情報を表示
apt
パッケージ管理(Ubuntu)
・sudo apt-get install パッケージのインストール
・sudo apt-get remove パッケージの削除
・sudo apt-get purge 設定ファイルも含めた完全削除
・apt-cache search パッケージを検索
ssh
リモートログインする
info
オンラインマニュアルを表示する(索引や階層構造を設定できるなどmanより充実)