以前の投稿で紹介したXGBoostのパラメータチューニング方法ですが、実際のデータセットに対して実行するためのプログラムを実践してみようと思います。プログラム自体はAnalytics_Vidhya/Articles/Parameter_Tuning_XGBoost_with_Example/XGBoost models.ipynbに載っているのですが、データセットがついていません。そこで、前回の投稿(不均衡なデータの分類問題について with Python)で赤ワインのデータセットを手に入れているので、こちらのデータセットを用います。誤植なのかところどころ、うまく回らなかったところがあったので、手直しをしています。
以下の工程に従って進みます。結構長いですが、辛抱強く実践してみて下さい。
・ライブラリの読み込み
・データの読み込み
・前処理
・学習用データとテスト用データの作成
・XGBoostの予測結果をもとに、AUCの数値を返すための関数の定義
・モデルの実行
・チューニング
ライブラリの読み込み
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import pandas as pd import numpy as np import xgboost as xgb from xgboost.sklearn import XGBClassifier from sklearn import cross_validation, metrics from sklearn.grid_search import GridSearchCV import matplotlib.pylab as plt %matplotlib inline from matplotlib.pylab import rcParams rcParams['figure.figsize'] = 12, 4 |
データの読み込み
|
1 2 |
#importing the red wine data wine_df = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv", sep=";") |
前処理
|
1 2 3 4 5 6 7 |
#ユニークIDを行ごとに割り当てる。 wine_df['ID'] = range(1, len(wine_df) + 1) #ワインの質に関するデータを0-1データに置換する。qualityが6よりも小さかったら0、それ以外は1とする。 Y = wine_df.quality.values wine_df.quality = np.asarray([1 if i>=6 else 0 for i in Y]) wine_df.head(10) |
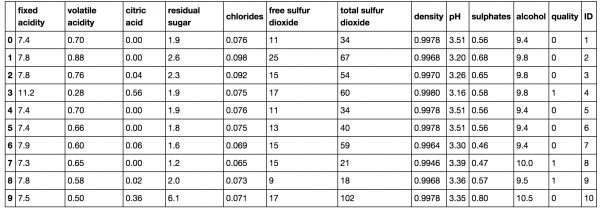
学習用データとテスト用データの作成
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
#学習用データとテスト用データの作成 msk = np.random.rand(len(wine_df)) < 0.8 #乱数を発生させて0.8よりも小さいデータを選ぶ train = wine_df[msk] test = wine_df[~msk] train.shape, test.shape ((1236, 13), (363, 13)) target='quality' IDcol = 'ID' #訓練データの目的変数の確認 train[target].value_counts() 1 659 0 577 Name: quality, dtype: int64 |
XGBoostの予測結果をもとに、AUCの数値を返すための関数の定義
XGBoostの予測結果から、AUCの数値を返し、特徴量に応じた重要度を出力するためのプログラムです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
#テスト結果を格納するデータフレームの生成 test_results = pd.DataFrame(data=test.ID) #関数の定義 def modelfit(alg, dtrain, dtest, predictors,useTrainCV=True, cv_folds=5, early_stopping_rounds=50): if useTrainCV: xgb_param = alg.get_xgb_params() xgtrain = xgb.DMatrix(dtrain[predictors].values, label=dtrain[target].values) xgtest = xgb.DMatrix(dtest[predictors].values) cvresult = xgb.cv(xgb_param, xgtrain, num_boost_round=alg.get_params()['n_estimators'], nfold=cv_folds, metrics=['auc'], early_stopping_rounds=early_stopping_rounds, show_progress=False) alg.set_params(n_estimators=cvresult.shape[0]) #Fit the algorithm on the data alg.fit(dtrain[predictors], dtrain[target],eval_metric=['auc']) #Predict training set: dtrain_predictions = alg.predict(dtrain[predictors]) dtrain_predprob = alg.predict_proba(dtrain[predictors])[:,1] #Print model report: print "\nModel Report" print "Accuracy : %.4g" % metrics.accuracy_score(dtrain[target].values, dtrain_predictions) print "AUC Score (Train): %f" % metrics.roc_auc_score(dtrain[target], dtrain_predprob) # Predict on testing data: dtest['predprob'] = alg.predict_proba(dtest[predictors])[:,1] #results = test_results.merge(dtest[['ID','predprob']], on='ID') print 'AUC Score (Test): %f' % metrics.roc_auc_score(dtest[target], dtest['predprob']) feat_imp = pd.Series(alg.booster().get_fscore()).sort_values(ascending=False) feat_imp.plot(kind='bar', title='Feature Importances') plt.ylabel('Feature Importance Score') |
