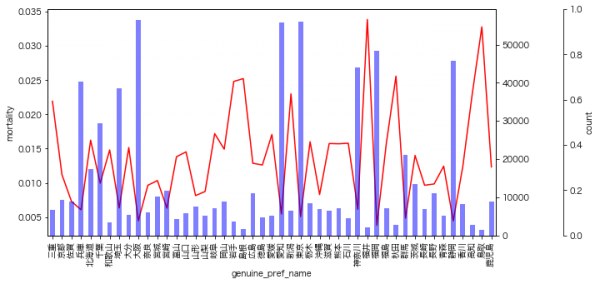
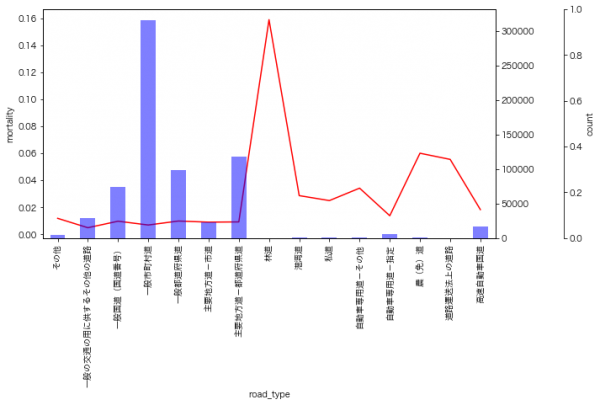
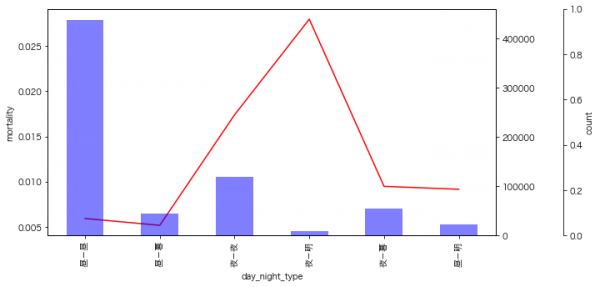
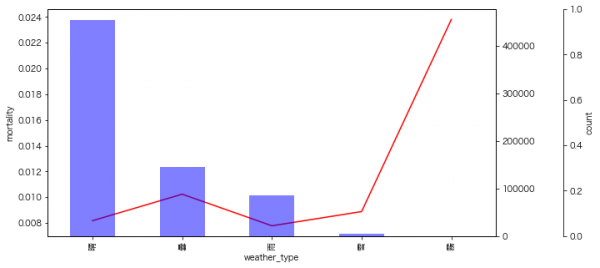
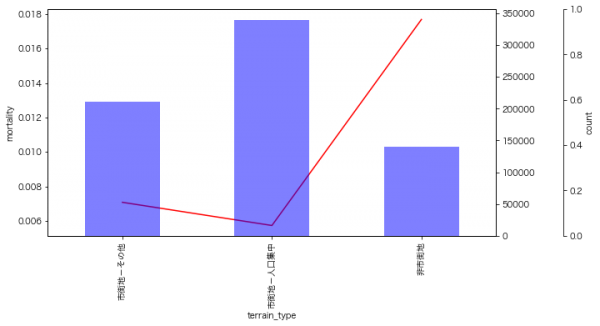
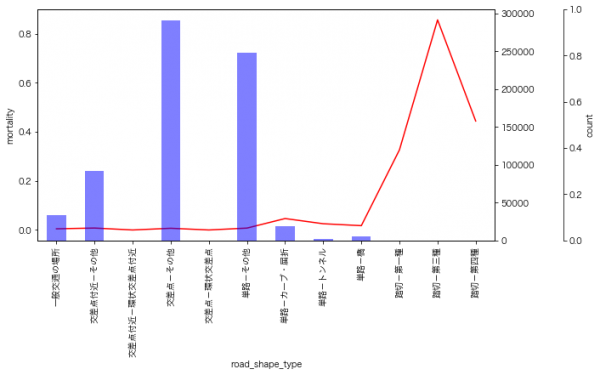
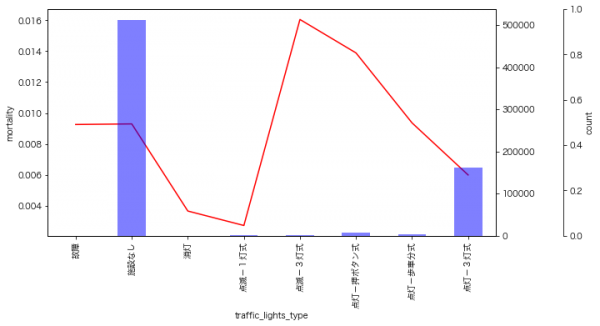
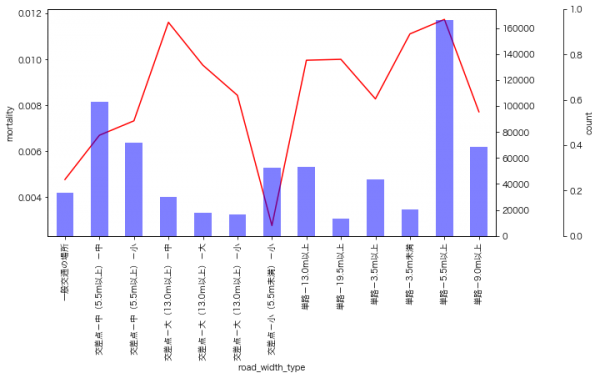
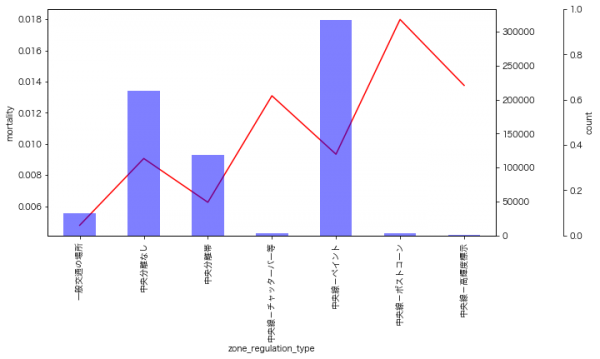
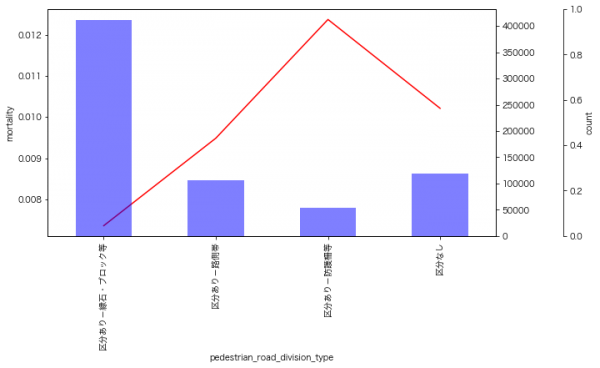
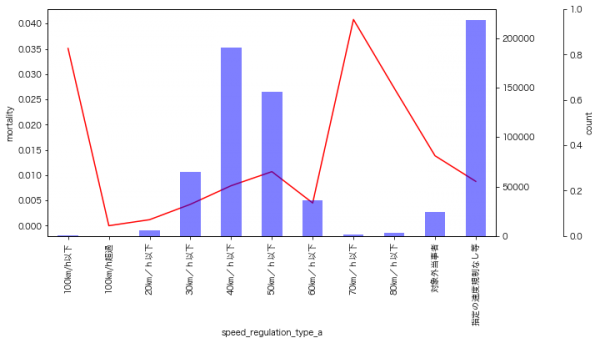
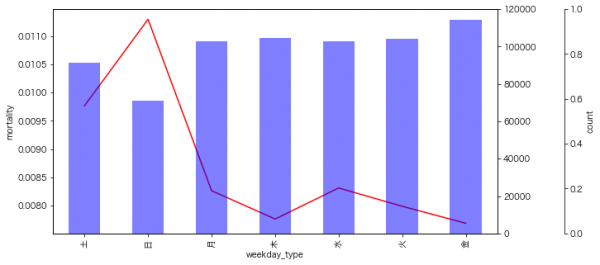
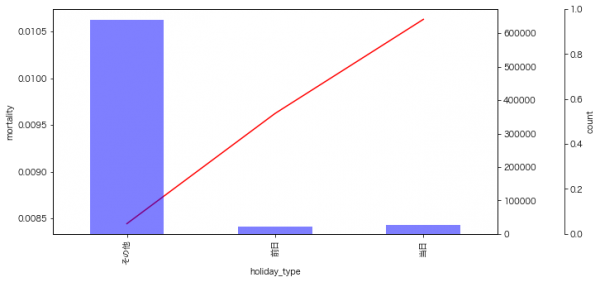
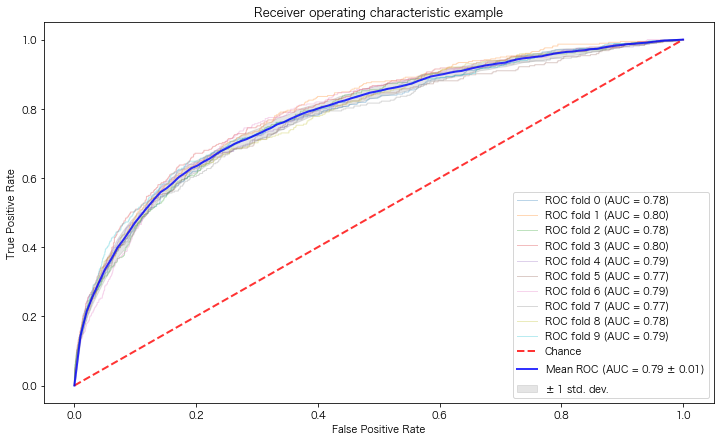
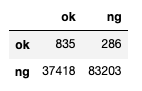
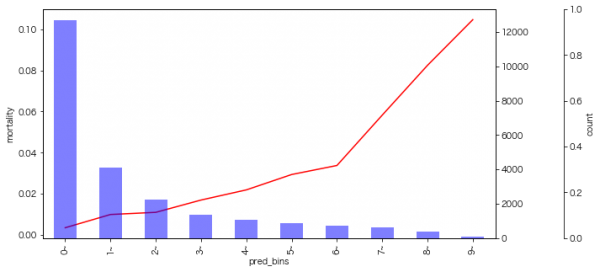
9月のイベントでジョブレコメンデーションについて調べて発表(実務と論文で学ぶ ジョブレコメンデーション最前線2022)しましたが、ブログの方が情報量が多いのと、最近のSlideShareが非常にみづらいものになっているのに加え、アップデートもしやすいのでこちらに随時残せる記事を残しておこうと思います。今日はクリスマスなので、誰かにとってはクリスマスプレゼントとなりうるでしょうか。
業界にいるものとしての思い
私は大学時代に経済学部に通っていたときに、労働市場の流動性に関して興味を持っていました。
スキルさえあればすぐに労働者が転職をするという競争的な労働市場について思い巡らすことがありました。
