はじめに
今回は、今後仕事で使いたいという思いもあり、RでUplift Modelingに関して便利なパッケージがないか探した結果、2019年に登場したばかりのtools4upliftの存在を知りました。アップリフトモデリングのモチベーションに関しても簡単に説明しながら、サンプルデータで実践してみようと思います。
・Uplift Modelingとはなにか
・Uplift Modelingの卑近な例え話
・Uplift Modelingのサンプルデータ
・tools4upliftについて
・tools4upliftでCriteoデータを試してみる
・『仕事ではじめる機械学習』の9章のコードをCriteoデータに試してみる
・おわりに
・参考文献
Uplift Modelingとはなにか
きちんとした説明は、あまりにも今更感があるので説明は端折りたいと思います。既出の文献がありますので、そちらを熟読ください。
Uplift Modelingの卑近な例え話
自分が吉野家のマーケティング担当だとしましょう。吉野家のアプリで割引クーポンを顧客にばらまくことができるとします。
マーケターとして重要なのは、割引クーポンを渡したことをきっかけとして吉野家に足を運び購入する顧客を増やせるかどうかになります。
マーケターの手元にあるのは、割引クーポンをばらまいた顧客とばらまかなかった顧客、そして吉野家で牛丼を食べたかどうかのデータです。
以前のマーケティング担当者がランダムにクーポンをばらまいていたことが重要なポイントです。
このデータから、顧客は以下の4分類に分かれます。
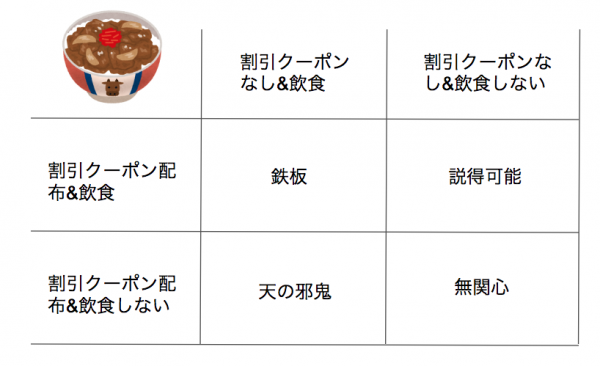
- 無関心:割引クーポンをばらまこうが我関せず。そもそも吉野家に行く気はない。
- 説得可能:普段、牛丼が安いすき屋にばかり行っているが、割高に感じている吉野家に負い目を感じている。割引クーポンで揺さぶられ来店する。
- 天の邪鬼:吉野家コピペのように、割引クーポンを握りしめた家族連れに遭遇したくないので、割引クーポンをばらまかれたら来店しないような客。
- 鉄板:毎日決まった時間に吉野家に行くことを心に決めている客。
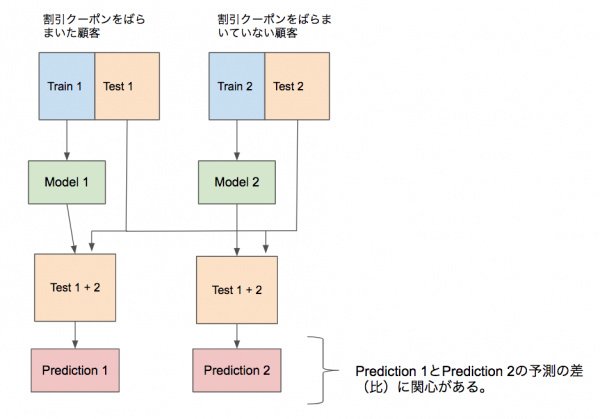
マーケターは割引クーポンをばらまいた顧客と割引クーポンをばらまいていない顧客にデータを二分し、それぞれ機械学習のための訓練用データとテスト用データを用意します。
つまり、「割引クーポンをばらまいた顧客」の訓練用データとテスト用データと「割引クーポンをばらまいていない顧客」の訓練用データとテスト用データの計4つのデータセットを用意します。
まず、牛丼の購入の有無を教師とした訓練用データでロジスティック回帰モデルなどを推定します。
その結果、「割引クーポンをばらまいた顧客」から推定したモデルと、「割引クーポンをばらまいていない顧客」から推定したモデルが手元に残ります。
2つのテスト用データを1つにまとめて、先程推定したモデルを用いて、牛丼の購入確率を求めます。モデルは2つあるので、予測結果がテスト用データ1つに対して2つあることになります。
その予測結果の比(「割引クーポンをばらまいた顧客」モデルベースの予測値÷「割引クーポンをばらまいていない顧客」モデルベースの予測値)をアップリフトとみなします。
以下の図はこれまでの説明を図にしたものです。
アップリフトがどの程度の水準であれば、説得可能なユーザーが多いのかを探っていくことで、吉野家のアプリにおいて、どのユーザーに割引クーポンを発行するべきかがわかることになります。
Uplift Modelingのサンプルデータ
残念なことに吉野家のアプリのデータはありません。そこで今回は公開データを利用します。
以前より、The MineThatData E-Mail Analytics And Data Mining ChallengeのメールのデータがUplift Modelingで非常にしばしば取り上げられるデータでしたが、Twitterで他にデータないのかとぼやいたところ、2名の方にCriteo Uplift Prediction Datasetを紹介していただきました。
余談ですが、Criteo社と言えばディスプレイ広告のキング的な存在で、少し商品のリンクを踏んだだけであっという間に広告がレコメンドされますよね。自社で出稿用バナーを作っていましたが、CVRが高くなる良いクリエイティブを作ってきたのか、単にCriteo社のアルゴリズムが優秀なだけなのか非常に気になるところでしたね。
Criteo社が提供してくれている今回のデータは、2500万行に及ぶユーザーのデータで、プライバシー保護の観点から特徴量は復元できないような形式で提供されています。バイナリーのラベルとしては訪問やコンバージョンなどがあり、データ全体に占める処置群の割合は84.6%となっています。要は、吉野家で言う割引クーポンをばらまいた顧客が全体の84.6%に及ぶということです。
tools4upliftについて
2019年1月に公開されたRのUplift Modeling用のパッケージです。
- 特徴量における連続値をカテゴリ変数にする際に、最適な階級値を求めてくれる関数
- アップリフトモデリングの可視化する関数
- アップリフトモデリングにおける特徴量選択ができる関数
