library(ggplot2)
# after estimation
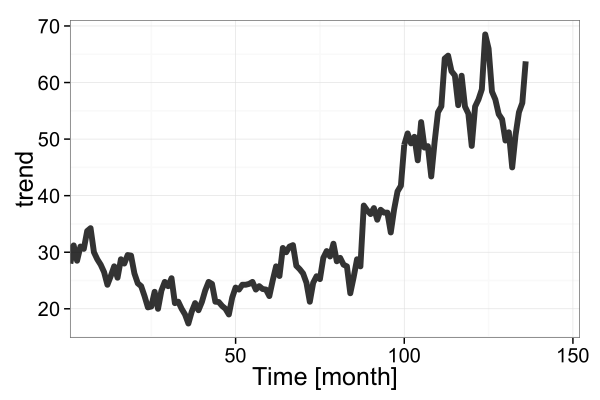
d_obs <- data.frame(X=1:T, Y=d$Y)
p <- ggplot()
p <- p + theme_bw() + theme(text=element_text(size=18))
p <- p + geom_line(data=d_obs, aes(x=X, y=Y), color='black', alpha=0.8, size=2)
p <- p + labs(x='Time [month]', y='trend')
p <- p + coord_cartesian(xlim=c(0.9, 152.1))
ggsave(file='fig2-top-left.png', plot=p, dpi=300, width=6, height=4)
makeDataFrameQuantile <- function(x, y_smp){
qua <- apply(y_smp, 2, quantile, prob=c(0.1, 0.25, 0.5, 0.75, 0.9))
d_est <- data.frame(X=x, t(qua))
colnames(d_est) <- c('X', 'p10', 'p25', 'p50', 'p75', 'p90')
return(d_est)
}
plotTimecourse <- function(file, d_est, d_obs){
p <- ggplot()
p <- p + theme_bw() + theme(text=element_text(size=18))
p <- p + geom_vline(xintercept=T, linetype='dashed')
p <- p + geom_ribbon(data=d_est, aes(x=X, ymin=p10, ymax=p90), fill='black', alpha=0.25)
p <- p + geom_ribbon(data=d_est, aes(x=X, ymin=p25, ymax=p75), fill='black', alpha=0.5)
p <- p + geom_line(data=d_est, aes(x=X, y=p10), color='black', size=0.2)
p <- p + geom_line(data=d_est, aes(x=X, y=p90), color='black', size=0.2)
p <- p + geom_line(data=d_est, aes(x=X, y=p25), color='black', size=0.2)
p <- p + geom_line(data=d_est, aes(x=X, y=p75), color='black', size=0.2)
p <- p + geom_line(data=d_est, aes(x=X, y=p50), color='black', size=0.4)
if (!is.null(d_obs)){
p <- p + geom_line(data=d_obs, aes(x=X, y=Y), color='black', size=2, alpha=0.9)
}
p <- p + labs(x='month', y='trend')
p <- p + coord_cartesian(xlim=c(0.9, 152.1))
ggsave(file=file, plot=p, dpi=300, width=6, height=4)
}
la <- rstan::extract(fit)
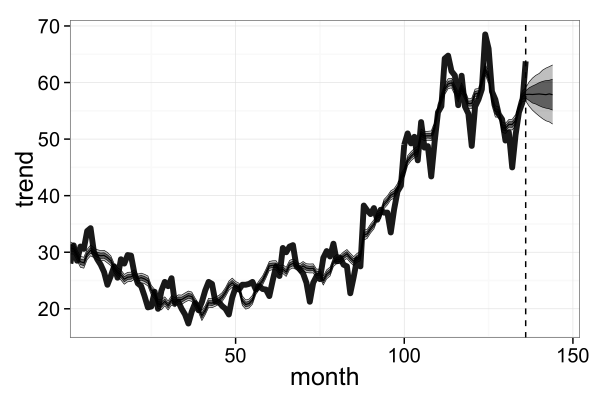
d_est <- makeDataFrameQuantile(x=1:(T+T_next), y_smp=la$mu_all)
plotTimecourse(file='fig2-bottom-left.png', d_est=d_est, d_obs=d_obs)
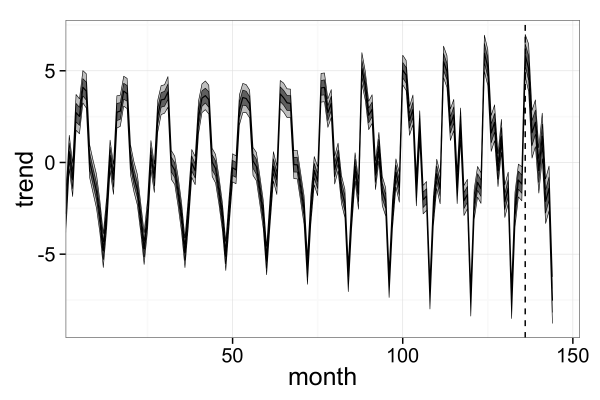
d_est <- makeDataFrameQuantile(x=1:(T+T_next), y_smp=la$s_all)
plotTimecourse(file='fig2-bottom-right.png', d_est=d_est, d_obs=NULL)
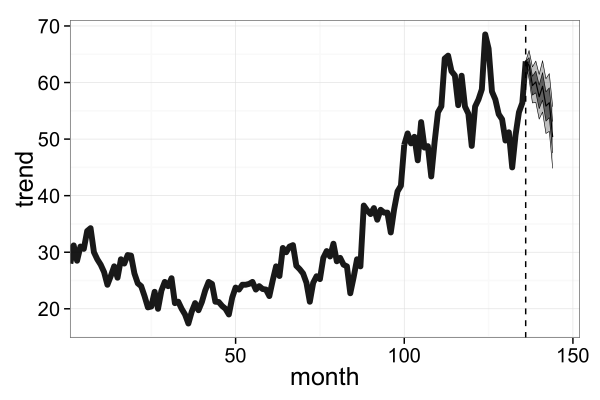
d_est <- makeDataFrameQuantile(x=(T+1):(T+T_next), y_smp=la$y_next)
d_est <- rbind(data.frame(X=T, p10=d$Y[T], p25=d$Y[T], p50=d$Y[T], p75=d$Y[T], p90=d$Y[T]), d_est)
plotTimecourse(file='fig2-top-right.png', d_est=d_est, d_obs=d_obs)