しかしながら、就職活動を通じて、取ってつけたような志望動機で大して勉強をしてこなかったであろう人々と同列に扱われ、「労働市場の効率性に関して、現実は不確実な情報のなかでエイヤで決めるしかないのかな」という印象を感じました。
就職活動では求人メディア系の会社に入社しました。スキルある人が高い給与を享受しやすい仕組み作りをデータ分析の力で実現できたらいいなと思って入りました。
ジョブマッチング界隈の課題
この業界の課題については推薦システム実践入門 ―仕事で使える導入ガイドの8章5節のドメインに応じた特徴と課題で、仕事の推薦について書かれているのも参考になりますので、そちらも合わせてお読みください。
- 双方の情報の充実化
- 情報の非対称性を払拭できるだけの情報がない中で企業も候補者も面接に臨んでいる
- 求人票の充実化
- 何かしらのエージェントを使う際に自分が本当に行きたい、行くべき職場がないかもしれない
- 求人票の質の向上
- 候補者が企業に直接応募するにしても、求人票に記されたレベル感が曖昧なため
ジョブマッチング界隈のデータの課題
- スキルや職歴の構造化データ化
- 正確なスキル情報の記載
- 所属した企業に関しても法人番号などを付与できるといい
- 求人情報の記載項目の誤り是正、更新性アップ
- 今は求めていない要件があるとか、扱う技術に変化があったとかを反映
- 希望する仕事内容や職場の要望のデータ化
- 希望する仕事について構造化データになっていない
ジョブマッチング系の論文色々
・Job Recommender Systems: A Review(2021)
・Domain Adaptation for Resume Classification Using Convolutional Neural Networks(2017)
・Implicit Skills Extraction Using Document Embedding and Its Use in Job Recommendation(2020)
・Machine Learned Resume-Job Matching Solution(2016)