モデルの実行
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
predictors = [x for x in train.columns if x not in [target, IDcol]] xgb1 = XGBClassifier( learning_rate =0.1, n_estimators=1000, max_depth=5, min_child_weight=1, gamma=0, subsample=0.8, colsample_bytree=0.8, objective= 'binary:logistic', nthread=4, scale_pos_weight=1, seed=27) modelfit(xgb1, train, test, predictors) Will train until cv error hasn't decreased in 50 rounds. Stopping. Best iteration: 237 Model Report Accuracy : 1 AUC Score (Train): 1.000000 AUC Score (Test): 0.875199 |
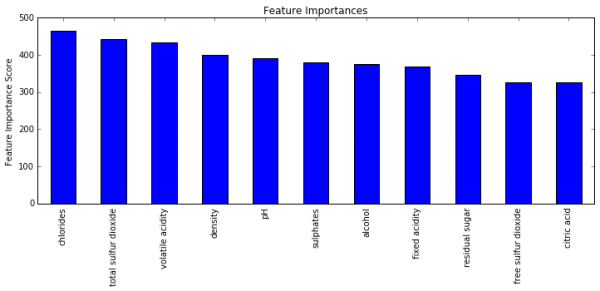
チューニング
max_depthとmin_child_weightの数値をチューニングするためのプログラムです。
|
1 2 3 4 5 6 7 8 9 10 11 |
#Grid seach on subsample and max_features #Choose all predictors except target & IDcols param_test1 = { 'max_depth':range(3,10,2), 'min_child_weight':range(1,6,2) } gsearch1 = GridSearchCV(estimator = XGBClassifier( learning_rate =0.1, n_estimators=1000, max_depth=5, min_child_weight=1, gamma=0, subsample=0.8, colsample_bytree=0.8, objective= 'binary:logistic', nthread=4, scale_pos_weight=1, seed=27), param_grid = param_test1, scoring='roc_auc',n_jobs=4,iid=False, cv=5) gsearch1.fit(train[predictors],train[target]) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
gsearch1.grid_scores_, gsearch1.best_params_, gsearch1.best_score_ ([mean: 0.76728, std: 0.03045, params: {'max_depth': 3, 'min_child_weight': 1}, mean: 0.76649, std: 0.03378, params: {'max_depth': 3, 'min_child_weight': 3}, mean: 0.76540, std: 0.03620, params: {'max_depth': 3, 'min_child_weight': 5}, mean: 0.76509, std: 0.03183, params: {'max_depth': 5, 'min_child_weight': 1}, mean: 0.76430, std: 0.02988, params: {'max_depth': 5, 'min_child_weight': 3}, mean: 0.76221, std: 0.03336, params: {'max_depth': 5, 'min_child_weight': 5}, mean: 0.77162, std: 0.03335, params: {'max_depth': 7, 'min_child_weight': 1}, mean: 0.76575, std: 0.03585, params: {'max_depth': 7, 'min_child_weight': 3}, mean: 0.76277, std: 0.03511, params: {'max_depth': 7, 'min_child_weight': 5}, mean: 0.77235, std: 0.03283, params: {'max_depth': 9, 'min_child_weight': 1}, mean: 0.76452, std: 0.03414, params: {'max_depth': 9, 'min_child_weight': 3}, mean: 0.76114, std: 0.03561, params: {'max_depth': 9, 'min_child_weight': 5}], {'max_depth': 9, 'min_child_weight': 1}, 0.77235073909956886) |
より細かい数値で再度最適なパラメータを探します。
|
1 2 3 4 5 6 7 8 9 10 11 |
#Grid seach on subsample and max_features #Choose all predictors except target & IDcols param_test2 = { 'max_depth':[4,5,6,7,8,9], 'min_child_weight':[1,2,3,4,5,6] } gsearch2 = GridSearchCV(estimator = XGBClassifier( learning_rate=0.1, n_estimators=1000, max_depth=5, min_child_weight=1, gamma=0, subsample=0.8, colsample_bytree=0.8, objective= 'binary:logistic', nthread=4, scale_pos_weight=1,seed=27), param_grid = param_test2, scoring='roc_auc',n_jobs=4,iid=False, cv=5) gsearch2.fit(train[predictors],train[target]) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
