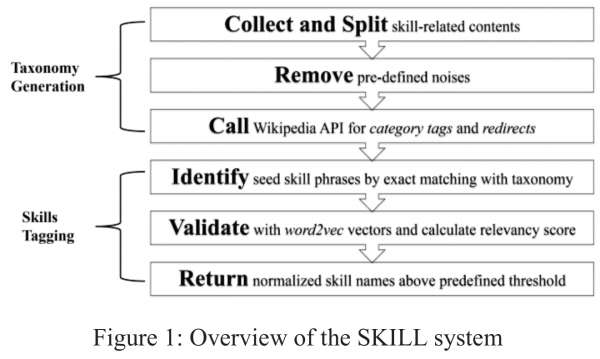
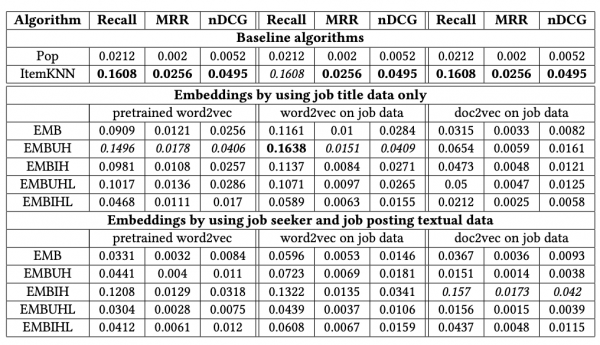
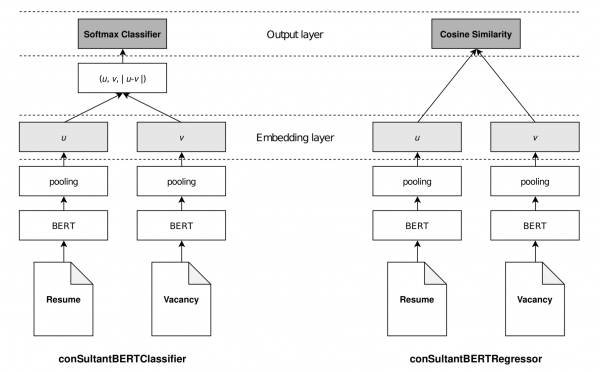
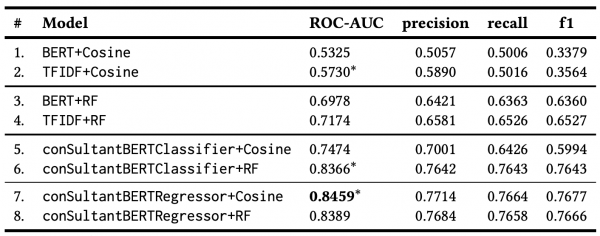
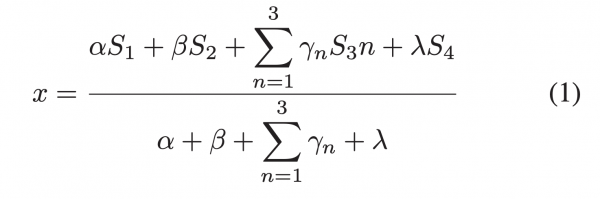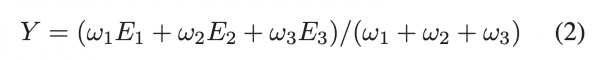はじめに
エンジニアが作ったシステムの中で、データサイエンティストが開発する際に、オブジェクト指向プログラミングで書かれたソースコードに直面し、戸惑うかたも一定数いると思います。実際に私もその一人です。まだ完全に理解ができて、オブジェクト指向プログラミングができているわけではないですが、この記事を書くことを通じてより理解を深めていきたいと思います。
今回お世話になる本はこちら(『オブジェクト指向でなぜつくるのか 第3版 知っておきたいOOP、設計、アジャイル開発の基礎知識』)です。

この本を読んで、みなさん大好きなscikit-learnのソースコードを眺めてみようと思います。
オブジェクト指向とは
オブジェクト指向とは、ソフトウェアの保守や再利用をしやすくする技術のことを指しています。
個々のパーツに着目し、パーツの独立性を高め、それらを組み上げてシステム全体の機能を実現するという考え方に基づいています。
オブジェクト指向プログラミングのキーワード
参考にしている本によると、オブジェクト指向を理解する上での重大なキーワードとして以下の三つがあげられるようです。
・クラス
・ポリモーフィズム
・継承
クラス
クラスは同種のものの集まりを、インスタンスは具体的なモノを意味します。数学の集合論で言うところの集合、インスタンスは要素と例えられます。
なお、インスタンスはクラスに属するので、クラスをまたぐことはできません。
クラスの役割
【サブルーチンと変数(インスタンス変数)をまとめる】
メソッドの名前に関して違う名前をいちいち付けなくても済むようになる。
.fit_logistic_regression、.predict_random_forest_regressionみたいな表現ではなく、.fitとか.predictだけで済むようにできます。
【クラスの内部だけで使う変数やサブルーチン(メソッド)を隠したり公開する】
変数をいろんなところで使えてしまうと、思いがけない挙動で困ることがあったり不具合の原因を特定することが困難になります。クラス内のメソッドにアクセスできる変数を限定することでそれを実現します。グローバル変数はプログラムの保守性悪化の元凶となるため避けることが推奨されています。また、変数はプライベート変数だとして、クラスやメソッド自体を様々なところから呼び出し可能にして書くことも可能です。
【1つのクラスからインスタンスをたくさん作る】
同時に様々な処理対象に対して、処理を行いたい場合は、クラスから複数のインスタンスを生成することでそれが実現できます。
標準化のためのfit、教師あり機械学習モデルのfit、教師なし機械学習のためのfitなどクラスを複数複製してシンプルな書き方でそれらを実現することができます。
ここで作られたインスタンス変数は、どこからでもアクセスできるわけではないという観点でグローバル変数とは異なり、特定のメソッド内でしか使えないわけではないという観点でローカル変数とも異なります。
ポリモーフィズム
類似したクラスに対するメソッドについて、共通にする仕組みのことをポリモーフィズムと呼びます。単語自体の訳としては「いろいろな形に変わる」という意味です。メソッドを使う側が楽をできる仕組みとされます。
共通したメソッドを定める仕組みと理解してよさそうです。
なお、ポリモーフィズムを利用するには呼び出されるメソッドの引数や戻り値の形式を統一する必要があります。
また、入力がファイルだろうとネットワークだろうと問題なく動くように作る必要もあります。
継承
クラスの共通点と相違点を体系的に整理する仕組みのことで、全体の集合をスーパークラス、部分集合をサブクラスと呼びます。
集合の話で言うと、
動物はスーパークラス
哺乳類、爬虫類、鳥類、魚類、両生類、昆虫類などはサブクラス
という理解でよいです。
共通の性質をスーパークラスに定義しておくと、サブクラスを楽に作成することができます。
変数とメソッドをまとめた共通クラスを作り、別のクラスから丸ごとそれを拝借することで開発が楽になります。つまり、コードの重複を避けることができます。
当然ながら、サブクラスはスーパークラスでのメソッドと同じ使い方になるように引数や返り値の型をスーパークラスのそれに合わせる必要があります。
scikit-learnのGitHubを眺めてオブジェクト指向の観点で見てみる
さて、オブジェクト指向で重要な概念を知ったところで、実際にscikit-learnのソースコードでそれらの概念を表しているものを眺めることでより一層の理解が深まると思います。
そこで、https://github.com/scikit-learn/scikit-learnを眺めてみることとします。
教師なし学習ではK-meansのソースコードとDBSCANについて見てみます。