・SKILL: A System for Skill Identification and Normalization(2015)
・Effectiveness of job title based embeddings on résumé to job ad recommendation(2021)
・conSultantBERT: Fine-tuned Siamese Sentence-BERT for Matching Jobs and Job Seekers(2021)
Job Recommender Systems: A Review(2021)
- 論文の概要
- Job Recommender System(JRS)研究のサーベイ論文(2011〜2021)[計133本]
- 近年は求人などの大量のテキストを用いたジョブレコメンデーションが多い。深層学習も使われている。BERTもCNNも使われている。ハイブリッドモデルが多い傾向。
- 近年ではアルゴリズムの公平性(年齢/性別での差別)に関心が持たれており、特徴量として差別的なものがなくても学習してしまう可能性が指摘されている。
- 求職者とリクルーターのインタラクティブなデータ(click/skip)の利活用が重要となっている。研究者はRecsysなどのコンペのデータに依存しており、企業がデータセットの提供をするのが限定的であるのが問題としてある。JRSの発展のためにはKaggleやRecsysのコンペが重要とされている。
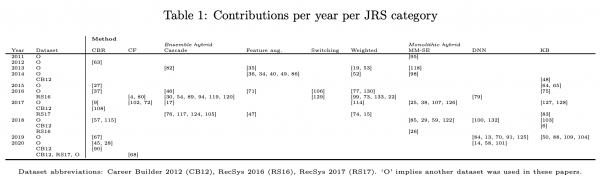
- 参考になるところ
- 求職者と採用担当者のインタラクティブなデータはこのコミュニティでデータとして貴重であること
- 最近はTransformer系のアプローチが使われ始めていること
Domain Adaptation for Resume Classification Using Convolutional Neural Networks(2017)
- 論文の概要
- 27の職種のラベルが付与された求人票のデータ(テキスト:短文)をもとにCNNで分類器を作成