gsearch2.grid_scores_, gsearch2.best_params_, gsearch2.best_score_ ([mean: 0.76820, std: 0.03336, params: {'max_depth': 4, 'min_child_weight': 1}, mean: 0.76431, std: 0.02792, params: {'max_depth': 4, 'min_child_weight': 2}, mean: 0.76171, std: 0.03356, params: {'max_depth': 4, 'min_child_weight': 3}, mean: 0.76257, std: 0.03277, params: {'max_depth': 4, 'min_child_weight': 4}, mean: 0.76128, std: 0.03661, params: {'max_depth': 4, 'min_child_weight': 5}, mean: 0.75902, std: 0.03280, params: {'max_depth': 4, 'min_child_weight': 6}, mean: 0.76509, std: 0.03183, params: {'max_depth': 5, 'min_child_weight': 1}, mean: 0.76426, std: 0.02974, params: {'max_depth': 5, 'min_child_weight': 2}, mean: 0.76430, std: 0.02988, params: {'max_depth': 5, 'min_child_weight': 3}, mean: 0.76262, std: 0.02992, params: {'max_depth': 5, 'min_child_weight': 4}, mean: 0.76221, std: 0.03336, params: {'max_depth': 5, 'min_child_weight': 5}, mean: 0.76655, std: 0.03397, params: {'max_depth': 5, 'min_child_weight': 6}, mean: 0.77066, std: 0.02936, params: {'max_depth': 6, 'min_child_weight': 1}, mean: 0.76422, std: 0.03038, params: {'max_depth': 6, 'min_child_weight': 2}, mean: 0.76126, std: 0.03021, params: {'max_depth': 6, 'min_child_weight': 3}, mean: 0.76334, std: 0.03176, params: {'max_depth': 6, 'min_child_weight': 4}, mean: 0.76347, std: 0.03245, params: {'max_depth': 6, 'min_child_weight': 5}, mean: 0.76437, std: 0.03546, params: {'max_depth': 6, 'min_child_weight': 6}, mean: 0.77162, std: 0.03335, params: {'max_depth': 7, 'min_child_weight': 1}, mean: 0.76140, std: 0.03245, params: {'max_depth': 7, 'min_child_weight': 2}, mean: 0.76575, std: 0.03585, params: {'max_depth': 7, 'min_child_weight': 3}, mean: 0.76345, std: 0.03518, params: {'max_depth': 7, 'min_child_weight': 4}, mean: 0.76277, std: 0.03511, params: {'max_depth': 7, 'min_child_weight': 5}, mean: 0.75858, std: 0.03375, params: {'max_depth': 7, 'min_child_weight': 6}, mean: 0.77487, std: 0.03377, params: {'max_depth': 8, 'min_child_weight': 1}, mean: 0.76740, std: 0.03472, params: {'max_depth': 8, 'min_child_weight': 2}, mean: 0.76048, std: 0.03267, params: {'max_depth': 8, 'min_child_weight': 3}, mean: 0.76288, std: 0.03773, params: {'max_depth': 8, 'min_child_weight': 4}, mean: 0.76138, std: 0.03045, params: {'max_depth': 8, 'min_child_weight': 5}, mean: 0.76233, std: 0.03652, params: {'max_depth': 8, 'min_child_weight': 6}, mean: 0.77235, std: 0.03283, params: {'max_depth': 9, 'min_child_weight': 1}, mean: 0.76929, std: 0.03267, params: {'max_depth': 9, 'min_child_weight': 2}, mean: 0.76452, std: 0.03414, params: {'max_depth': 9, 'min_child_weight': 3}, mean: 0.76152, std: 0.03731, params: {'max_depth': 9, 'min_child_weight': 4}, mean: 0.76114, std: 0.03561, params: {'max_depth': 9, 'min_child_weight': 5}, mean: 0.76551, std: 0.03394, params: {'max_depth': 9, 'min_child_weight': 6}], {'max_depth': 8, 'min_child_weight': 1}, 0.77486987248915451) |
