はじめに
これまで、データ分析・機械学習などの知識を重点的に学んできたので、BI周りはかなり疎かになっていました。今の知識のままではBI案件のお手伝いが大変だなと思ったので、少しはリソースを割いて勉強していこうと思います。今回はコードも何も出てこない内容なので、データサイエンティストの方はそっ閉じで良いと思います。
海外のブログで、“12 Best Business Intelligence Books To Get You Off the Ground With BI”という記事があり、”Performance Dashboards: Measuring, Monitoring, and Managing Your Business (English Edition)“という書籍が紹介されていました。それについてわかりやすくまとめられたスライドがあったので、2006年と古いですが、何もBIを知らないものとしては非常に勉強になると思い、訳して自分のための忘備録としておきます。

目次
・パフォーマンスダッシュボード
・ダッシュボードの不満
・パフォーマンスダッシュボードの2つの原則
・戦術的なドライバー
・戦略的なドライバー
・パフォーマンスダッシュボードは何で構成されるか
・おわりに
パフォーマンスダッシュボード
- ダッシュボード
- パフォーマンスチャート
からなる
ダッシュボードの不満
意思決定を阻害するもの
- データが多すぎる
- 情報が少なすぎる
- 届くのが遅すぎる
パフォーマンスダッシュボードの2つの原則
パフォーマンスダッシュボード = BI + 企業の経営マネジメント
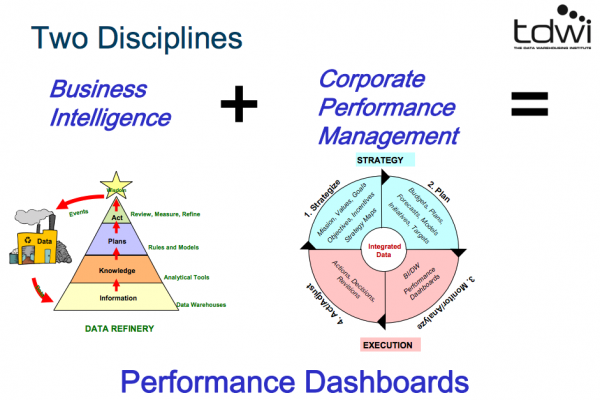
(画像はPDFより拝借しております。)
- 1.BI
- 情報(DWH)
- 知識(分析ツール)
- 計画(ルール、モデル)
- 行動(レビュー、計測、洗練)
- 知恵
- イベント発生→情報へ
の繰り返し
- 2.企業の経営マネジメント
- 戦略(ミッション、バリュー、ゴール、目的、インセンティブ、戦略マップ)
- 計画(予算、計画、見込み、モデル、イニシアティブ、ターゲット)
- モニタリング、分析(パフォーマンスダッシュボード)
- 行動、調整(行動、決定、見直し)
戦術的なドライバー
- 利用者と共鳴する
- 一つのスクリーンでいくつかの領域のステータスをモニタリングできる
- 重要な指標のグラフ表示
- 例外的な状況に関してアラートを上げる
- クリックして分析し、詳細を深掘りできる
- ルールに基づきカスタマイズされた表示
- 訓練が要求されない
- リッチなデータ
- 複数の情報ソースからブレンドされたデータ
- 詳細も集計値もある
- 履歴もリアルタイムのデータもある
- 労働者に力を与える
- 本当に重要なことにユーザーを集中させる
- 労働者の貢献がどのように集計されているかを示す
- ゴール、競争、インセンティブで動機づけをする
- プロアクティブな介入を促進する
戦略的なドライバー
- ビジネスを調整する
- 皆同じデータを使う
- 皆同じ指標を使う
- みな同じ戦略で働く
- コミュニケーションの改善
- コミュニケーション戦略のためのツール
- マネジャーとスタッフのコラボレーション
- 部門間のコーディネート
- 視認性とコンプライアンスの向上
- 驚きの少なさ
- 戦略的なドライバーの5つのC
- Communicate
- Compare
- Collaborate
- Coordinate
- Congratulate
パフォーマンスダッシュボードは何で構成されるか
- 3つのアプリケーション
- 情報の3つのレイヤー
- パフォーマンスダッシュボードの3つのタイプ
3つのアプリケーション
- モニタリング
- 分析
- コラボレーション
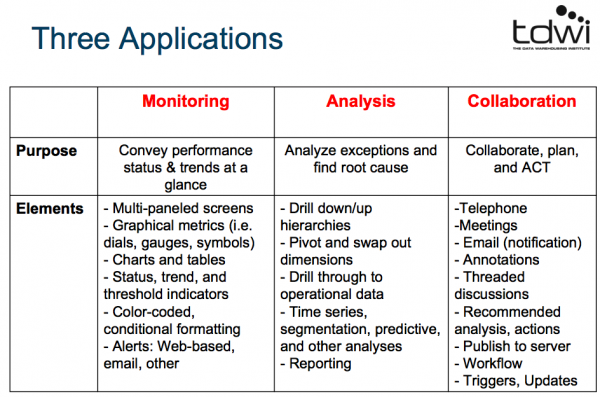