- ラベルがない職務経歴データに関しては求人票で学習したモデルで推論
- fastTextでの分類よりも性能が向上した
- 求人票の数 > 越えれない壁 > 職務経歴データの数
- CNNで学習する際の特徴量は学習済みのWord2Vecによる単語の分散表現で、同じ長さのものを使っている。
- 最大値プーリングでの重要な特徴抽出、ドロップアウトの正則化など画像分類タスクと同様になされ、soft-max関数でマルチクラスの確率を出力している。
- 苦手な職種でのファインチューニングがfuture work


- 参考になるところ
- 職務経歴書と違って収集が容易な求人票のデータをもとに学習し、職務経歴に関するラベルを推論をするスタイル
- テキストデータに対してCNNを使っている
Implicit Skills Extraction Using Document Embedding and Its Use in Job Recommendation(2020)
- 論文の概要
- 職務経歴書や求人からNLPでスキル表現を抽出
- 暗黙的なスキル表現も抽出
- 候補者と求人のマッチングのスコア(Affinity Score)を定義
- 暗黙的スキル情報を使うとマッチングの性能がアップすることがわかった
- テキストに対して3つの観点でスキル抽出
・NER(Named Entity Recognition(固有表現抽出))を適用→文書内のスキルの位置を見つける、カテゴライズを行う
・PoS(Part of Speech(品詞の付与))を適用→スキル表現かどうかは専門家によるアノテーションを実施
・色々集めた辞書にあるか計算→Wikipedia、Onet/Hopeというサイトなどで自動での拡張型スキル辞書用意 - 暗黙的なスキル表現も抽出
暗黙スキル(Web DevelopmentやHard Workingなどの表現)の考慮→分散表現の平均値で表現 - スキルとの関連度スコアの定義
職務経歴書や求人からのスキル抽出のためにスコアを用いる - 表現の除外
関連度スコアに閾値を設けて下回ったらその表現を除外するなどを行う。 - 関連度スコア(x)