max_depthを8、min_child_weightを1として、他のパラメータチューニングに移ります。
続いて、gammaのチューニングを行います。
|
1 2 3 4 5 6 7 8 9 10 |
#Grid seach on subsample and max_features #Choose all predictors except target & IDcols param_test3 = { 'gamma':[i/10.0 for i in range(0,5)] } gsearch3 = GridSearchCV(estimator = XGBClassifier( learning_rate =0.1, n_estimators=1000, max_depth=8, min_child_weight=1, gamma=0, subsample=0.8, colsample_bytree=0.8, objective= 'binary:logistic', nthread=4, scale_pos_weight=1,seed=27), param_grid = param_test3, scoring='roc_auc',n_jobs=4,iid=False, cv=5) gsearch3.fit(train[predictors],train[target]) |
|
1 2 3 4 5 6 7 8 9 |
gsearch3.grid_scores_, gsearch3.best_params_, gsearch3.best_score_ ([mean: 0.77487, std: 0.03377, params: {'gamma': 0.0}, mean: 0.77689, std: 0.03298, params: {'gamma': 0.1}, mean: 0.77735, std: 0.03117, params: {'gamma': 0.2}, mean: 0.78163, std: 0.03076, params: {'gamma': 0.3}, mean: 0.78790, std: 0.03328, params: {'gamma': 0.4}], {'gamma': 0.4}, 0.78789976715320331) |
gammaを0.4と置きます。
ここで、いままでにチューニングしたパラメータを用いて再度推定を行います。先ほどの0.875よりも高くなっています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
predictors = [x for x in train.columns if x not in [target, IDcol]] xgb2 = XGBClassifier( learning_rate =0.1, n_estimators=1000, max_depth=8, min_child_weight=1, gamma=0.4, subsample=0.8, colsample_bytree=0.8, objective= 'binary:logistic', nthread=4, scale_pos_weight=1, seed=27) modelfit(xgb2, train, test, predictors) Will train until cv error hasn't decreased in 50 rounds. Stopping. Best iteration: 120 Model Report Accuracy : 1 AUC Score (Train): 1.000000 AUC Score (Test): 0.884028 |
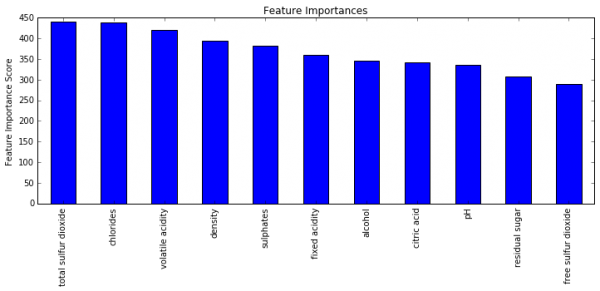
続いて、subsampleとcolsample_bytreeのチューニングを行います。
|
1 2 3 4 5 6 7 8 9 10 11 |
#Grid seach on subsample and max_features #Choose all predictors except target & IDcols param_test4 = { 'subsample':[i/10.0 for i in range(6,10)], 'colsample_bytree':[i/10.0 for i in range(6,10)] } gsearch4 = GridSearchCV(estimator = XGBClassifier( learning_rate =0.1, n_estimators=177, max_depth=8, min_child_weight=1, gamma=0.4, subsample=0.8, colsample_bytree=0.8, objective= 'binary:logistic', nthread=4, scale_pos_weight=1,seed=27), param_grid = param_test4, scoring='roc_auc',n_jobs=4,iid=False, cv=5) gsearch4.fit(train[predictors],train[target]) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