- アップリフトモデリングにおけるモデルのバリデーションを行う関数
などが提供されており、ちょいとRを触れるマーケターにとって、アップリフトモデリングにおける試行錯誤がかなりしやすくなる便利なパッケージだと思いました。
なお、このパッケージで扱っているモデルはロジスティック回帰になります。介入データをもとに推定したモデルの条件付き確率と非介入データをもとに推定したモデルの条件付き確率の差をアップリフトとして推定しています。
このパッケージの解説論文においては、アップリフトモデリングの評価指標としてQini曲線というものが提案されていました。Qini曲線はローレンツ曲線のようなもので、Qini曲線とランダムに割り当てた際のアップリフト量の差分の合計をQini係数と定義しています。
tools4upliftでCriteoデータを試してみる
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
library(tools4uplift) library(tidyverse) library(data.table) x = fread("gunzip -c criteo-uplift.csv.gz") head(x,5) # 1000万件でデータをサンプリング sampleNum <- sample(nrow(x),10000000) x_sub <- x[sampleNum,] x_sub <- x_sub %>% select(-exposure,-visit) summary(x_sub) # Baseline models --------------------------------------------------------- set.seed(123); split.data1 <- SplitUplift(data = x_sub, p = 0.7, group = c("treatment", "conversion")) train <- split.data1[[1]] valid <- split.data1[[2]] base.tm <- DualUplift(data = train, treat = "treatment", outcome = "conversion", predictors = colnames(train[,1:12])) # baseline model for control group base.tm[[1]] # baseline model for treatment group base.tm[[2]] # predict the uplift on the validation set base.tm.valid <- DualPredict(data = valid, treat = "treatment", outcome = "conversion", model = base.tm, nb.group = 5)[[1]] # evaluate the model performance base.tm.perf <- QiniTable(data = base.tm.valid, treat = "treatment", outcome = "conversion", prediction = "uplift_prediction", nb.group = 5) # Qini曲線の描画 QiniCurve(base.tm.perf, title = "") # アップリフト量の棒グラフの描画 QiniBarPlot(base.tm.perf, title = "") # Qini係数の算出 QiniArea(base.tm.perf) |
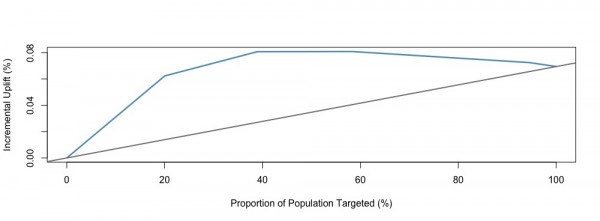
こちらはアップリフト値の予測値の上位から右に並べた際のアップリフトの増大のグラフになります。20%あたりでピークになるようです。
こちらはアップリフト量の棒グラフです。20%の階級値を超えたらガクンと下がるのがわかります。
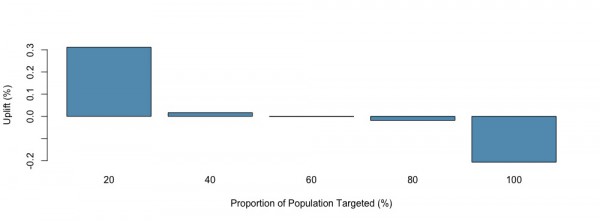
なお、Qini係数は0.03233551でした。
『仕事ではじめる機械学習』の9章のコードをCriteoデータに試してみる
tools4upliftの結果を鵜呑みにするのもあれなので、『仕事ではじめる機械学習』の9章のコードを使ってアップリフトモデリングを実践してみます。コードは丸パクリですが、謹んで掲載させていただきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 |