sklearn/cluster/_kmeans.py
sklearn/cluster/_dbscan.py
教師あり学習ではrandom forestとbaggingについて見てみます。
sklearn/ensemble/_forest.py
sklearn/ensemble/_bagging.py
ソースコードの所感としては、手法に応じて関数(def)の記述がなされ、その後にクラス(class)の定義がなされています。手法ごとに異なるアルゴリズムの部分をこの関数部分で書き、クラス部分のメソッドに関して手法ごとでも共通になるようにしているのかなと思いました。クラスのメソッドの中に複雑な関数を書くよりかは、クラスの外に書いておこうということなのでしょうか。
まずはK-meansのソースコードを見てみます。GitHubのリンクはsklearn/cluster/_kmeans.pyです。
|
|
class KMeans( _ClassNamePrefixFeaturesOutMixin, TransformerMixin, ClusterMixin, BaseEstimator ): |
base.pyというファイルから以下のクラスを呼び出しており、クラスがクラスを呼び出している構図になっています。
|
|
_ClassNamePrefixFeaturesOutMixin:特徴量の名前を取得するためのもの TransformerMixin:データの変換のためのもの ClusterMixin:クラスタリングでラベルを返すためのもの BaseEstimator:あらゆる推定におけるベースとなるもの |
この中ではBaseEstimatorが最もメソッドの数が多く、推定量のパラメータを得たり設定したり、特徴量の数を確認したりいろいろできるようです。
_get_param_names、get_params、set_params、__repr__、__getstate__、__setstate__、_more_tags、_get_tags、_check_n_features、_validate_data、_repr_html_、_repr_html_inner、_repr_mimebundle_
確かに、これだけのメソッドをいちいち各手法ごとに書くのは骨が折れるので、クラスからクラスを呼び出すのはリーズナブルだなぁと思いました。
さて、class KMeansの話に戻ります。メソッドとしては以下のものがあるようです。
__init__、_check_params、_validate_center_shape、_check_test_data、_check_mkl_vcomp、_init_centroids、fit、fit_predict、fit_transform、transform、_transform、predict、score、_more_tags
続いて、MiniBatchKMeansというクラスが現れますが、これは先ほど定義したKMeansを呼び出して使うため、base系のクラス→Kmeansクラス→MiniBatchKMeansクラスとより深い階層となります。
|
|
class MiniBatchKMeans(KMeans): |
このMiniBatchKMeansクラスでのメソッドは以下の通りですが、KMeansクラスを呼び出していることから、MiniBatchKMeansクラスかつKMeansクラスのメソッドが扱えるようになっています。
__init__、_check_params、_mini_batch_convergence、_random_reassign、fit、partial_fit、predict、_more_tags
|
|
from sklearn.cluster import MiniBatchKMeans >>> dir(MiniBatchKMeans()) ['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_check_mkl_vcomp', '_check_n_features', '_check_params', '_check_test_data', '_estimator_type', '_get_param_names', '_get_tags', '_init_centroids', '_labels_inertia_minibatch', '_more_tags', '_repr_html_', '_repr_html_inner', '_repr_mimebundle_', '_transform', '_validate_center_shape', '_validate_data', 'algorithm', 'batch_size', 'compute_labels', 'copy_x', 'counts_', 'fit', 'fit_predict', 'fit_transform', 'get_params', 'init', 'init_size', 'init_size_', 'max_iter', 'max_no_improvement', 'n_clusters', 'n_init', 'n_jobs', 'partial_fit', 'precompute_distances', 'predict', 'random_state', 'random_state_', 'reassignment_ratio', 'score', 'set_params', 'tol', 'transform', 'verbose'] |
