『Python機械学習プログラミング』を読んで、scikit-learnのモジュールは充実しているなぁと感じたんですが、実際にWebサイトでUser Guide( http://scikit-learn.org/stable/user_guide.html )を見た所、この本に載り切らないような数多くの機械学習手法に応じたモジュールが用意されていました。そこで、世のデータサイエンティストはどのモジュールを良く使っているのだろうと気になったので、GitHubのSearchでヒットしたCodeの数を各モジュール単位で集計してみました。検索クエリは「scikit-learn + モジュール名」なので、正確なものではないのですが、相対的な利用頻度を見るぶんには使えるのではないかと思われます。
データ集計方法
・User Guideに登場するscikit-learnのモジュール名を集めています。
・教師付き学習か教師無し学習かどうかの判断は、User Guideで紹介されているモジュールかどうかで判断しています。
・GitHubのSearchで「scikit-learn + モジュール名」でヒットした件数をそのまま使っています。(2016年9月22日時点)
可視化コード
Jupyterで実行しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
%matplotlib inline import matplotlib.pyplot as plt import seaborn as sns import pandas as pd import pylab module_df = pd.read_csv("scikit_learn_modulelist.csv") pylab.figure(figsize=(5, 25)) sns.set_style("whitegrid") ax = sns.barplot(x="Hitscode", y="Module", data=module_df) |
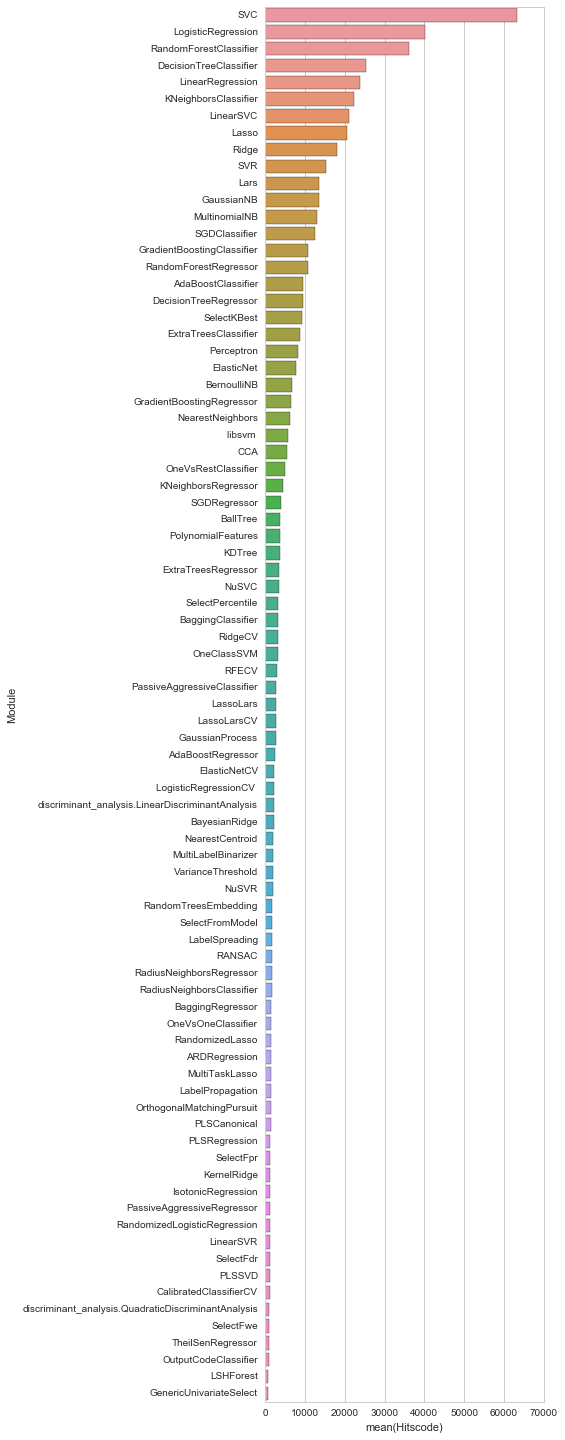
教師付き学習編
圧倒的に多いのがSVM(Support Vector Machine)を扱っているSVCモジュールで、続いて定番のロジスティック回帰やRandom Forestが使われているようです。統計解析ではメジャーなはずの線形回帰が5位なのは、初歩的なのであまりコードがアップされていないのかもしれません。GBDTのモジュールももう少し上位にくるかと思ったんですが15位でした。DMLCのXGBoostモジュールを使っているのかもしれませんね。私も実際のところXGBoostを使ってますし。
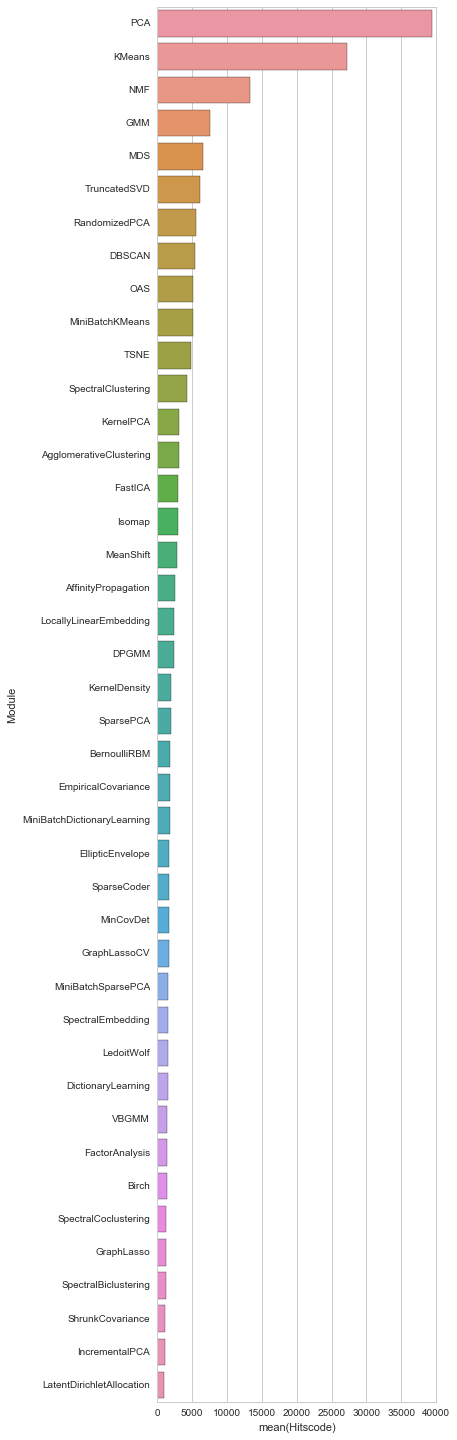
教師無し学習編
主成分分析やK-mean法など因子分解などのモジュールが上位を占めています。LDA(Latent Dirichlet Allocation)がもっと上位に来ると思ったんですが、思えばGensimの方が充実しているなぁと思うので、このランキングは妥当なのかもしれません。私もLDAなどはGensimを使っていますし。
収集を終えて
・社内だとデータサイエンティストの方がいないので、scikit-learnのモジュールの利用状況を知れてマニアックな共感をすることができた。
・SVMは実践例が豊富そうなので分析事例を探せば良い発見があるかもしれない。
・scikit-learnのUser Guideは充実していたので、時間を作って向き合ってみたいと思った。