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt from operator import itemgetter plt.style.use("ggplot") from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression # https://ailab.criteo.com/criteo-uplift-prediction-dataset/ source_df = pd.read_csv("criteo-uplift.csv.gz") source_df.head(10) source_df.describe() feature_vector_df = source_df.drop(["treatment","conversion","visit","exposure"],axis=1) is_treat_list = list(source_df["treatment"] == 1) is_cv_list = list(source_df["conversion"] == 1) train_is_cv_list, test_is_cv_list, train_is_treat_list, \ test_is_treat_list, train_feature_vector_df,\ test_feature_vector_df = train_test_split(is_cv_list, is_treat_list, feature_vector_df, train_size=0.5, test_size=0.5, random_state=42) treat_model = LogisticRegression(C=0.01) control_model = LogisticRegression(C=0.01) train_sample_num = len(train_is_cv_list) treat_is_cv_list = [train_is_cv_list[i] for i in range(train_sample_num) if train_is_treat_list[i] == True] treat_feature_vector_list = train_feature_vector_df[train_is_treat_list] control_is_cv_list = [train_is_cv_list[i] for i in range(train_sample_num) if train_is_treat_list[i] == False] control_feature_vector_list = train_feature_vector_df[list(map(lambda a:a == False ,train_is_treat_list))] treat_model.fit(treat_feature_vector_list, treat_is_cv_list) control_model.fit(control_feature_vector_list, control_is_cv_list) treat_score = treat_model.predict_proba(test_feature_vector_df) control_score = control_model.predict_proba(test_feature_vector_df) score_list = treat_score[:,1] / control_score[:,1] result = list(zip(test_is_cv_list, test_is_treat_list, score_list)) result.sort(key=itemgetter(2),reverse=True) treat_uu = 0 control_uu = 0 treat_cv = 0 control_cv = 0 treat_cvr = 0.0 control_cvr = 0.0 lift = 0.0 stat_data = [] for is_cv, is_treat, score in result: if is_treat: treat_uu += 1 if is_cv: treat_cv += 1 treat_cvr = treat_cv / treat_uu else: control_uu += 1 if is_cv: control_cv += 1 control_cvr = control_cv / control_uu # コンバージョンレートの差に実験群の人数を掛けることでliftを算出 lift = (treat_cvr - control_cvr) * treat_uu stat_data.append([is_cv, is_treat, score, treat_uu, control_uu, treat_cv, control_cv, treat_cvr, control_cvr, lift]) qdf = pd.DataFrame(columns=('treat_cvr', 'control_cvr')) quantile_data = [] for n in range(10): start = int(n * len(result) / 10) end = int((n + 1) * len(result) / 10) - 1 quantiled_result = result[start:end] treat_uu = list(map(lambda item:item[1], quantiled_result)).count(True) control_uu = list(map(lambda item:item[1], quantiled_result)).count(False) treat_cv = [item[0] for item in