・NERで抽出した表現の信頼度(S1)
・文法が、事前に定義したルールにどれだけ合っているか(S2)
・そのスキルがNERで得たスキルっぽいもの、ポテンシャルスキル、辞書スキルの3つの辞書にどれだけ合致したかの割合(S3)
・その単語とスキル辞書との分散表現における最大のcos類似度の値(S4)
・パラメータは経験則的に決める
・関連スコアは0~1の間をとる - アフィニティスコア
・候補者と求人のマッチの適切さの指標
・エッジウェイトの平均としている - エッジウェイト(Y)
・スキル間のcos類似度(E1)
・文書を通じたスキルの出現頻度の割合(E2)
・明示的なスキルがあるかどうか(E3)→暗黙だと減点
・ウェイト(ω)はそのマッチングが成功したかどうかで重み付ける。
・関連スコアは0~1の間をとる
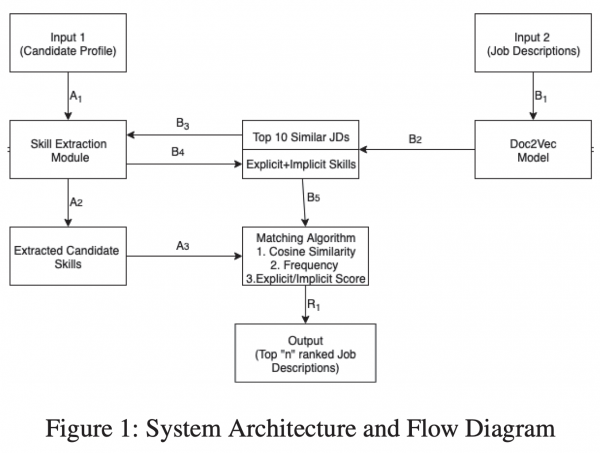
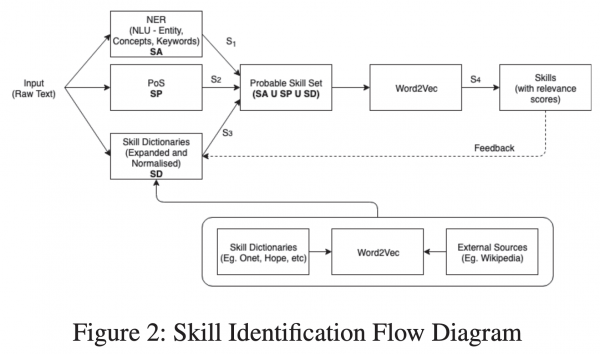
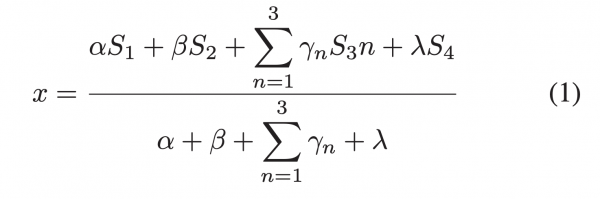
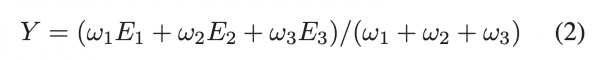
- 暗黙的なスキルに関して着目したところ
- スコアリングのモデルを定め、手元にあるデータとWikipediaなどの集合知も使ってかなり慎重にスキル抽出を行っている
Machine Learned Resume-Job Matching Solution(2016)
- 論文の概要
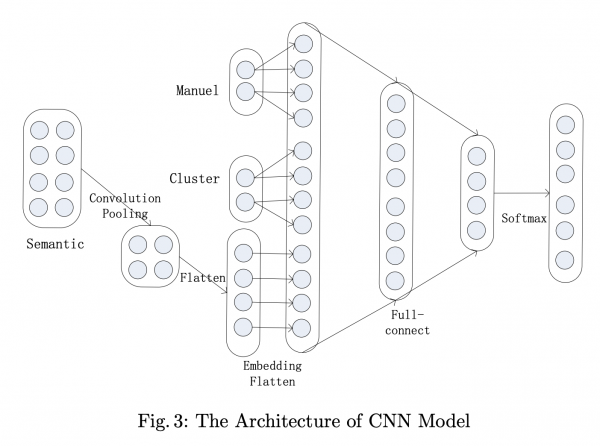
- 深層学習(CNN)を用いて、リッチな特徴量を用意した上で、職務経歴書と求人のマッチング最適化を行っている
- 職務経歴書の数は4.7万枚
- KerasやScikit-learnで書かれており軽量
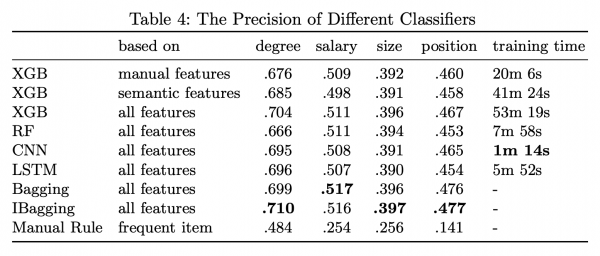
- 浅いモデルとしてXGBoostを、深いモデルとしてCNNの両方を、最終的に多数決によるアンサンブルにすることで性能が向上