(画像はPDFより拝借しております。)
情報の3つのレイヤー
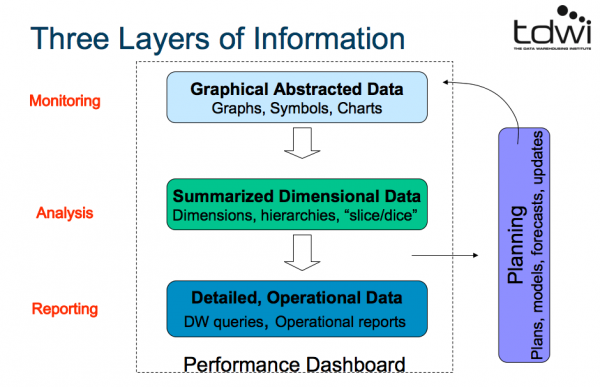
(画像はPDFより拝借しております。)
- モニタリング:グラフ、図形、チャート
- 分析:ディメンション、階層、細かく分割
- レポーティング:DWHのクエリ実行、運用レポート
- これらをプランニングする
・計画、モデル、予測、更新
ダッシュボード
・目的:現在の活動状況を測る
・ユーザー:経営者層、マネジャー、スタッフ
・更新頻度:即時
・データ:イベント
・クエリ:リモートシステムで実行
・画面:チャート
スコアカード
・目的:進行状況を示す
・ユーザー:経営者層、マネジャー、スタッフ
・更新頻度:周期的なスナップショット
・データ:サマリー
・クエリ:ローカル環境のデータマートで実行
・画面:図形
・経験則
・ビジネスユーザーが好むものは何でも使う!
パフォーマンスダッシュボードの3つのタイプ
- 業務系
- 焦点:モニタリング業務
- 重点:モニタリング
- ユーザー:管理者
- スコープ:現場
- 情報:詳細
- 更新頻度:日中
- 適しているのは:ダッシュボード
- 戦術系
- 焦点:プロセスの最適化
- 重点:分析
- ユーザー:マネジャー
- スコープ:部門
- 情報:詳細/サマリー
- 更新頻度:日次/週次
- 適しているのは:BIポータル
- 戦略系
- 焦点:戦略実行
- 重点:コラボレーション
- ユーザー:経営者層
- スコープ:企業
- 情報:サマリー
- 更新頻度:月次/四半期
- 適しているのは:スコアカード
パフォーマンスダッシュボードをどのように作るか?
3つのアーキテクチャー
・ビジネスアーキテクチャーとテクニカルアーキテクチャー
・BIアーキテクチャー
・データアーキテクチャー
ビジネスアーキテクチャー
- ステークホルダー:投資家、取締役、全従業員、顧客、サプライヤー、監督機関
- 戦略:ミッション、ビジョン、バリュー、ゴール、目的、戦略マップ
- 戦術:資産、人員、知識、計画、プロセス、プロジェクト
- 意味:用語、定義、ルール、メタデータ、教育、ガバナンス
- 指標:先行、遅行、兆候
テクニカルアーキテクチャー(パフォーマンスダッシュボードに直接つながるところ)
- ディスプレイ:ダッシュボード、BIポータル、スコアカード
- アプリケーション:モニタリング、分析、マネジメント
- データソース:スプレッドシート、メモリーキャッシュ、DWH、データマート、レポート、ドキュメント
- 統合:カスタムAPI、EAI(Enterprise Application Integration)、EII(Enterprise Information Integration)、クエリ実行、ETL、手動
- データソース:レガシーシステム、パッケージのアプリ、Webページ、ファイル、サーベイ、テキスト
BIアーキテクチャー
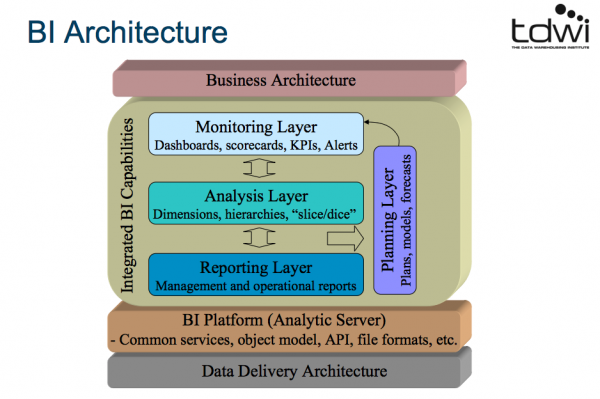
(画像はPDFより拝借しております。)
ビジネスアーキテクチャー
・統合BI能力
・モニタリングレイヤー
・分析レイヤー
・レポーティングレイヤー
・プランニングレイヤー
・BIプラットフォーム(分析サーバ)
・共通のサービス、モデル、API、ファイル形式
・データデリバリーアーキテクチャー
データアーキテクチャー
Quicken Loans(アメリカの金融業者)の例
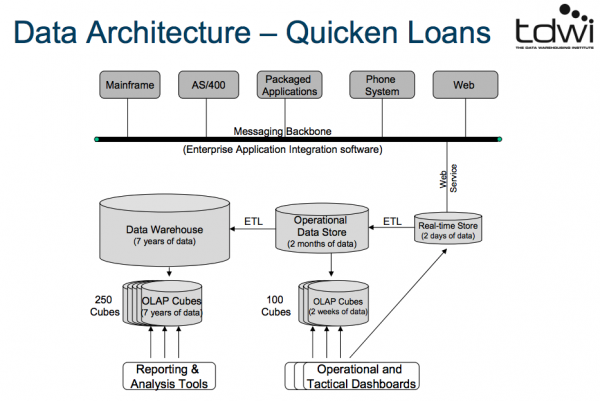
(画像はPDFより拝借しております。)
- 企業内のソフトウェアのデータを統合し、Web経由で2日分のデータを蓄積(Real-time Store)→業務系、戦術系のダッシュボードに利用
- Real-time Storeのデータを整形して、2ヶ月分のデータを蓄積(Operational Data Store)
