はじめに
最近、仕事で音声データを扱うことがあるのですが、アプローチの仕方を色々と調べています。
今のところ検討しているのが、
- クラウドAPIなどによる文字起こしによるテキストアナリティクス
- 音声の波形に関する分析
- 音声のピッチに関する分析
の3つですが、1つ目と2つ目については比較的すぐにググってチャレンジできましたし、ビジネス上で役に立ちそうな発見もありました。
そこで今回は3つ目の「音声のピッチ」(音程)について扱おうと思います。
ピッチがわかると何が嬉しいかというと、顧客対応などの音声でピッチがどのようなものであれば顧客満足度が高いのかを分析できるようになり、担当者へのフィードバックに使える可能性があります。
今までなんとなく蓄積していた音声データが宝の山になるかどうか、それをジャッジするための一つの手段と考えることができます。
後輩からの聞き込み
大学院で動画の圧縮について研究していた元後輩社員くんがいたので、きっと知っているはずだろうと思い、その方からピッチに関する研究を進める上でのキーワードを教えてもらいました。
彼曰く、F1やF0というキーワードで探していけばピッチの抽出ができるそうなので、早速調べて実践できないかチャレンジします。
F0とF1
Wikipediaで調べて結果を以下に記します。
- F0:基本周波数
信号を正弦波の合成で表したときの最も低い周波数成分の周波数を基本周波数と呼ぶ。 - F1:フォルマント周波数
フォルマント:言葉を発している人の音声スペクトルを観察すると分かる、時間的に移動している複数のピークのこと。
周波数の低い順に、第1フォルマント、第2フォルマントというように数字を当てて呼び、それぞれF1、F2とも表記する。
観察の仕方としては、縦軸に周波数、横軸に時間を置くものとする。
ピッチはどうすれば求めることができるのか?
断創録さんのブログによると、ピッチとは声の高さのことで、基本周波数やF0とも呼ばれているそうです。
そのため、今回はF0を求めれば目的を果たすことができそうです。
今回扱うモジュール/今回のツール
今回は、ピッチ検出を行うためのツール、REAPERのPythonラッパーであるpyreaperを使います。
|
1 |
pip install pyreaper |
一発で入るはずです。
続いて、音声ファイルをWAVファイルに変換するためのツールとして、FFmpegをインストールします。
Macだと、
|
1 |
brew install ffmpeg |
で一発で入るはずです。
使い方としては、
|
1 |
ffmpeg -i ファイル名.m4a -ar 16000 ファイル名.wav |
のようにターミナル上で使います。
データ
今回は、無料の音声素材でなにか無いかと探していたのですが、NHKの百人一首の読み上げデータにしました。
句に関してはこだわりはないので、適当に第5句にしています。
NHKの百人一首 第5句
奥山に紅葉踏み分け鳴く鹿の 声聞く時ぞ秋は悲しき/猿丸大夫
もう秋ですし、風情があって良いですね。
プログラム
実行プログラムはご丁寧にpyreaperのPyPIのページに良いものがありましたので、こちらをまるごと使います。
まず、百人一首の音声がm4a形式だったので、wav形式になるように、
先程インストールしたFFmpegを用いて、サンプルレート16000、チャネル数1のWAVファイルに変換します。
|
1 |
ffmpeg -i speech_example.m4a -ar 16000 -map_channel 0.0.0 speech_example.wav |
なお、電話などの話者が2名いるステレオのデータの場合、FFmpegを用いて左側成分、右側成分だけを抽出することができますので、分けて解析すると良いと思います。左右の分割に関してはFFmpegの参考文献で紹介されています。そうすれば、片方の話者の声だけを抽出することができますので、解析が捗ります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
%matplotlib inline import pysptk import pyreaper from scipy.io import wavfile from IPython.display import Audio file = "D0002110105_00000_A_001.wav" fs, x = wavfile.read(file) plot(x) Audio(x, rate=fs) #pyreaperモジュールを使ってピッチマークやF0や相関係数を計算する。 pm_times, pm, f0_times, f0, corr = pyreaper.reaper(x, fs) plot(pm_times, pm, linewidth=3, color="red", label="Pitch mark") legend(fontsize=15) plot(f0_times, f0, linewidth=3, color="green", label="F0 contour") legend(fontsize=15) plot(f0_times, corr, linewidth=3, color="blue", label="Correlations") legend(fontsize=15) |
実行結果
百人一首の音声の波形です。
ピッチマークです。ピッチマークとは、「単位波形を抽出する基準点」とされているとの説明があるのですが、あまり良くわかりません。無音のときに生成されていないので、ピッチ抽出の確信度という意味なんでしょうか。

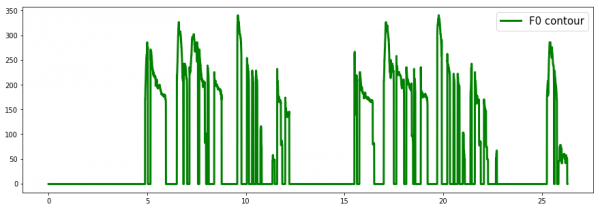
F0です。音程とみなすことができるので、こちらを会話の分析の際に使ってみるのが良いのだと思います。
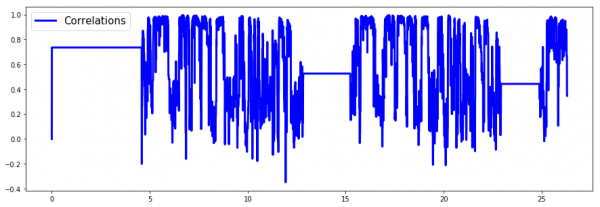
相関係数です。こちらもピッチ検出に使う指標のようです。
今後の使いみち
F0を集計してある水準のものが多い、時系列で見ると前半と後半でF0の水準が違っているというような情報と、その会話におけるラベル(会話の結果としての商談の成否)について分析することで、商談などがうまくいく際のヒントが得られるかもしれないですね。
追記
数十分の音声に関してF0を抽出しようとしたら、処理に非常に時間がかかり、結局最初の数分とかのF0の抽出にとどまりました。予感はしていましたが、結構計算リソースが必要な領域なのですね。
参考情報
IPythonデータサイエンスクックブック ―対話型コンピューティングと可視化のためのレシピ集
音声生成の基礎と音声学
Is there a way to convert audio files in Mac OS X or the command line without using iTunes?
やる夫で学ぶディジタル信号処理 東北大学 大学院情報科学研究科 鏡 慎吾
[vDSP][信号処理]オーディオ・音声分析への道7 FFT 自己相関関数 ピッチ検出
REAPER: Robust Epoch And Pitch EstimatoR
FFmpeg wiki:AudioChannelManipulation
基本周波数抽出器 REAPERによる抽出実験
SPTKの使い方 (3) ピッチ抽出