- アンサンブル手法としてはバギングを行っている
- リッチな特徴量
・Manual Feature(年齢とか性別とか)
・Cluster Feasture(クラスタリングしたもの、トピック(LDA))
・Semantic Feature(意味的な類似度) - モデルはGPUでもCPUでも動く
- ソースコードはGitHubで公開されてる
- 参考になるところ
- CNNながらGPUなしでも計算できるようなモデルのアーキテクチャになっている
- 特徴量はマニュアルで作成したものと自動で抽出したものの両方をうまく使う
SKILL: A System for Skill Identification and Normalization(2015)
- 論文の概要
- 職務経歴書や求人に記されているスキルの抽出に関するNER(Named Entity Recognition:固有表現抽出)の研究
- 老舗の求人サイトであるCareerBuilderの
社員による研究 - Wikipediaベースのカテゴリ分類、Google検索による集合知を利用してスキル表現の抽出をしている
- Word2Vecを用いて、あるスキルと関連しているスキルをもとにタグ付をするアプローチが紹介されている
- データ
大量の職務経歴書と求人票 - アプローチ
・スキル分類→wikipediaベースのAPI、国の定めた定義など
・スキル判定→単一語(そのまま利用)、複数語(Google検索結果から判断(集合知))
・スキルタグ付け→Word2Vecをユニグラムで学習し、関連度を計算しスキルのタグ付け
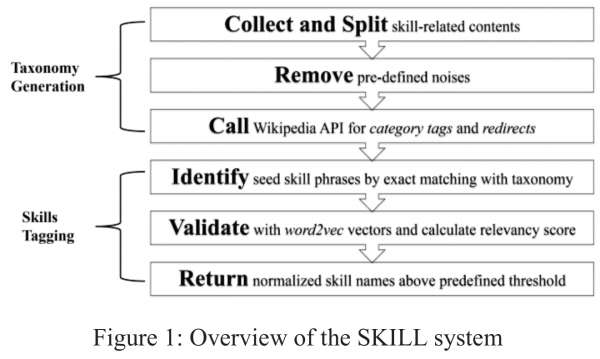
- 参考になるところ
- Google検索を使って得た集合知をスキルの分類に活かしている
- Word2vecで計算した類似度をもとにスキルのタグ付けをしている
Effectiveness of job title based embeddings on résumé to job ad recommendation(2021)
- 論文の概要
- 求人票の表現に対して、分散表現を用いた求人レコメンドの研究