- Operational Data Storeから2週間分のデータを蓄積したものを100件ほど保持する(OLAP(online analytical processing) Cubes)→業務系、戦術系のダッシュボードに利用
- Operational Data Storeのデータを整形して、7年分のデータを蓄積(Data Warehouse)
- Data Warehouseのから7年分のデータを蓄積したものを250件ほど保持する(OLAP Cubes)→レポーティングや分析ツールに利用
データアーキテクチャにはいろいろあるようです。
Direct Queryアーキテクチャー
スクリーンの要素が個々のクエリに直接的にリンクしている
- 良い点:
- すばやくデプロイできる
- 低コスト
- 悪い点:
- 浅く、ドリルダウンが制限される
- ディメンションがない
- ハードウェア組み込みクエリ
Query and Cacheアーキテクチャー
クエリがクエリ化可能なキャッシュとともに置かれている(In-memory or disk cache)
- 良い点:
- すばやくデプロイできる
- レスポンスが速い
- ナビゲーションが速い
- 悪い点:
- 静的なデータセットに縛られる
BIセマンティックレイヤー
BIツールがユーザーのためにビジネス用語で表現したクエリオブジェクトを提供
- 良い点:
- 抽象的なクエリオブジェクト
- ディメンションで分けられたビュー
- 悪い点:
- 一般的なODBCコネクション
- 主にDWHのヒストリカルデータ
Federated Queryアーキテクチャー
EII(Enterprise Information Integration)ツールが、スクリーンの要素と合うように複数のソースからクエリ化する
- 良い点:
- 複数のソース
- セマンティックレイヤー抽出
- デプロイが素早い
- プロトタイプ
- 悪い点:
- 履歴がない
- データの質の問題
- 複雑性
データマートアーキテクチャー
ダッシュボードがバッチで読み込まれた永続的なデータマートに対してクエリを実行する
- 良い点:
- 複数のソース
- ディメンショナルモデル
- ヒストリカルコンテキスト
- 素早く複雑なクエリ
- 悪い点:
- 即時性がない
- 統合されていない?
Event-drivenアーキテクチャー
- インプット:DWHや業務系システム
↓ - 業務系ダッシュボード:データの把握、データの集計、指標のマネジメント、イベントの検知、ルールの適用、作用/トリガー
↓ - アウトプット:アラート、トリガー(ワークフローエンジン)、SQL/Stored Procedures(業務系システム)
おわりに
BIダッシュボードを作成する際の洗い出しが面倒だと思っていたので、この資料で良い初期値を手に入れられました。これまでの分析業務はビジネスの一部を切り取って、疎結合なものを多く扱ってきたと思います。あるイベントの効果検証とか、ある対象の予測などです。この資料を読んで、組織の戦略などと密に絡み合い、様々な関係者の目的を成し遂げるようなBIダッシュボード作成において、組織間の調整力が強く求められるのかなと思いました。そこにデータサイエンティストの持つスキルはどうフィットするのだろうか?と思いつつ、どうやってサイエンス要素をバリューが出る形で盛り込んでやろうかと考えています。
参考情報
[1]Wayne W. Eckerson(2006). “Performance Dashboards:Measuring, Monitoring, and Managing Your Business”
[2]Sandra Durcevic(2019). “12 Best Business Intelligence Books To Get You Off the Ground With BI”, The datapine Blog