概要
2017年7月より当ブログにおいて、Google AnalyticsのカスタムディメンジョンにUser IDを取得して残せるようにしました。これにより、ユーザーの一人一人が閲覧した記事の分析を行うことが可能となっています。そこで今回は、記事の数も50近くなってきたことから、レコメンド手法の適用を行ってみたいと思います。Exampleデータでレコメンドをしても、ドメイン知識がないと、どれくらい良さそうな推薦なのかの判断が付きにくいと考えていたので、自分で運営しているサイトのデータであれば評価をつけやすいのではないかと思われます。
手法としてはNMF(non-Negative Matrix Factorization)を適用します。
【目次】
・前処理
・データ確認
・行列因子分解(Matrix Factorization)
・レコメンド結果の確認
・感想
・参考文献
前処理
ユーザー単位の閲覧した記事データを作るためにGAのAPIで取得したデータを整形し、集計します。このようなデータを手に入れるには自身のブログにおいて、GTM(Google Tag Maneger)を設置して、GTMのコンテナにカスタムJS変数などを格納する必要があります。詳しくはこちらのブログを参照ください。( 2016年の新定番!ユーザーエクスプローラーをもっと活用するための簡単な方法 )
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
#パッケージの読み込み library(RGA) library(tidyverse) #GAの認証 authorize() prof <-list_profiles() #取得期日の指定 start_date <- "2017-07-04" end_date <- "2017-09-16" #GAのAPIからデータ取得(ディメンションの数は7つまで) accesslogdata <- get_ga(profileId = prof$id[2], start.date = start_date, end.date = end_date, dimensions = "ga:pagePath, ga:dimension1, ga:dateHourMinute, ga:deviceCategory, ga:userType, ga:fullReferrer", sort = "-ga:sessions", metrics = "ga:sessions,ga:goal1Completions,ga:pageviews", fetch.by = "day") #記事のURLだけに絞り込む accesslogdata$pagePath <- vapply(strsplit(accesslogdata$pagePath,"\\?"), `[`, 1, FUN.VALUE=character(1)) accesslogdata <- accesslogdata %>% filter(grepl(x = pagePath,"/archives/[0-9]+$")) #ユーザーごとに重複した記事の情報を削除する df_dups <- accesslogdata[c("pagePath","dimension1")] accesslogdata <- accesslogdata[!duplicated(df_dups),] accesslogdata$pagePath <- gsub(accesslogdata$pagePath,pattern = "/archives/",replacement = "article_") articles <- unique(accesslogdata$pagePath) #記事ごとの閲覧有無に関するカラムを生成する for(i in 1:length(articles)){ accesslogdata <- accesslogdata %>% mutate(variable=if_else(pagePath==articles[i],1,0)) accesslogdata <- eval(parse(text=paste0("accesslogdata %>% rename( ",articles[i],"=variable)"))) } #クッキー単位で接触した記事ごとに集計する accesslogdata <- accesslogdata %>% select(-pagePath,-dateHourMinute,-deviceCategory,-userType,-fullReferrer,-sessions,-goal1Completions,-dateHour,-pageviews) %>% group_by(dimension1) %>% summarise_all(funs(sum)) |
このような形で行にユーザーが、列に記事が、各要素にアクセスの有無が入るようになっています。本来は評価データを用いますが、評価データがないので、アクセスしたかどうかの1-0データとして扱います。
データ確認
|
1 2 3 4 5 |
#ユーザーごとの接触ページ数を集計し、ヒストグラムで描く session <- data.frame(PageView=rowSums(accesslogdata[,-1])) ggplot(data = session, aes(x = PageView)) + geom_histogram(binwidth = 1) + ylab("User Count") + ggtitle("Article Page View Each Users") + theme(plot.title = element_text(hjust = 0.5)) |