続いて、DBSCANのソースコードを見てみます。GitHubのリンクはsklearn/cluster/_dbscan.pyです。
|
|
class DBSCAN(ClusterMixin, BaseEstimator): |
ClusterMixinクラスとBaseEstimatorクラスを呼び出していますが、先ほど登場したので紹介はしません。
DBSCANクラスのメソッドとしては、__init__、fit、fit_predictがあります。
|
|
from sklearn.cluster import DBSCAN dir(DBSCAN()) >>> dir(DBSCAN()) ['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_check_n_features', '_estimator_type', '_get_param_names', '_get_tags', '_more_tags', '_repr_html_', '_repr_html_inner', '_repr_mimebundle_', '_validate_data', 'algorithm', 'eps', 'fit', 'fit_predict', 'get_params', 'leaf_size', 'metric', 'metric_params', 'min_samples', 'n_jobs', 'p', 'set_params'] |
読み込んだクラスからメソッドを引き継いていることがわかります。
続いて、random forestを見てみます。GitHubのリンクはsklearn/ensemble/_forest.pyです。
|
|
class BaseForest(MultiOutputMixin, BaseEnsemble, metaclass=ABCMeta): |
これまでのクラスと同様にbase.pyやクラスを呼び出しています。一方で、BaseEnsembleはensemble/_base.pyのクラスとなっています。
|
|
MultiOutputMixin:複数のアウトプットに関するもの BaseEnsemble:アンサンブル手法のためのクラス metaclass=ABCMeta:クラスの構造を決めるもの |
|
|
class BaseEnsemble(MetaEstimatorMixin, BaseEstimator, metaclass=ABCMeta): |
さて、BaseForestのメソッドですが、
__init__、apply、decision_path、fit、_set_oob_score_and_attributes、_compute_oob_predictions、_validate_y_class_weight、_validate_X_predict、feature_importances_、n_features_となっております。
以下、ForestClassifierとForestRegressorについて記しますが、教師なしのクラスと同じように、base系のクラス→BaseEnsembleクラス→BaseForestクラス→ForestClassifierクラスと深い階層になっているのがわかります。
|
|
class ForestClassifier(ClassifierMixin, BaseForest, metaclass=ABCMeta): class ForestRegressor(RegressorMixin, BaseForest, metaclass=ABCMeta): |
なお、ForestClassifierクラスのメソッドは以下の通りです。
__init__、_get_oob_predictions、_set_oob_score_and_attributes、_validate_y_class_weight、predict、predict_proba、predict_log_proba、_more_tags
ForestRegressorクラスのメソッドは以下の通りです。
__init__、predict、_get_oob_predictions、_set_oob_score_and_attributes、_compute_partial_dependence_recursion、_more_tags
これで終わりかと思いきや、
|
|
class RandomForestClassifier(ForestClassifier): class RandomForestRegressor(ForestRegressor): class ExtraTreesClassifier(ForestClassifier): class ExtraTreesRegressor(ForestRegressor): |
などのクラスがありました。これまでのクラスを引き継ぎ、__init__の部分で手法の細かいところを変更しているようです。我々がscikit-learnで呼び出しているのはこれですね。