gsearch4.grid_scores_, gsearch4.best_params_, gsearch4.best_score_ ([mean: 0.78994, std: 0.02779, params: {'subsample': 0.6, 'colsample_bytree': 0.6}, mean: 0.78900, std: 0.03519, params: {'subsample': 0.7, 'colsample_bytree': 0.6}, mean: 0.78509, std: 0.03202, params: {'subsample': 0.8, 'colsample_bytree': 0.6}, mean: 0.78706, std: 0.02848, params: {'subsample': 0.9, 'colsample_bytree': 0.6}, mean: 0.78511, std: 0.03140, params: {'subsample': 0.6, 'colsample_bytree': 0.7}, mean: 0.78343, std: 0.03336, params: {'subsample': 0.7, 'colsample_bytree': 0.7}, mean: 0.78939, std: 0.03203, params: {'subsample': 0.8, 'colsample_bytree': 0.7}, mean: 0.78646, std: 0.04090, params: {'subsample': 0.9, 'colsample_bytree': 0.7}, mean: 0.77809, std: 0.03452, params: {'subsample': 0.6, 'colsample_bytree': 0.8}, mean: 0.78994, std: 0.03483, params: {'subsample': 0.7, 'colsample_bytree': 0.8}, mean: 0.79369, std: 0.03232, params: {'subsample': 0.8, 'colsample_bytree': 0.8}, mean: 0.79207, std: 0.03057, params: {'subsample': 0.9, 'colsample_bytree': 0.8}, mean: 0.78466, std: 0.02672, params: {'subsample': 0.6, 'colsample_bytree': 0.9}, mean: 0.78863, std: 0.03289, params: {'subsample': 0.7, 'colsample_bytree': 0.9}, mean: 0.78905, std: 0.02660, params: {'subsample': 0.8, 'colsample_bytree': 0.9}, mean: 0.78501, std: 0.03666, params: {'subsample': 0.9, 'colsample_bytree': 0.9}], {'colsample_bytree': 0.8, 'subsample': 0.8}, 0.79369231068019075) |
より細かい範囲で再度パラメータをチューニングします。
|
1 2 3 4 5 6 7 8 9 10 11 |
#Grid seach on subsample and max_features #Choose all predictors except target & IDcols param_test5 = { 'subsample':[i/100.0 for i in range(75,90,5)], 'colsample_bytree':[i/100.0 for i in range(75,90,5)] } gsearch5 = GridSearchCV(estimator = XGBClassifier( learning_rate =0.1, n_estimators=177, max_depth=8, min_child_weight=1, gamma=0.4, subsample=0.8, colsample_bytree=0.8, objective= 'binary:logistic', nthread=4, scale_pos_weight=1,seed=27), param_grid = param_test5, scoring='roc_auc',n_jobs=4,iid=False, cv=5) gsearch5.fit(train[predictors],train[target]) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
gsearch5.grid_scores_, gsearch5.best_params_, gsearch5.best_score_ ([mean: 0.78890, std: 0.03171, params: {'subsample': 0.75, 'colsample_bytree': 0.75}, mean: 0.79369, std: 0.03232, params: {'subsample': 0.8, 'colsample_bytree': 0.75}, mean: 0.79374, std: 0.03061, params: {'subsample': 0.85, 'colsample_bytree': 0.75}, mean: 0.78890, std: 0.03171, params: {'subsample': 0.75, 'colsample_bytree': 0.8}, mean: 0.79369, std: 0.03232, params: {'subsample': 0.8, 'colsample_bytree': 0.8}, mean: 0.79374, std: 0.03061, params: {'subsample': 0.85, 'colsample_bytree': 0.8}, mean: 0.78418, std: 0.03232, params: {'subsample': 0.75, 'colsample_bytree': 0.85}, mean: 0.78905, std: 0.02660, params: {'subsample': 0.8, 'colsample_bytree': 0.85}, mean: 0.78367, std: 0.03582, params: {'subsample': 0.85, 'colsample_bytree': 0.85}], {'colsample_bytree': 0.75, 'subsample': 0.85}, 0.79374219292158221) |
続いて、reg_alphaをチューニングします。
|
1 2 3 4 5 6 7 8 9 10 |