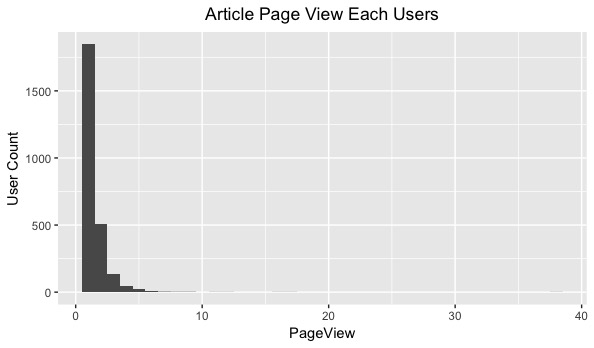
以下より、行列の要素のうち、値が入っている要素は全体の2.9%であることがわかります。参考文献は2.6%をスパースと言っていたことから、今回のデータもスパースであると考えることができます。
|
1 2 3 4 5 6 7 8 |
> X <- as(accesslogdata[,-1],"matrix") > table(X) X 0 1 122741 3777 > table(X)[2]/(table(X)[1]+table(X)[2]) 1 0.02985346 |
行列因子分解(Matrix Factorization)
行列因子分解はユーザーごとのアイテム購買履歴などのデータからなる行列の因子分解を行うもので、レコメンドにおいては因子分解の結果として、ゼロ以上の要素を持つ場合に推薦対象とするなどの活用がされています。非負値行列因子分解は要素が非負となるように制約を付けて行列を分解するもので、正の値を取ることから推薦に使いやすいとされています。
今回はNMFパッケージを用いて、ほぼデフォルトな設定で結果を眺めてみますが。本来であれば以下のような考慮が必要となります。最適化などをがっつり進めようとするとクロスバリデーションなどを行ったり、計算リソースが結構かかったりすると思われます。
- アルゴリズムの選択
- brunet,KL,lee,Frobenius,offset,nsNMF,ls-nmf,pe-nmf,siNMF,snmf/r,snmf/lがある。
- デフォルトではbrunetとなっている。
- シーディングメソッドの選択(初期値の決め方)
- 固定値(none),ランダム(random),ica,nndsvdがある。
- デフォルトではランダムとなっている。
- 実行回数の設定
- 100〜200回を選ぶことが多い。
- 並列処理
- 処理量が多いので最適化などを考えると並列処理も重要。
- 因子分解ランクの推定
- ランクの数が多いと残差は減るが、過学習になりやすい。クロスバリデーションを行う必要がある。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
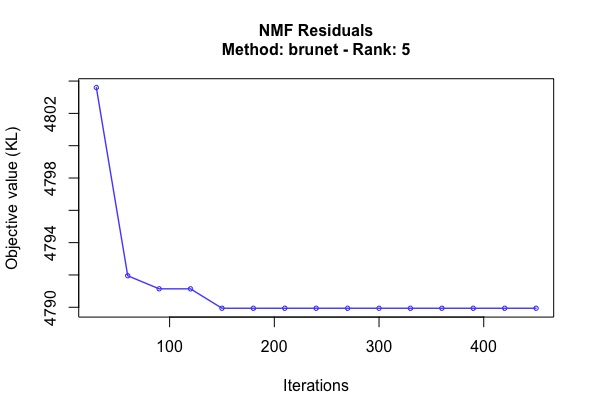
library(NMF) #NMFの実行(6次元以上の次元を削除) res <- nmf(accesslogdata[,-1], 5, seed = 1234, .options = "t") #試行回数と損失関数としてのカルバックライブラー情報量の可視化 plot(res) #基底行列の取得 w <- basis(res) #係数行列の取得 h <- coef(res) #レコメンデーション評価値を得る accesslogdata.nmf <- w %*% h #確認するユーザーの行番号 userid <- c(377,987,2584) #RAWデータとレコメンデーション結果の比較 recommend_result <- data.frame(round(t(accesslogdata.nmf[userid,]), 2), t(accesslogdata[userid,-1])) #記事タイトルの読み込み article_title <- read_csv(file = "article_titles.csv") recommend_result <- left_join(rownames_to_column(recommend_result), article_title, by = c("rowname" = "article_id")) %>% mutate(rowname=title) %>% select(-title) |
レコメンド結果の確認
各ユーザーに対して推薦されたアイテムのうち、比較的値の大きなものに関してコメントをしたいと思います。
ユーザー1
「XGBoostやパラメータチューニングの仕方に関する調査」を閲覧したユーザー1に対して、「XGBoostのパラメータチューニング実践 with Python」を推薦できている一方で、「OpenCV&Pythonで画像の類似度を計算させる〜イケメンの顔比較」など関係性の薄そうな記事も推薦してしまっています。
ユーザー2
「人工知能学会全国大会2017のWebマーケティングで参考になりそうな研究9選」を閲覧したユーザー2に対して、「Kaggleで使われた特徴量エンジニアリングとアルゴリズムまとめ」を推薦できている。
ユーザー3
「洋楽の歌詞データでDoc2vecを実行してみる」を閲覧したユーザー3に対して、「LDA(潜在的ディリクレ配分法)まとめ 手法の概要と試行まで」を推薦できている一方で、「ベイジアンネットワークをRのbnlearnパッケージで推定して予測してみる」と関係性の薄そうな記事も推薦している。本来、近いと思われる、「Word2Vecでクラシックの楽曲情報をコーパスとして類似度を出してみる」を推薦できていない。
感想
- 結果に関して、納得のいくものといかないもので半々な印象でデフォルトの設定では満足できない。
- NMFはクロスバリデーションなどにより過学習を避けた形での最適なランク数やアルゴリズムの選定、初期値の設定などが必要と思われるので、そこらへんの取り組みも今後行いたい。
- FM(Factorization Machine)は回帰項を追加できるので、今後挑戦してみたい。
- 1-0のデータではなく評価のデータが欲しい。
参考文献
岩波データサイエンス Vol.5
非負値行列因子分解(NMF)によるレコメンドのちょっとした例
An introduction to NMF package
非負ッ値行列・ファクトリゼーション ~ 半群じゃないから難しくないもん!