最後にRandomTreesEmbeddingクラスがありました。教師なしで、スパースな行列を変換するためのもののようです。
|
|
class RandomTreesEmbedding(BaseForest): |
メソッドとしては、__init__、_set_oob_score_and_attributes、fit、fit_transform、transformがあります。
当然ではありますが、教師ありのクラスのものとメソッドが違っているのがわかりますね。
最後に、baggingを見てみます。GitHubはsklearn/ensemble/_bagging.pyです。
|
|
class BaseBagging(BaseEnsemble, metaclass=ABCMeta): |
RandomForestのものと同様に、BaseEnsembleクラスやABCMetaを呼び出していることがわかります。
メソッドとしては以下の通りです。
__init__、fit、_parallel_args、_fit、_set_oob_score、_validate_y、_get_estimators_indices、estimators_samples_、n_features_
いよいよくどくなってきましたが、BaggingClassifierクラスで、これはこれまでのBaseBaggingを引き継ぎます。
|
|
class BaggingClassifier(ClassifierMixin, BaseBagging): |
メソッドとしては、__init__、_validate_estimator、_set_oob_score、_validate_y、predict、predict_proba、predict_log_proba、decision_functionがあります。
最後はBaggingRegressorです。これもbase系のクラス→BaseEnsembleクラス→BaseBaggingクラスと深い階層となっています。
|
|
class BaggingRegressor(RegressorMixin, BaseBagging): |
BaggingRegressorクラスのメソッドは__init__、predict、_validate_estimator、_set_oob_scoreです。
ここで定義されるメソッドは少ないですが、実際に呼び出してみるとクラスを引き継ぐことで多くのメソッドを使えるようになっていることがわかります。
|
|
from sklearn.ensemble import BaggingRegressor >>> dir(BaggingRegressor()) ['__abstractmethods__', '__annotations__', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_abc_impl', '_check_n_features', '_estimator_type', '_fit', '_get_estimators_indices', '_get_param_names', '_get_tags', '_make_estimator', '_more_tags', '_parallel_args', '_repr_html_', '_repr_html_inner', '_repr_mimebundle_', '_required_parameters', '_set_oob_score', '_validate_data', '_validate_estimator', '_validate_y', 'base_estimator', 'bootstrap', 'bootstrap_features', 'estimator_params', 'estimators_samples_', 'fit', 'get_params', 'max_features', 'max_samples', 'n_estimators', 'n_jobs', 'oob_score', 'predict', 'random_state', 'score', 'set_params', 'verbose', 'warm_start'] |
以上から、scikit-learnにおいては、オブジェクト指向プログラミングが実践され、クラスを引き継ぐことで書くべきソースコードの量をできるだけ抑えながら多種多様なアルゴリズムが開発されているのだなと実感することができました。
おわりに
今回、オブジェクト指向プログラミングを少し学び、それがscikit-learnでどのように反映されているのかを確かめましたが、なかなか深い階層でクラスを呼び出しているものがあると思いました。理解をすればプログラミングは楽になりますが、初手で構造をしっかり理解しないと階層の深さに戸惑ってしまいますね。
これが機械学習とかではなく、Web開発のコードとかだともっと深かったりするのでしょう。
参考情報
オブジェクト指向でなぜつくるのか 第3版 知っておきたいOOP、設計、アジャイル開発の基礎知識
Get the Most out of scikit-learn with Object-Oriented Programming
Pythonの抽象クラス(ABCmeta)を詳しく説明したい