#Grid seach on subsample and max_features #Choose all predictors except target & IDcols param_test6 = { 'reg_alpha':[1e-5, 1e-2, 0.1, 1, 100] } gsearch6 = GridSearchCV(estimator = XGBClassifier( learning_rate =0.1, n_estimators=177, max_depth=8, min_child_weight=1, gamma=0.4, subsample=0.85, colsample_bytree=0.75, objective= 'binary:logistic', nthread=4, scale_pos_weight=1,seed=27), param_grid = param_test6, scoring='roc_auc',n_jobs=4,iid=False, cv=5) gsearch6.fit(train[predictors],train[target]) |
|
1 2 3 4 5 6 7 8 9 |
gsearch6.grid_scores_, gsearch6.best_params_, gsearch6.best_score_ ([mean: 0.79377, std: 0.03058, params: {'reg_alpha': 1e-05}, mean: 0.79068, std: 0.02953, params: {'reg_alpha': 0.01}, mean: 0.79298, std: 0.03268, params: {'reg_alpha': 0.1}, mean: 0.78731, std: 0.03270, params: {'reg_alpha': 1}, mean: 0.72370, std: 0.03333, params: {'reg_alpha': 100}], {'reg_alpha': 1e-05}, 0.79376831622356758) |
範囲が粗かったので、より細かくパラメータをチューニングします。
|
1 2 3 4 5 6 7 8 9 10 |
#Grid seach on subsample and max_features #Choose all predictors except target & IDcols param_test7 = { 'reg_alpha':[0, 0.001, 0.005, 0.01, 0.05] } gsearch7 = GridSearchCV(estimator = XGBClassifier( learning_rate =0.1, n_estimators=177, max_depth=8, min_child_weight=1, gamma=0.4, subsample=0.85, colsample_bytree=0.75, objective= 'binary:logistic', nthread=4, scale_pos_weight=1,seed=27), param_grid = param_test7, scoring='roc_auc',n_jobs=4,iid=False, cv=5) gsearch7.fit(train[predictors],train[target]) |
|
1 2 3 4 5 6 7 8 9 |
gsearch7.grid_scores_, gsearch7.best_params_, gsearch7.best_score_ ([mean: 0.79374, std: 0.03061, params: {'reg_alpha': 0}, mean: 0.79433, std: 0.03076, params: {'reg_alpha': 0.001}, mean: 0.79099, std: 0.02989, params: {'reg_alpha': 0.005}, mean: 0.79068, std: 0.02953, params: {'reg_alpha': 0.01}, mean: 0.79160, std: 0.02950, params: {'reg_alpha': 0.05}], {'reg_alpha': 0.001}, 0.79432567460197734) |
これまでにチューニングしてきたパラメータを用いて再度推定を行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
xgb3 = XGBClassifier( learning_rate =0.1, n_estimators=1000, max_depth=8, min_child_weight=1, gamma=0.4, subsample=0.85, colsample_bytree=0.75, reg_alpha=0.001, objective= 'binary:logistic', nthread=4, scale_pos_weight=1, seed=27) modelfit(xgb3, train, test, predictors) Will train until cv error hasn't decreased in 50 rounds. Stopping. Best iteration: 153 Model Report Accuracy : 1 AUC Score (Train): 1.000000 AUC Score (Test): 0.880331 |
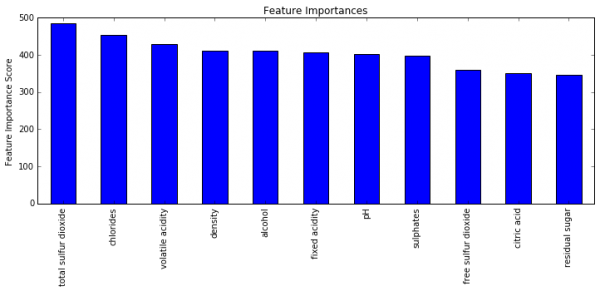
ブログであるように試行回数を1,000回から5,000回まで増やしてみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
xgb4 = XGBClassifier( learning_rate =0.01, n_estimators=5000, max_depth=8, min_child_weight=1, gamma=0.4, subsample=0.85, colsample_bytree=0.75, reg_alpha=0.001, objective= 'binary:logistic', nthread=4, scale_pos_weight=1, seed=27) modelfit(xgb4, train, test, predictors) Will train until cv error hasn't decreased in 50 rounds. Stopping. Best iteration: 604 Model Report Accuracy : 0.9951 AUC Score (Train): 0.999955 AUC Score (Test): 0.888000 |
88.8%まで向上しました。色々と数値いじっても、1%高めるだけにとどまってしまうのですね。
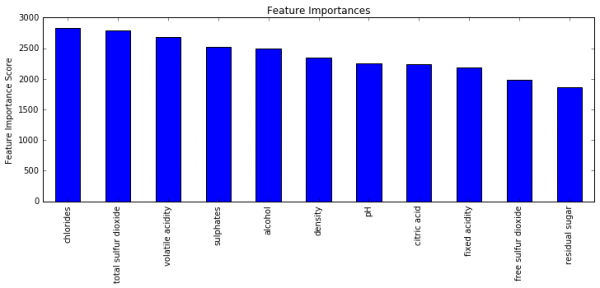
とにかく、XGBoostをPythonで実行してパラメータチューニングするという一連の試行がこのコードでできそうなので、今後も使いまわしてみようと思います。