- 求人票全体を使うよりも、タイトル部分を使ったほうがレコメンドの性能が高くなった
・分散表現はWord2VecやDoc2Vecの学習済みや学習したものを色々試している
・Cold-Start問題に対しても分散表現は有効な手段であるとしている
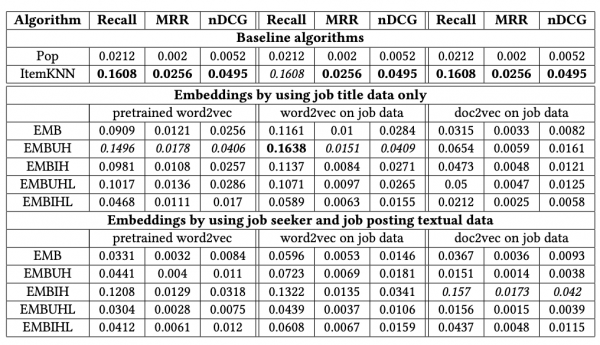
- 参考になるところ
- 汚い本文のテキストを使うよりもタイトルを使ったほうが良いと言う、岡目八目というか、労せずに成果を出す作法を知れたという気持ち
- 分散表現がCold-Start問題に対する有効な手段という可能性
conSultantBERT: Fine-tuned Siamese Sentence-BERT for Matching Jobs and Job Seekers(2021)
- 論文の概要
- データは27万件で正例が12.6万件、負例が10.9万件で職務経歴書(ユニークだと15万件)と求人票(2.3万件)からなる。ラベルはキャリアアドバイザーが付けたもの。
- 各センテンスに対してBERTを適用し、文書単位で平均を取るなどしている。文書は最初の512トークンを使うのがよいとしている。
- BERTを分類問題・回帰問題についてそれぞれSiamese network(シャムネットワーク)を用いてファインチューニング
・出力層は求職者のレジュメと求人票のCOS類似度をマッチングスコアとしている
・埋め込み層のデータで教師あり学習をランダムフォレストで行い、COS類似度ではなくランダムフォレストの吐いたスコアを使って推論するバージョンも用意している - 回帰タスクでのファインチューニングが一番よかった
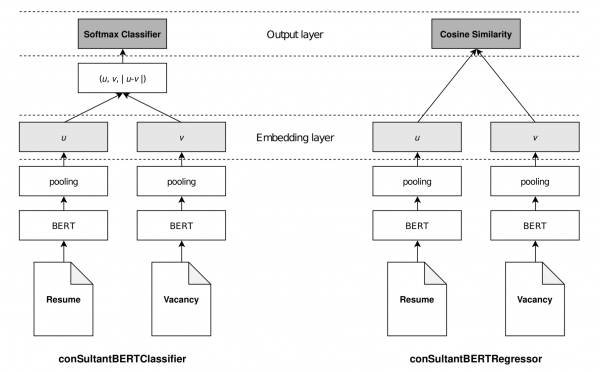
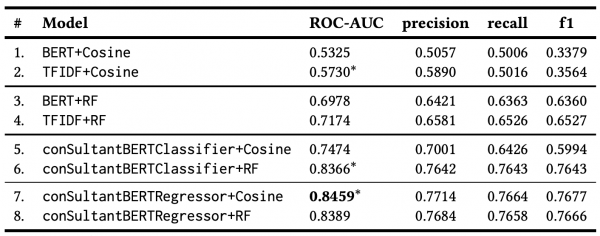
- 参考になるところ
- BERTをセンテンスに対して使って、平均値をとりそれを特徴量にしている
- 全文を使わないほうが分類性能が良い可能性
- 埋め込み層のデータで教師あり学習をして、それのスコアを用いるというアプローチ