quantiled_result if item[1] == True].count(True) control_cv = [item[0] for item in quantiled_result if item[1] == False].count(True) treat_cvr = treat_cv / treat_uu control_cvr = control_cv / control_uu quantile_data.append([treat_uu, control_uu, treat_cv, control_cv, treat_cvr, control_cvr]) label = "{}%~{}%".format(n*10, (n+1)*10) qdf.loc[label] = [treat_cvr, control_cvr] qdf.plot.bar() plt.xlabel("percentile") plt.ylabel("conversion rate") df = pd.DataFrame(stat_data) df.columns = ["is_cv", "is_treat", "score", "treat_uu", "control_uu", "treat_cv", "control_cv", "treat_cvr", "control_cvr", "lift"] # ベースラインを書き加える df["base_line"] = df.index * df["lift"][len(df.index) - 1] / len(df.index) df.plot(y=["treat_cv", "control_cv"]) plt.xlabel("uplift score rank") plt.ylabel("conversion count") df.plot(y=["treat_cvr", "control_cvr"], ylim=[0, 0.04]) plt.xlabel("uplift score rank") plt.ylabel("conversion rate") df.plot(y=["lift", "base_line"]) plt.xlabel("uplift score rank") plt.ylabel("lift count") df.plot(y=["treat_cv", "control_cv"], x="score", title="conversion count") df.plot(y=["treat_cvr", "control_cvr"], ylim=[0, 0.04], x="score", title="conversion rate") df.plot(y=["lift", "base_line"], x="score", title="lift") |
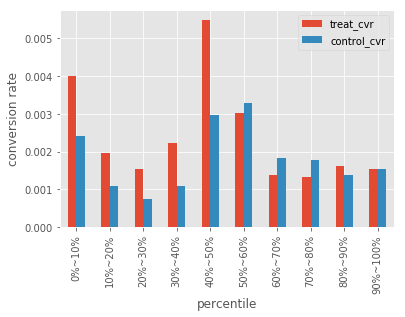
こちらの図はアップリフト値の階級値ごとのCVRです。最上位のアップリフト値はCVRの差が大きいですが、上位40~50%程度のアップリフト値のときにCVRの差が最も大きいようです。
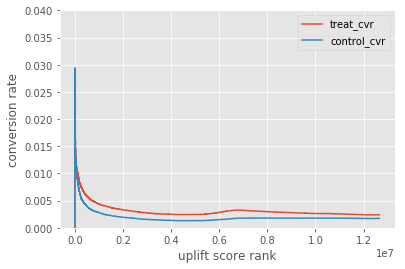
アップリフト値の順位とCVRの図です。順位が低くても処置群のほうがCVRがわずかに高いようです。
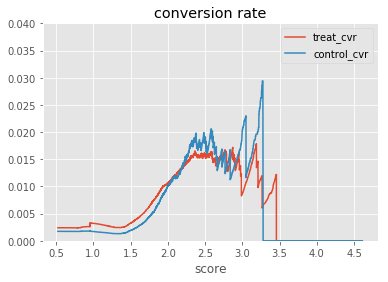
アップリフトのスコアとCVRの関係です。2未満であればCVRは処置群が上回っていますが、一様な傾向はなさそうです。
コンバージョンレートの差に対象群の人数を掛けることでliftを算出したものです。アップリフトスコアが1~2点であれば儲かるようです。
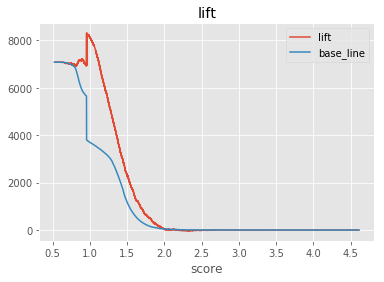
tools4upliftと出している指標が違うので比較ができないのが難点に思いました。tools4upliftはオートマチックな感じで便利なのですが、『仕事ではじめる機械学習』の9章を正義として進めたいので、どうにか揃えれるようにしていきたいと思います。
おわりに
tools4upliftというマーケターにとって銀の弾丸になりそうなパッケージの存在を知ることができ、実際に非常に便利そうな関数が用意されているのがわかりました。ただ、開発されたばかりのパッケージなのでそこまで結果を信じていません。『仕事ではじめる機械学習』本の結果と揃えたいなと思いました。その点がはっきりすれば業務で使ってみるのも良いですし、任意のマーケターに安心して共有できると思います。
参考文献
[1] 有賀康顕・中山心太・西林孝 (2018) 『仕事ではじめる機械学習』 オライリージャパン
[2] Mouloud Belbahri, Alejandro Murua, Olivier Gandouet, Vahid Partovi Nia (2019). “Uplift Regression: The R Package tools4uplift”, arXiv:1901.10867 [stat.AP]
[3] ohke (2019) 「Uplift modelingで施策が効く人を見極める」 け日記
[4] usaito (2018) 「Uplift Modelingで介入効果を最適化する」 Qiita